如何编写一个正则表达式,其中包含字符{x,y},但必须以相同的字母开头和结尾? 例如:
xyyyxyxyxyxyxy
如何编写一个正则表达式,其中包含字符{x,y},但必须以相同的字母开头和结尾? 例如:
xyyyxyxyxyxyxy这应该适合您的需求:
^(x|y).*\1$
这个正则表达式将匹配以相同字母开头和结尾的字符串(如帖子标题所示),但它不限制字符串仅包含x和y字符。它将匹配任何以括号中指定的相同字母开头和结尾的字符串。
它将匹配由{x,y}字符组成的、以相同字母开头和结尾的字符串(如OP所指定)。
xyyyxyx
yxyxyxy
zxyxyxz
xyxyxyy
但它也将匹配在两者之间具有任何字符的字符串(不仅限于x和y):
xgjyhdtfx
yjsaudgty
xuhgrey
yudgfsx
yaaay
工作的正则表达式示例:
这个正则表达式有效:
^([xy])[xy]*\1$|^[xy]$
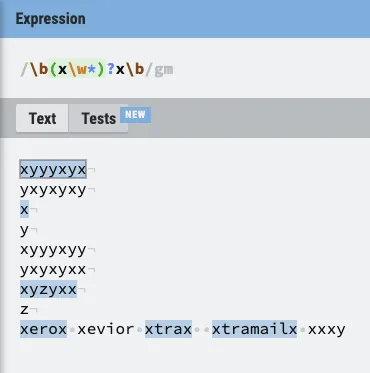
I tested it on regexr with
xyyyxyx
yxyxyxy
x
y
xyyyxyy
yxyxyxx
xyzyxx
z
而且它只匹配了前四个。
^(([x][xy]*[x])|([y][xy]*[y])|[x|y])$
^\(.\).*\1$
查找您需要的内容。
^(a).*(a)$|^(b).*(b)$
这个方法是可行的。我已经进行了测试,测试结果如下:
aba - true
abbb - false
bab - true
abababa - true
aba - true
aaaabbbbbaaa
解释:
第一种情况 ^(a).*(a)$
第一组捕获 (a)
第二组捕获 (a)
第二种情况 ^(b).*(b)$
第三组捕获 (b)
第四组捕获 (b)
全局模式标志
要更正的正则表达式是^(x).(x)$|^(y).(y)$|^([xy])[xy]*\1$|^[xy]$
在这里,我们使用所有验证匹配字符串中出现x和y的起始和结束字符。
您可以使用:
/^([xy]|[xy]).*\1$/
^(x|y).*(x|y)$。import re
#Check if the string starts with "x or y" and ends with "x or y":
txt = "xyyyxyx"
x1 = re.search("^(x|y).*(x|y)$", txt)
txt2 = "yxyxyxy"
x2 = re.search("^(x|y).*(x|y)$", txt2)
if x1:
print("YES! We have a match!")
# YES! We have a match!
if x2:
print("YES! We have a match!")
# YES! We have a match!
^(x|y) <<-- 这意味着以 x 或者 y 开始,您可以替换 x 和 y 的值或添加更多内容
.* <<-- 表示在开始和结束值之间有零个或多个字符
(x|y)$ <<-- 与开始一样,但以 x 或 y 值结尾,我们可以替换 x 或 y 或添加新值。