目前我正在做这件事,但由于存储桶中有数千亿字节的数据,所以非常缓慢:
gsutil du -sh gs://my-bucket-1/
对于子文件夹同样适用:
gsutil du -sh gs://my-bucket-1/folder
有没有办法以更快的方式在其他地方或以其他方式获取完整存储桶(或子文件夹)的总大小?
目前我正在做这件事,但由于存储桶中有数千亿字节的数据,所以非常缓慢:
gsutil du -sh gs://my-bucket-1/
对于子文件夹同样适用:
gsutil du -sh gs://my-bucket-1/folder
有没有办法以更快的方式在其他地方或以其他方式获取完整存储桶(或子文件夹)的总大小?
这里谷歌存储的可见度相当糟糕
最快的方法是实际上获取stackdriver指标并查看以字节为单位的总大小: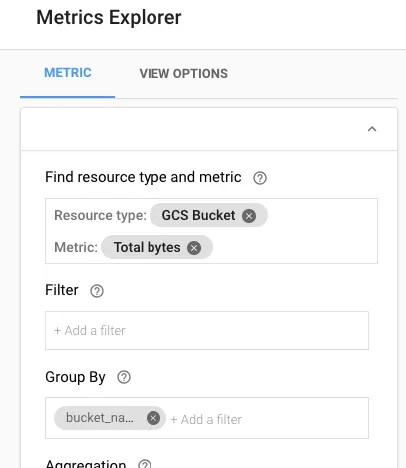
不幸的是,在stackdriver中几乎无法进行筛选。您不能使用通配符来匹配桶名称,而且几乎没有用处的桶资源标签在stack driver指标中不可聚合
此外,这仅适用于存储桶级别-不包括前缀
SD指标每天更新一次,因此除非您可以等待一天,否则无法使用此功能立即获取当前大小
更新:Stack Driver指标现在支持用户元数据标签,因此您可以对GCS存储桶进行标记,并通过应用的自定义标签汇总这些指标。
如果您要从此指标创建监视器,则需要提醒一下。目前该度量标准存在一个非常糟糕的错误。
GCP偶尔会出现平台问题,导致该指标停止编写。我认为它是租户特定的(也许?),因此您也看不到它们的公共健康状态页面上。由于他们的内部支持人员似乎很难记录,因为每次我们打开投诉单抱怨时,他们似乎都认为我们在撒谎,需要经过一些来回沟通才能承认它已经损坏了。
如果您拥有许多存储桶并且发生故障,停止将度量写入您的项目,可能会出现这种情况。虽然并不总是发生,但我们每年会看到几次。
例如,这种情况又再次发生在我们身上了。这是我现在在所有项目的Stackdriver中看到的情况:
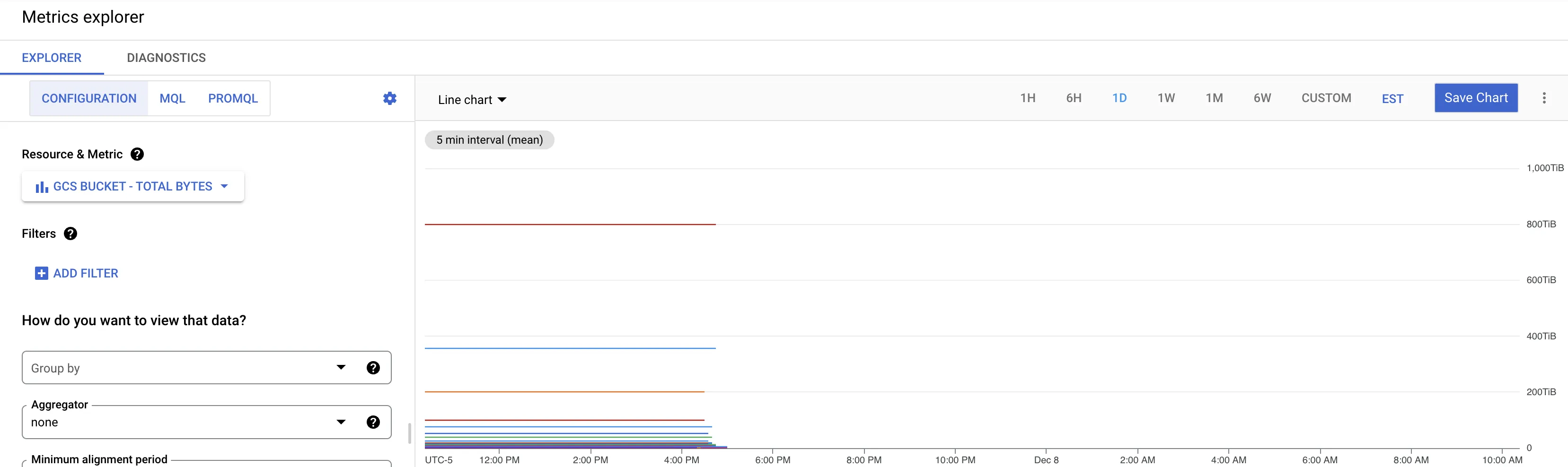
仅附加我们在最近这次度量中断期间从GCP支持团队获得的最后回复。我要补充说明,所有我们的存储桶都可访问,只是该度量未被写入:
产品团队得出结论,这确实是一个广泛性问题,与您的项目无关。这个内部问题导致一些GCS存储桶不可用,直接影响计量系统,这就是为什么“GCS存储桶总字节数”度量值不可用的原因。
很遗憾,目前没有更快的方法可以得知存储桶的大小。如果你需要经常检查,你可以启用存储桶日志记录功能。Google Cloud Storage会生成每日存储日志,你可以使用它来检查存储桶的大小。如果这对你有用,你可以在这里了解更多信息:https://cloud.google.com/storage/docs/accesslogs#delivery
du 命令会发出多少个请求?每个对象一个请求,还是有优化的方式?从计费角度来看这一点很重要。 - Ivan Balashov如果启用桶日志记录(根据Brandon的建议)获取的每日存储日志无法满足您的需求,您可以尝试加速操作的方法之一是对du请求进行分片。例如,您可以执行以下操作:
gsutil du -s gs://my-bucket-1/a* > a.size &
gsutil du -s gs://my-bucket-1/b* > b.size &
...
gsutil du -s gs://my-bucket-1/z* > z.size &
wait
awk '{sum+=$1} END {print sum}' *.size
假设你的子文件夹以英文字母命名; 如果不是,你需要调整如何运行上述命令。
使用内置仪表板
操作 -> 监控 -> 仪表板 -> 云存储
底部的图表显示所有存储桶的大小,或者您可以选择一个单独的存储桶进行详细查看。
请注意,指标每天只更新一次。
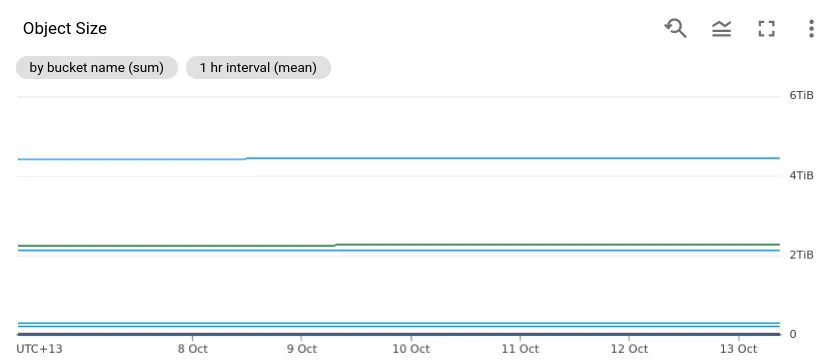
谷歌控制台
平台 -> 监控 -> 仪表盘 -> 选择存储桶
向下滚动可以查看该存储桶中对象的大小
使用Python可以如下获取您的存储桶大小:
from google.cloud import storage
storage_client = storage.Client()
blobs = storage_client.list_blobs(bucket_or_name='name_of_your_bucket')
blobs_total_size = 0
for blob in blobs:
blobs_total_size += blob.size # size in bytes
blobs_total_size / (1024 ** 3) # size in GB
gsutil ls -l -R gs://${bucket_name}for bucket_name in $(gcloud storage buckets list "--format=value(name)"); do echo "$bucket_name;$(gsutil ls -l -R gs://${bucket_name})"; done | grep TOTAL | awk '{s+=$4}END{print s/1024/1024/1024/1024}'对我来说,以下命令有所帮助:
gsutil ls -l gs://{bucket_name}
列出所有文件后,它会给出以下输出:
TOTAL: 6442 objects, 143992287936 bytes (134.1 GiB)
#!/bin/bash
PROJECT_ID='<<PROJECT_ID>>'
ACCESS_TOKEN="$(gcloud auth print-access-token)"
CHECK_TIME=10
STARTTIME=$(date --date="${CHECK_TIME} minutes ago" -u +"%Y-%m-%dT%H:%M:%SZ")
ENDTIME=$(date -u +"%Y-%m-%dT%H:%M:%SZ")
FILTER="$( echo -n 'metric.type="storage.googleapis.com/storage/total_bytes"' | ruby -n -r 'cgi' -e 'print(CGI.escape($_))' )"
START="$( echo -n "${STARTTIME}" | ruby -n -r 'cgi' -e 'print(CGI.escape($_))' )"
END="$( echo -n "${ENDTIME}" | ruby -n -r 'cgi' -e 'print(CGI.escape($_))' )"
DETAILS=$(curl -s -H "Authorization: Bearer ${ACCESS_TOKEN}" \
"https://monitoring.googleapis.com/v3/projects/${PROJECT_ID}/timeSeries/?filter=${FILTER}&interval.startTime=${START}&interval.endTime=${END}")
for i in $(echo "$DETAILS" | jq -r ".timeSeries[]|[.resource.labels.bucket_name,.resource.labels.location,.metric.labels.storage_class,.points[0].value.doubleValue]|@csv"|sort -t, -n -k4,4nr ); do
f1=${i%,*}
f2=${i##*,}
size=$(numfmt --to=iec-i --suffix=B --format="%9.2f" $f2)
echo $f1,$size
done
{kind=link}
You can't wildcard the bucket nameYes you can... the operators with ~ mean they support RegEx... so to find all buckets that start with video- usebucket_name =~ video.*- Ray Foss