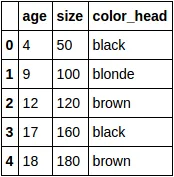
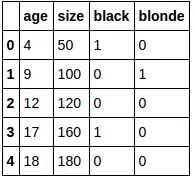
我有一个包含二元分类变量和连续变量的数据集。我正尝试应用线性回归模型来预测一个连续变量。请问如何检查分类变量和连续目标变量之间的相关性?
当前代码:
import pandas as pd
df_hosp = pd.read_csv('C:\Users\LAPPY-2\Desktop\LengthOfStay.csv')
data = df_hosp[['lengthofstay', 'male', 'female', 'dialysisrenalendstage', 'asthma', \
'irondef', 'pneum', 'substancedependence', \
'psychologicaldisordermajor', 'depress', 'psychother', \
'fibrosisandother', 'malnutrition', 'hemo']]
print data.corr()
除了lengthofstay变量之外,所有变量都是分类变量。这样可以吗?