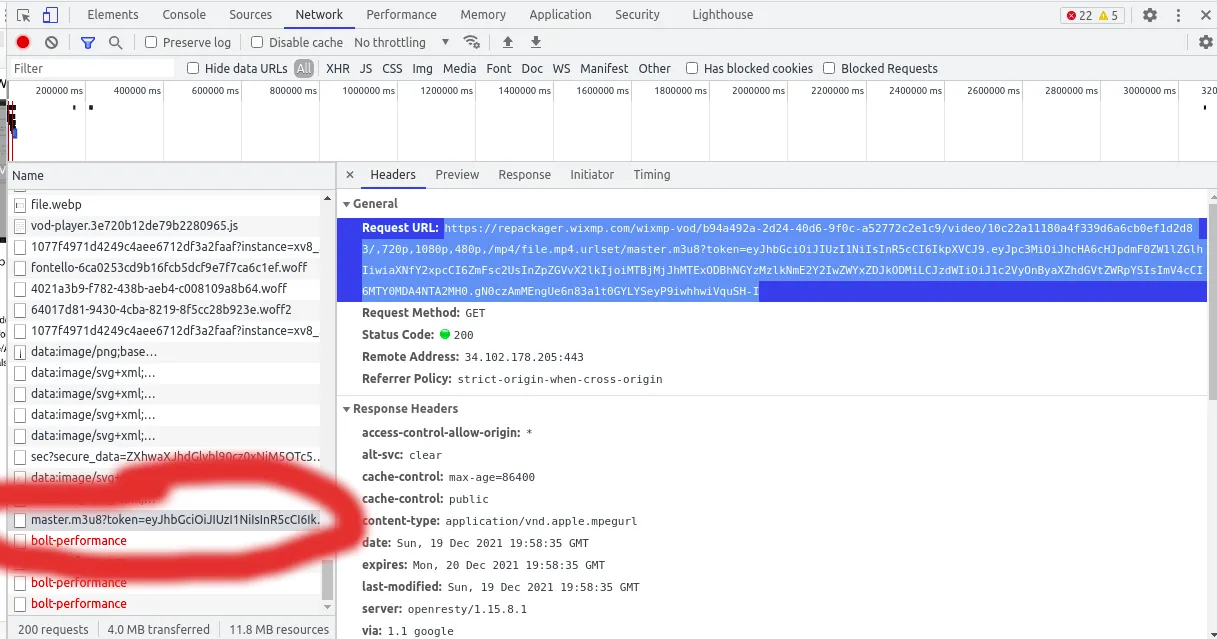
我想用Python脚本从网站上下载一个视频,但是视频的URL是以blob形式呈现的,如下所示。
<video class="jw-video jw-reset" style="object-fit: fill;" jw-loaded="data" src="blob:https://xxxxxxx.com/f717096e-5e1a-42e1-8c3c-3ec777b5d478"></video>