假设我有两个Haskell库,每个库都有一个用于计算的类型,
这是因为
所以我可以用
这是它的组成部分:
组合性
假设一个应用程序需要以交错的方式使用monads
例如,像这样的东西:
LibA和LibB。它们都是在IO单子之上堆叠的单子,使用ReaderT单子变换器实现:import Control.Monad.IO.Class (MonadIO)
import qualified Control.Monad.Reader as MR
import Control.Monad.Trans.Reader (runReaderT)
newtype LibA a = LibA (MR.ReaderT String IO a)
deriving (Functor, Applicative, Monad, MonadIO)
newtype LibB a = LibB (MR.ReaderT String IO a)
deriving (Functor, Applicative, Monad, MonadIO)
使用这些库表达的程序通过runReaderT执行:
runA :: String -> LibA a -> IO a
runA s (LibA x) =
runReaderT x s
runB :: String -> LibB b -> IO b
runB s (LibB x) =
runReaderT x s
现在假设我想编写一个同时使用这两个库的应用程序。
当它们独立使用时,它们可以正常工作:
runA "conf" (return (2 :: Int)) :: IO Int
runB "conf" (return "foo") :: IO String
然而,将一个放在另一个内部是不行的:
runA "conf" $ do
-- Expected: LibA String, Actual: IO String
runB "conf" (return "foo")
这是因为
runB在IO monad中返回。所以我可以用
liftIO将其提升到LibA中。runA "conf" $ do
liftIO (runB "conf" (return "foo"))
这是它的组成部分:
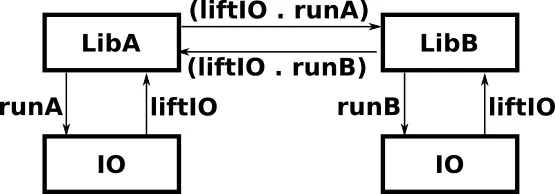
组合性
假设一个应用程序需要以交错的方式使用monads
LibA 和 LibB 的计算。代码变得笨重:runA "conf" $ do
liftIO $
runB "conf" $ do
liftIO $
runA "conf" $ do
liftIO $
runB "conf" $ do
return "foo"
资源效率
对于真实世界的库,runA 和 runB 可能会在运行应用程序代码之前初始化资源。例如建立和释放到 Web 服务器、文件输入输出等的连接。深层嵌套的 runA 和 runB 调用将创建大量不必要的资源处理。
例如,假设 runA 创建一个 HTTP 连接管理器 Manager 来维护与 Web 服务器的一个连接:
runA :: String -> LibA a -> IO a
runA s (LibA x) =
let settings = mkManagerSettings (TLSSettingsSimple True False False) Nothing
manager <- liftIO $ newManager settings
runReaderT (MySession x manager) s
在x中的操作可以使用ask从ReaderT上下文中获取管理器,以重用manager。
newManager的文档说明:
创建新的Manager是一个相对昂贵的操作,建议您在请求之间共享单个Manager。
因此,在交错执行runA和runB时,我不希望重复调用newManager,而是希望为所有LibA计算仅创建一次管理器,即使这些计算是从嵌套的runB调用中提升而来的。
解决方案?
我想要的是一种可组合的方式,可以在不嵌套liftIO调用的情况下交错执行LibA和LibB计算,并且不会多次创建/释放IO资源。它们都直接堆叠在IO单子之上,因此这并不超出想象的范围。我没有修改库实现的方法。例如,像这样的东西:
runAB :: (String, LibA a) -> (String, LibB b) -> IO (a, b)
这将为LibA和LibB的操作创建相关的IO资源,仅执行一次。
或者,如果无法实现资源效率,则为了可读性,可以允许更直接地编写代码,就好像它们都堆叠在IO单子栈上方:
runA "conf" (runB "conf" (return "foo"))
有哪些选项?