设置
我用Python在Windows PC上编写了一段相当复杂的软件。我的软件基本上启动了两个Python解释器窗口。第一个窗口在双击main.py文件时启动(我猜测)。在这个窗口中,会以以下方式启动其他线程:
# Start TCP_thread
TCP_thread = threading.Thread(name = 'TCP_loop', target = TCP_loop, args = (TCPsock,))
TCP_thread.start()
# Start UDP_thread
UDP_thread = threading.Thread(name = 'UDP_loop', target = UDP_loop, args = (UDPsock,))
TCP_thread.start()
Main_thread 启动了一个 TCP_thread 和一个 UDP_thread。虽然它们是独立的线程,但它们都在同一个 Python shell 中运行。
Main_thread 还启动了一个子进程。操作步骤如下:
p = subprocess.Popen(['python', mySubprocessPath], shell=True)
根据Python文档,我理解这个子进程在一个单独的Python解释器会话/Shell中同时运行。此子进程中的Main_thread完全专用于我的GUI。GUI为其所有通信启动了一个TCP_thread。
我知道事情变得有点复杂。因此,我已经在这张图片中总结了整个设置:
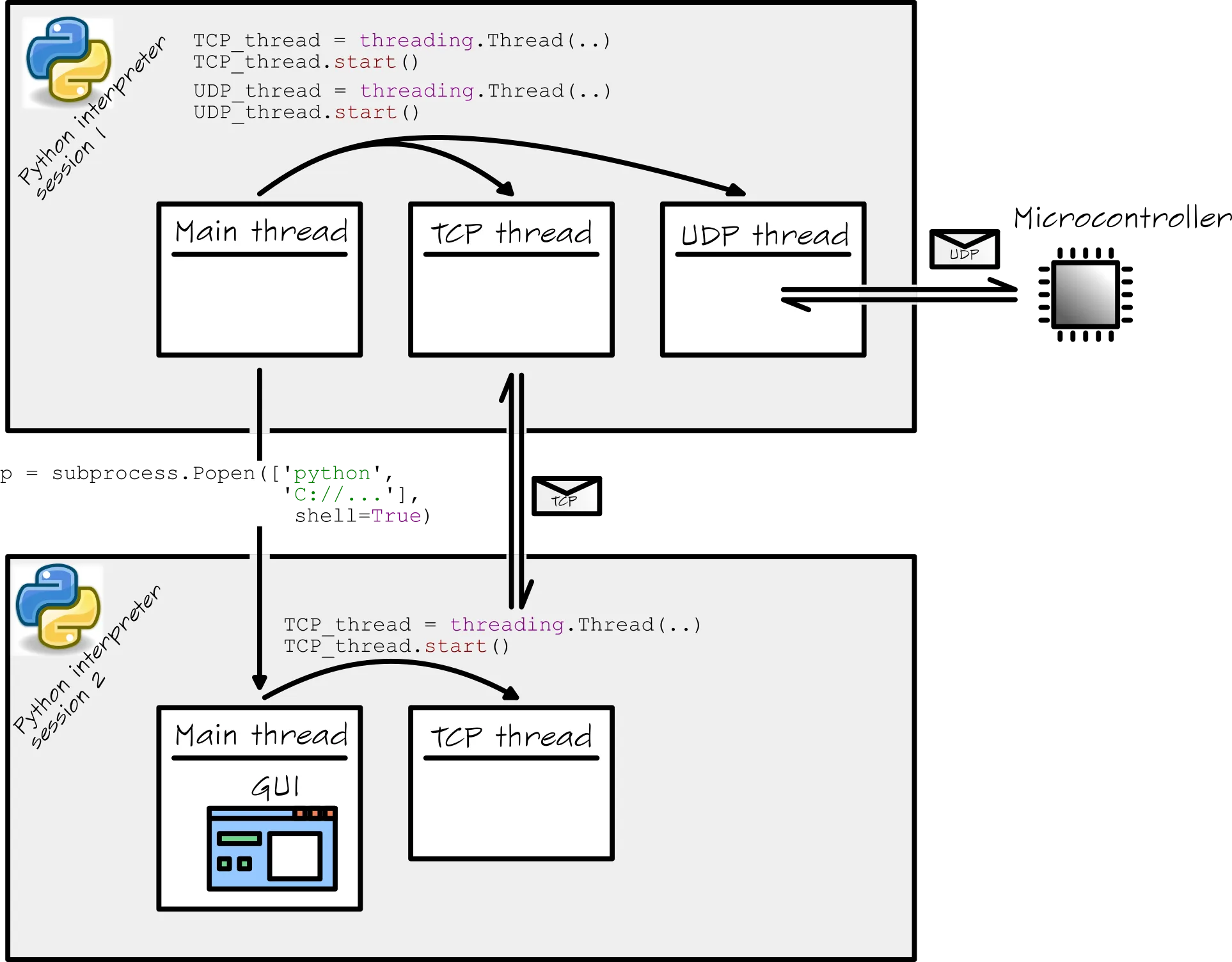
我有几个关于这个设置的问题。我将在这里列出它们:
问题1 [已解决]
Python解释器一次只使用一个CPU核心来运行所有线程,这是真的吗?换句话说,Python解释器会话1(来自图中)会在一个CPU核心上运行所有3个线程(Main_thread,TCP_thread和UDP_thread)吗?
答案:是的,这是正确的。GIL(全局解释器锁)确保所有线程一次只能在一个CPU核心上运行。
问题2 [尚未解决]
我有没有办法跟踪它是哪个CPU核心?
问题3 [部分解决]
对于这个问题,我们忘记线程,而是专注于Python中的子进程机制。启动一个新的子进程意味着启动一个新的Python解释器实例。这是正确的吗?
答案:是的,这是正确的。起初有些混淆,不确定以下代码是否会创建一个新的Python解释器实例:
p = subprocess.Popen(['python', mySubprocessPath], shell = True)
问题已经明确。这段代码确实会启动一个新的Python解释器实例。
Python是否足够智能,能让该独立的Python解释器实例在不同的CPU核心上运行?也许有一些零星的打印语句可以追踪它运行在哪个核心上吗?
问题 4 [新问题]
社区讨论提出了一个新问题。在生成一个新进程(在新的Python解释器实例中)时,显然有两种方法:
# Approach 1(a)
p = subprocess.Popen(['python', mySubprocessPath], shell = True)
# Approach 1(b) (J.F. Sebastian)
p = subprocess.Popen([sys.executable, mySubprocessPath])
# Approach 2
p = multiprocessing.Process(target=foo, args=(q,))
第二种方法的明显缺点是它只针对一个函数 - 而我需要打开一个新的Python脚本。不管怎样,这两种方法在实现上是否相似?