对于Linux系统下的少量字节文件,我只需要在上次处理它以来更改时才进行处理。我会定期通过调用PHP的clearstatcache(); filemtime(); 来检查文件是否被更改。由于整个文件始终很小,删除对filemtime的调用并通过将内容与历史内容进行比较来检查文件更改是否能提高性能?或者在性能方面,什么是最佳方法。
文件修改时间检查的成本
14
- doc_id
8
4个回答
18
使用 filemtime + clearstatcache
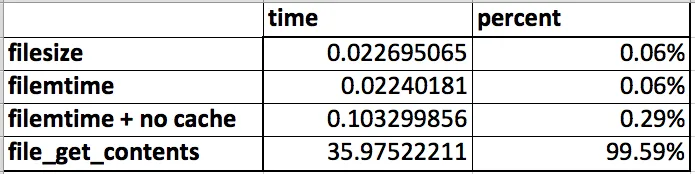
为了增强@Ben_D的测试:
<?php
$file = 'small_file.html';
$loops = 1000000;
// filesize (fast)
$start_time = microtime(1);
for ($i = 0; $i < $loops; $i++) {
$file_size = filesize($file);
}
$end_time = microtime(1);
$time_for_file_size = $end_time - $start_time;
// filemtime (fastest)
$start_time = microtime(1);
for ($i = 0; $i < $loops; $i++) {
$file_mtime = filemtime($file);
}
$end_time = microtime(1);
$time_for_filemtime = $end_time - $start_time;
// filemtime + no cache (fast and reliable)
$start_time = microtime(1);
for ($i = 0; $i < $loops; $i++) {
clearstatcache();
$file_mtime_nc = filemtime($file);
}
$end_time = microtime(1);
$time_for_filemtime_nc = $end_time - $start_time;
// file_get_contents (slow and reliable)
$start_time = microtime(1);
for ($i = 0; $i < $loops; $i++) {
$file_contents = file_get_contents($file);
}
$end_time = microtime(1);
$time_for_file_get_contents = $end_time - $start_time;
// output
echo "
<p>Working on file '$file'</p>
<p>Size: $file_size B</p>
<p>last modified timestamp: $file_mtime</p>
<p>file contents: $file_contents</p>
<h1>Profile</h1>
<p>filesize: $time_for_file_size</p>
<p>filemtime: $time_for_filemtime</p>
<p>filemtime + no cache: $time_for_filemtime_nc</p>
<p>file_get_contents: $time_for_file_get_contents</p>";
/* End of file */
- Geo
1
12请注意,只有在同一个请求期间需要多次获取同一文件的最新
filemtime信息时(并且如果在请求期间文件可能被修改),才需要调用clearstatcache();函数。filemtime缓存会在请求完成后失效。 - TiMESPLiNTER8
我知道我来晚了,但是进行一些基准测试并不会影响讨论。Brian Roach的直觉证明了这一点,即使在考虑比较步骤之前也是如此:
测试内容:
$file = "small_file.html";
$file_size = filesize($file);
//get the filemtime 1,000,000 times
$start_time = microtime(true);
for($i=0;$i<1000000;$i++){
$set_time = filemtime($file);
}
$end_time = microtime(true);
$time_for_filemtime = ($end_time-$start_time);
//get the time for file_get_contents 1,000,000 times
$start_time = microtime(true);
$file = "small_file.html";
for($i=0;$i<1000000;$i++){
$set_time = file_get_contents($file);
}
$end_time = microtime(true);
$time_for_file_get_contents = ($end_time-$start_time);
echo "<p>Working on a file that is $file_size B long</p>
<p>filemtime: $time_for_filemtime vs file_get_contents: $time_for_file_get_contents";
结果
正在处理一个长度为41B的文件
filemtime:0.36287999153137 vs file_get_contents:16.191468000412
毫不奇怪:"向文件系统请求一些元数据"比"打开文件,读取内容并比较它们"更快。
- Ben D
4
要开始文件,你只需要向文件系统请求一些元数据。
你的第二种方法涉及打开文件,读取它并比较内容。
你认为哪个会更快? ;)
- Brian Roach
2
1这很有道理,但关于这个问题还有更多需要询问的地方,比如文件系统是否针对文件读取进行优化而非元数据。再加上PHP用于统计的缓存操作本身的成本。 - doc_id
另一个需要考虑的因素是,使用第一种方法,当检测到修改时,最终必须读取内容并比较修改时间。我记得在某个地方看到过FileSystemWatch,但并不太清楚。 - doc_id
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
filemtime()访问低级系统函数,这些函数总是会比实际打开文件更快。很想听听文件系统/操作系统专家的意见。 - Pekka