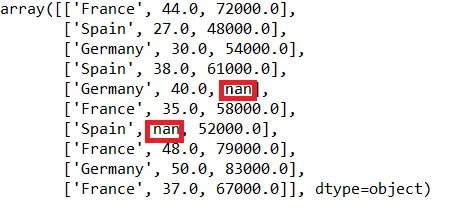
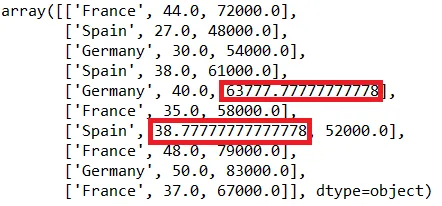
为了丰富个人知识,我一直在尝试不同于平均数/中位数/众数的缺失值填充方法。到目前为止,我已经尝试了KNN、MICE和中位数填充方法。我被告知可以使用聚类方法进行填充,但是我的互联网搜索只找到了研究论文,没有找到能够实现此功能的软件包。
我正在对Iris数据集运行这些填充方法,通过有意制造缺失值(因为Iris数据集本身没有缺失值)。我的其他方法如下:
data = pd.read_csv("D:/Iris_classification/train.csv")
#Shuffle the data and reset the index
from sklearn.utils import shuffle
data = shuffle(data).reset_index(drop = True)
#Create Independent and dependent matrices
X = data.iloc[:, [0, 1, 2, 3]].values
y = data.iloc[:, 4].values
#train_test_split
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 50, random_state = 0)
#Standardize the data
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
#Impute missing values at random
prop = int(X_train.size * 0.5) #Set the % of values to be replaced
prop1 = int(X_test.size * 0.5)
a = [random.choice(range(X_train.shape[0])) for _ in range(prop)] #Randomly choose indices of the numpy array
b = [random.choice(range(X_train.shape[1])) for _ in range(prop)]
X1_train[a, b] = np.NaN
X1_test[c, d] = np.NaN
然后针对KNN插补,我已经完成了
X_train_filled = KNN(3).complete(X_train)
X_test_filled = KNN(3).complete(X_test
有没有一种用聚类方法来补充缺失值的方式?同时,当数据中存在NaN值时,StandardScaler()无法工作。是否有其他方法来对数据进行标准化?