我正在进行有关在MacOS上使用以下i7处理器的向量化基准测试:
但是正如您所看到的,我仍然获得了2倍而不是4倍的加速比。
我不明白为什么使用SSE和AVX向量化时我得到相同的加速比。
这是我为所有以上结果完成的编译命令行:
对于SSE:
此外,使用我的处理器模型,我能使用AVX512向量化吗?(一旦解决了这个问题)。感谢您的帮助。
更新1
我尝试了@Mischa的不同选项,但仍然无法通过AVX标志和选项获得4倍的加速。您可以查看我的C源代码http://example.com/test_vectorization/main_benchmark.c.txt(带有.txt扩展名可直接在浏览器中查看),用于基准测试的shell脚本为http://example.com/test_vectorization/run_benchmark。
如@Mischa所说,我尝试应用以下编译命令行: $GCC -O3 -Wa,-q -mavx -fprefetch-loop-arrays main_benchmark.c -o vectorizedExe 但生成的代码没有AVX指令。
如果您能够查看这些文件,那就太好了。谢谢。
$ sysctl -n machdep.cpu.brand_string
Intel(R) Core(TM) i7-4960HQ CPU @ 2.60GHz
我的 MacBook Pro 是中 2014 年的。
我尝试使用不同的标志选项进行矢量化:我感兴趣的有三个,分别是 SSE、AVX 和 AVX2。
对于我的基准测试,我将两个数组的每个元素相加,并将总和存储在第三个数组中。
我必须提醒您,我正在使用 double 类型来处理这些数组。
以下是我基准代码中使用的函数:
1*) 首先是 SSE 矢量化:
#ifdef SSE
#include <x86intrin.h>
#define ALIGN 16
void addition_tab(int size, double *a, double *b, double *c)
{
int i;
// Main loop
for (i=size-1; i>=0; i-=2)
{
// Intrinsic SSE syntax
const __m128d x = _mm_load_pd(a); // Load two x elements
const __m128d y = _mm_load_pd(b); // Load two y elements
const __m128d sum = _mm_add_pd(x, y); // Compute two sum elements
_mm_store_pd(c, sum); // Store two sum elements
// Increment pointers by 2 since SSE vectorizes on 128 bits = 16 bytes = 2*sizeof(double)
a += 2;
b += 2;
c += 2;
}
}
#endif
2*) 使用AVX256向量化的第二种方法:
#ifdef AVX256
#include <immintrin.h>
#define ALIGN 32
void addition_tab(int size, double *a, double *b, double *c)
{
int i;
// Main loop
for (i=size-1; i>=0; i-=4)
{
// Intrinsic AVX syntax
const __m256d x = _mm256_load_pd(a); // Load two x elements
const __m256d y = _mm256_load_pd(b); // Load two y elements
const __m256d sum = _mm256_add_pd(x, y); // Compute two sum elements
_mm256_store_pd(c, sum); // Store two sum elements
// Increment pointers by 4 since AVX256 vectorizes on 256 bits = 32 bytes = 4*sizeof(double)
a += 4;
b += 4;
c += 4;
}
}
#endif
对于SSE向量化,我预计速度提升大约为2倍,因为我将数据对齐在128位= 16字节= 2 * sizeof(double)上。
以下图表表示了我在SSE向量化方面得到的结果:
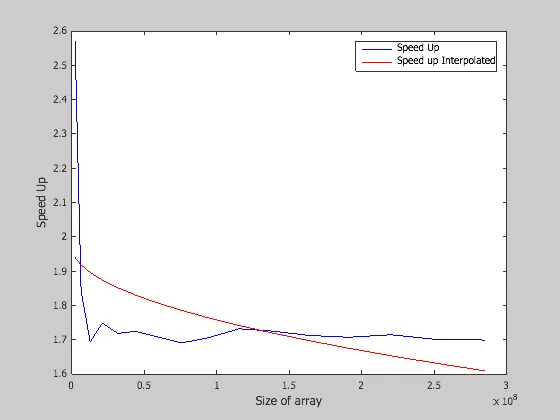
所以,我认为这些结果是有效的,因为SpeedUp大约是2。
现在对于AVX256,我得到了以下图表:
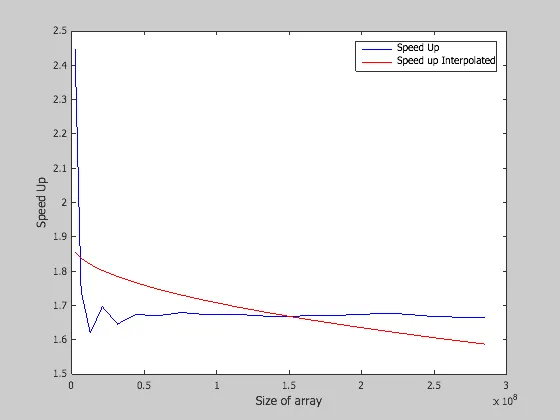
但是正如您所看到的,我仍然获得了2倍而不是4倍的加速比。
我不明白为什么使用SSE和AVX向量化时我得到相同的加速比。
这是我为所有以上结果完成的编译命令行:
对于SSE:
gcc-mp-4.9 -DSSE -O3 -msse main_benchmark.c -o vectorizedExe
对于 AVX256:
gcc-mp-4.9 -DAVX256 -O3 -Wa,-q -mavx main_benchmark.c -o vectorizedExe
此外,使用我的处理器模型,我能使用AVX512向量化吗?(一旦解决了这个问题)。感谢您的帮助。
更新1
我尝试了@Mischa的不同选项,但仍然无法通过AVX标志和选项获得4倍的加速。您可以查看我的C源代码http://example.com/test_vectorization/main_benchmark.c.txt(带有.txt扩展名可直接在浏览器中查看),用于基准测试的shell脚本为http://example.com/test_vectorization/run_benchmark。
如@Mischa所说,我尝试应用以下编译命令行: $GCC -O3 -Wa,-q -mavx -fprefetch-loop-arrays main_benchmark.c -o vectorizedExe 但生成的代码没有AVX指令。
如果您能够查看这些文件,那就太好了。谢谢。
foo(int size, double *a, double *b, double *c) { for(int i=0; i<size; i++) c[i] = a[i] + b[i];}GCC 将使用-O3向量化foo,所以我很惊讶你看到了任何加速。 - Z boson-O0标志和`#ifdef NOVEC void addition_tab(int size, double *a, double *b, double *c) { int i; // Classical sum for (i=0; i<size; i++) c[i] = a[i] + b[i];} #endif编译命令行为gcc-mp-4.9 -DNOVEC -O0 main_benchmark.c -o noVectorizedExe`。 - user1773603-O1给gcc(最好使用-O2或-O3与-march=native)。对未经优化的二进制文件进行基准测试是没有意义的。 - Basile Starynkevitch