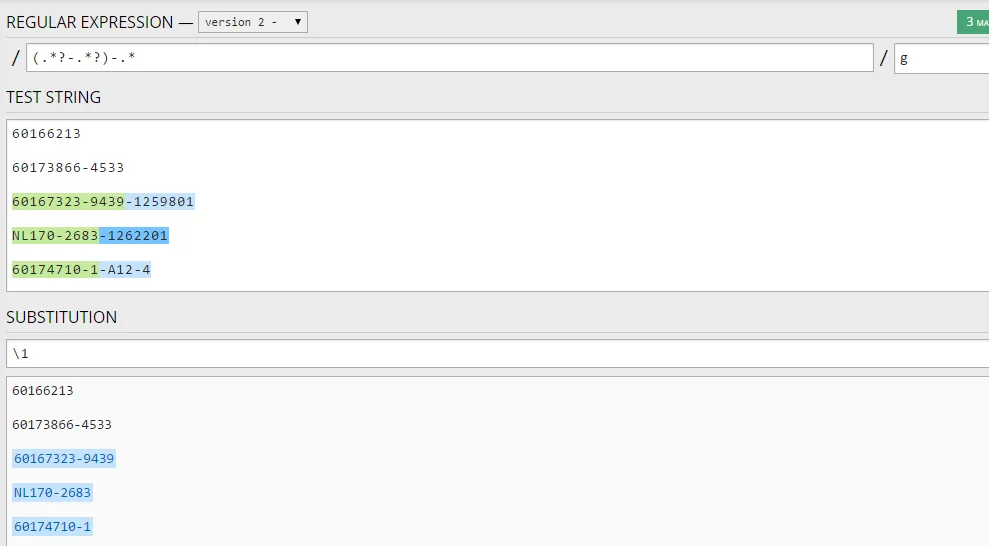
我有大量的数据需要使用正则表达式进行过滤。这些数据由以下格式的字符串组成:
60166213
60173866-4533
60167323-9439-1259801
NL170-2683-1262201
60174710-1-A12-4
当我需要它们看起来像这样时:
60166213
60173866-4533
60167323-9439
NL170-2683
60174710-1
我该如何使用正则表达式过滤掉第二个破折号及其后面的所有内容。破折号的数量是不确定的,如果字符串中没有超过一个破折号,则需要保留原样。
如果mystring中'-'的数量大于等于2,则分割并取前两部分这样的操作? - Jaspersplit而不是正则表达式来完成此操作。 - sideroxylon