我的数据长这样:
df <- data.frame(Price=seq(1, 1.5, 0.1),
Sales=seq(6, 1, -1),
Quality=c('A','A','A','B','B','B'),
Brand=c('F','P','P','P','F','F'))
有时我需要在多个列上进行复杂的计算,并按多个因素级别聚合值。以一个简化的例子来说,如果我想要得到每个
Quality 中按 Brand 分割的 Revenue(= Price * Sales) 分布情况,我会这样做:df$Revenue <- df$Price*df$Sales
RevSumByQ <- aggregate(Revenue~Quality, data=df, sum)
colnames(RevSumByQ)[2] <- "RevSumByQ"
df <- merge(df, RevSumByQ)
RevSumWithinQByB <- aggregate(RevSumByQ~Brand, data=df, sum)
colnames(RevSumWithinQByB)[2] <- "RevSumWithinQByB"
df <- merge(df, RevSumWithinQByB)
df$RevDistWithinQByB = df$RevSumByQ/df$RevSumWithinQByB
df
Brand Quality Price Sales Revenue RevSumByQ RevSumWithinQByB RevDistWithinQByB
1 F A 1.0 6 6.0 16.3 32.7 0.4984709
2 F B 1.4 2 2.8 8.2 32.7 0.2507645
3 F B 1.5 1 1.5 8.2 32.7 0.2507645
4 P A 1.1 5 5.5 16.3 40.8 0.3995098
5 P A 1.2 4 4.8 16.3 40.8 0.3995098
6 P B 1.3 3 3.9 8.2 40.8 0.2009804
如果在绘图中显示:
require(ggplot2)
ggplot(data=df, aes(x=Brand, y=RevDistWithinQByB, fill=Quality)) + geom_bar(stat='identity')
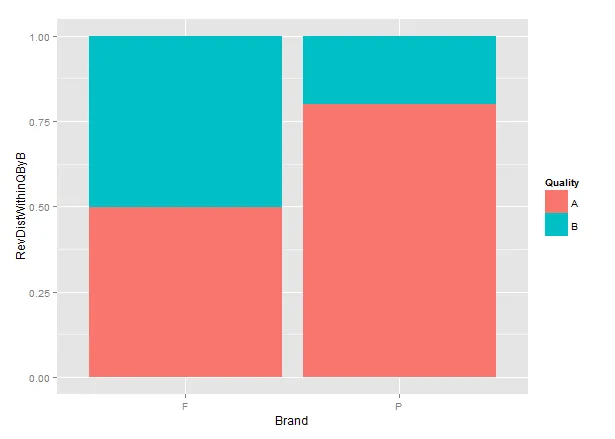
应该有更好的方法来绘制这个图,但我主要关心的是获取数据框(Revenue, RevSumByQ, RevSumWithinQByB)时中间结果较少。我可以看到我的方法中存在一些结构,所以我想知道是否有更优雅的解决方案或者是否已经有一些函数可以简化这种任务。
mutate(RevSumByQ=sum(Price*Sales)) %>%,因为之后不再需要Revenue。 - talat