我想要重复搜索一个不变的数组中的值。
目前,我的做法是:将这些值放入一个哈希表中(因此我有一个数组和一个基本上包含相同内容的哈希表),然后使用exists函数来搜索哈希表。
我不喜欢有两个不同的变量(数组和哈希表)同时存储着同样的东西;然而,哈希表用于搜索会更快。
我发现在Perl 5.10中有一个~~(智能匹配)操作符。在搜索一个标量值在一个数组中时,它有多高效?
我想要重复搜索一个不变的数组中的值。
目前,我的做法是:将这些值放入一个哈希表中(因此我有一个数组和一个基本上包含相同内容的哈希表),然后使用exists函数来搜索哈希表。
我不喜欢有两个不同的变量(数组和哈希表)同时存储着同样的东西;然而,哈希表用于搜索会更快。
我发现在Perl 5.10中有一个~~(智能匹配)操作符。在搜索一个标量值在一个数组中时,它有多高效?
first子例程。一旦它找到答案,它就会停止。如果您已经有哈希表,我不认为这比哈希查找更快,但是当您考虑创建哈希表并将其保存在内存中时,仅搜索您已经拥有的数组可能更方便。#!perl
use 5.12.2;
use strict;
use warnings;
use Benchmark qw(cmpthese);
my @hits = qw(A B C);
my @base = qw(one two three four five six) x ( $ARGV[0] || 1 );
my @at_end = ( @base, @hits );
my @at_beginning = ( @hits, @base );
my @in_middle = @base;
splice @in_middle, int( @in_middle / 2 ), 0, @hits;
my @random = @base;
foreach my $item ( @hits ) {
my $index = int rand @random;
splice @random, $index, 0, $item;
}
sub count {
my( $hits, $candidates ) = @_;
my $count;
foreach ( @$hits ) { when( $candidates ) { $count++ } }
$count;
}
cmpthese(-5, {
hits_beginning => sub { my $count = count( \@hits, \@at_beginning ) },
hits_end => sub { my $count = count( \@hits, \@at_end ) },
hits_middle => sub { my $count = count( \@hits, \@in_middle ) },
hits_random => sub { my $count = count( \@hits, \@random ) },
control => sub { my $count = count( [], [] ) },
}
);
以下是各部分的表现。请注意,这是一个双对数坐标轴图,因此下降线的斜率并不像它们看起来那么接近:
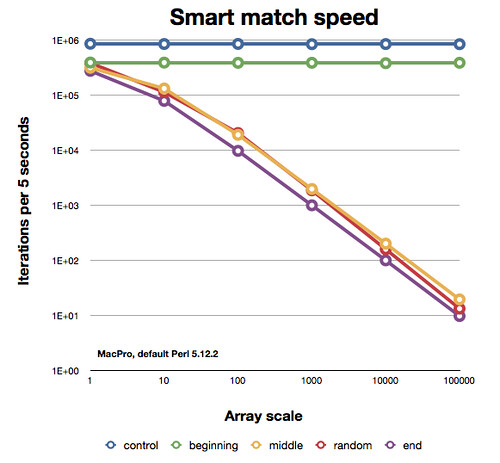
因此,看起来智能匹配运算符有点聪明,但这并不能真正帮助你,因为你仍然可能不得不扫描整个数组。你可能事先不知道在哪里找到你的元素。我认为哈希表将执行与最佳情况下的智能匹配相同的操作,即使你不得不为它放弃一些内存。
my %old_hash = map {$_,1} @in_middle;
cmpthese(-5, {
...,
new_hash => sub {
my %h = map {$_,1} @in_middle;
my $count = 0;
foreach ( @hits ) { $count++ if exists $h{$_} }
$count;
},
old_hash => sub {
my $count = 0;
foreach ( @hits ) { $count++ if exists $old_hash{$_} }
$count;
},
control_hash => sub {
my $count = 0;
foreach ( @hits ) { $count++ }
$count;
},
}
);
以下是情节。颜色有点难以区分。最低的那条线是每次想要搜索时都必须创建哈希表的情况。那很差劲。最高的两条(绿色)线是哈希控制(实际上没有哈希)和现有的哈希查找。这是一个对数/对数图;这两种情况比智能匹配控制(只调用子例程)还要快。

需要注意的是,"random"情况下的代码略有不同。这很容易理解,因为每个基准测试(也就是每次数组规模运行)都会在候选数组中随机放置命中元素。有些运行会把它们放得更早一些,有些则更晚一些,但由于我只在整个程序的运行中一次性创建@random数组,所以它们会稍微移动一下。这意味着线条上的颠簸并不重要。如果我尝试所有位置并取平均值,我预计"random"线将与"middle"线相同。
现在,看着这些结果,我会说智能匹配在最坏情况下比哈希查找快得多。这是有道理的。要创建哈希表,我必须访问数组的每个元素,并且还要进行哈希,这需要大量复制。而智能匹配没有复制。
这里还有一个进一步的案例,我不会详细考虑。什么时候哈希表比智能匹配更好?也就是说,当创建哈希表的开销在重复搜索中足够分散时,哈希表是更好的选择?
适用于少量潜在匹配项的快速方法,但不比哈希更快。哈希是测试集合成员资格的正确工具,因为哈希访问的时间复杂度是 O(log n),而对数组进行智能匹配仍然是 O(n)线性扫描(虽然与 grep 不同,它是短路的)。随着允许匹配的值数量越来越多,智能匹配变得相对更差。
#!perl
use 5.12.0;
use Benchmark qw(cmpthese);
my @hits = qw(one two three);
my @candidates = qw(one two three four five six); # 50% hit rate
my %hash;
@hash{@hits} = ();
sub count_hits_hash {
my $count = 0;
for (@_) {
$count++ if exists $hash{$_};
}
$count;
}
sub count_hits_smartmatch {
my $count = 0;
for (@_) {
$count++ when @hits;
}
$count;
}
say count_hits_hash(@candidates);
say count_hits_smartmatch(@candidates);
cmpthese(-5, {
hash => sub { count_hits_hash((@candidates) x 1000) },
smartmatch => sub { count_hits_smartmatch((@candidates) x 1000) },
}
);
Rate smartmatch hash
smartmatch 404/s -- -65%
hash 1144/s 183% --
“智能匹配”中的“智能”并不是指搜索,而是基于上下文在合适的时间做出正确的事情。
遍历数组和索引哈希表哪个更快这个问题还需要进行基准测试,但一般来说,要比索引哈希表更快,必须是一个非常小的数组才行。