这是我认为在其他环境中使用过的其他分析工具也存在的情况,但这种情况在这里尤其明显。 我正在对运行约12分钟的任务进行CPU分析,并且显示几乎一半的时间都花在了一个什么也不做的方法上:它的主体为空。 是什么原因导致了这种情况? 我不相信该方法被调用了荒谬的次数,肯定不能解释一半的执行时间。
值得一提的是,涉及到的方法称为startContent(),用于通知解析事件。 该事件通过一系列过滤器(可能有十几个)传递下去,并且每个过滤器上的startContent()方法几乎什么也不做,只是在链中调用下一个过滤器上的startContent()。
这是纯Java代码,我在Mac上运行它。
附上CPU采样器输出的屏幕截图: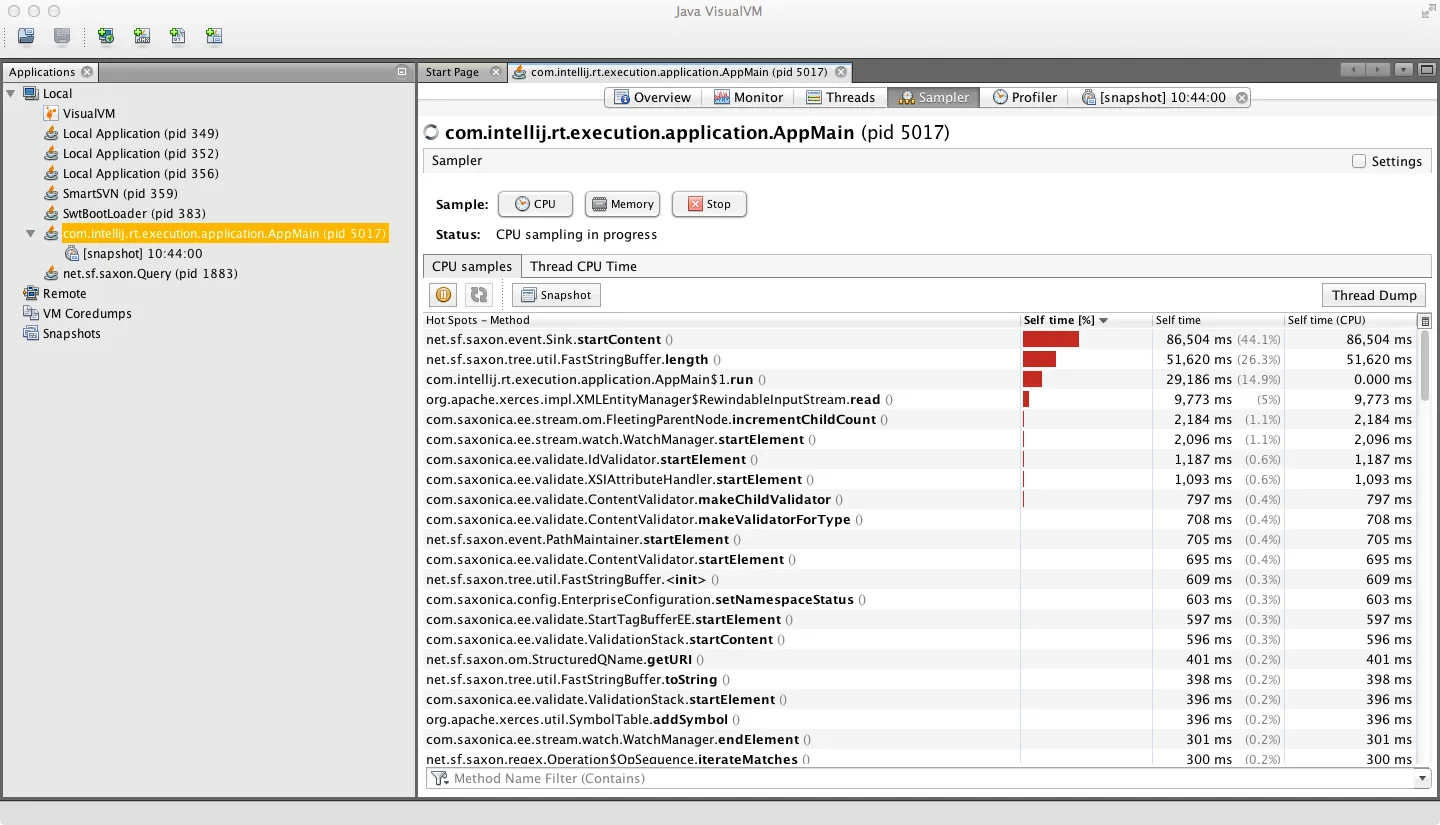 以下是显示调用堆栈的示例:
以下是显示调用堆栈的示例:
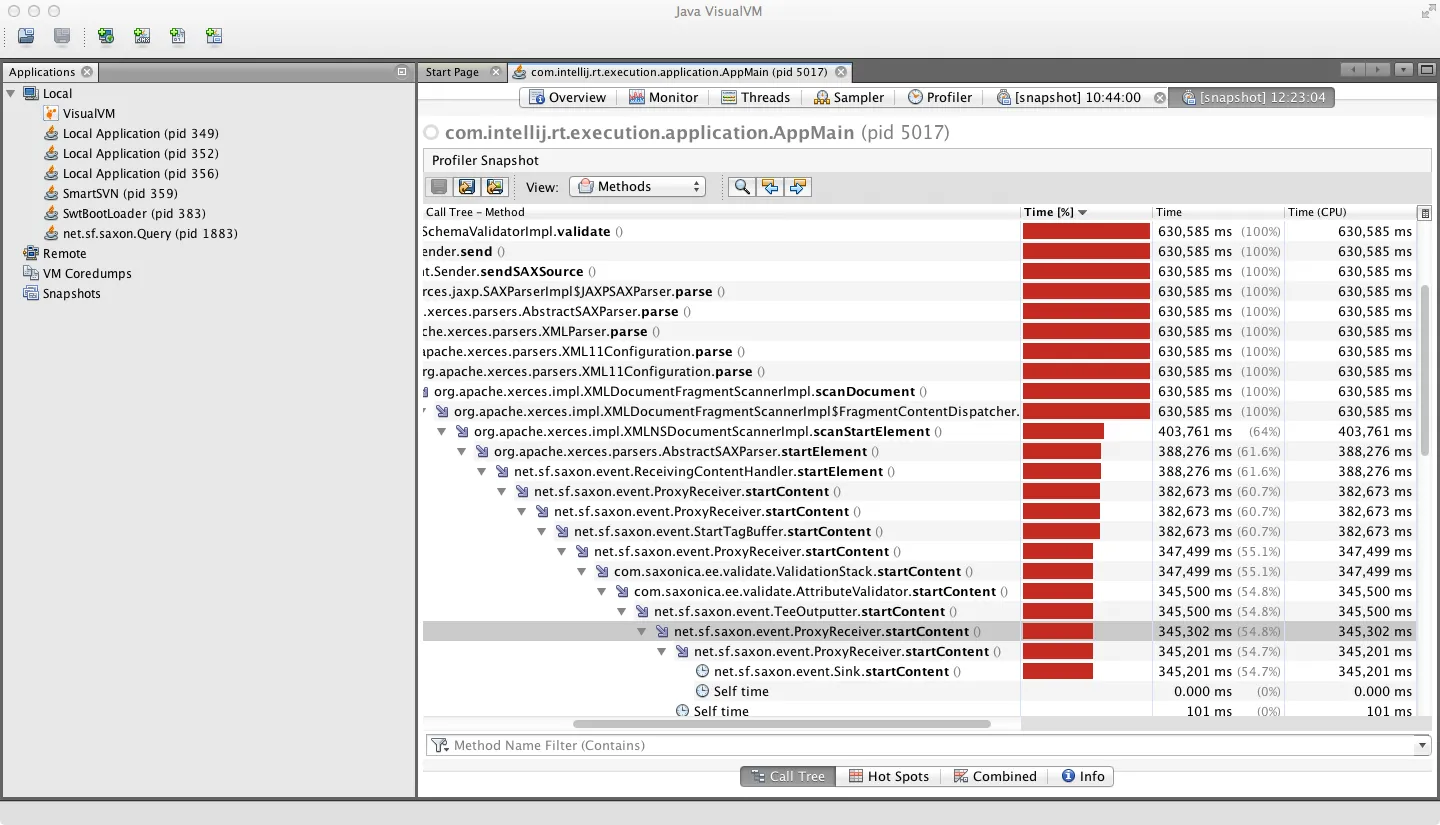 (由于度假而延迟后)这里有几张图片显示了分析器的输出。 这些数字更符合我期望的配置文件外观。 分析器输出似乎完全有意义,而采样器输出是虚假的。
(由于度假而延迟后)这里有几张图片显示了分析器的输出。 这些数字更符合我期望的配置文件外观。 分析器输出似乎完全有意义,而采样器输出是虚假的。
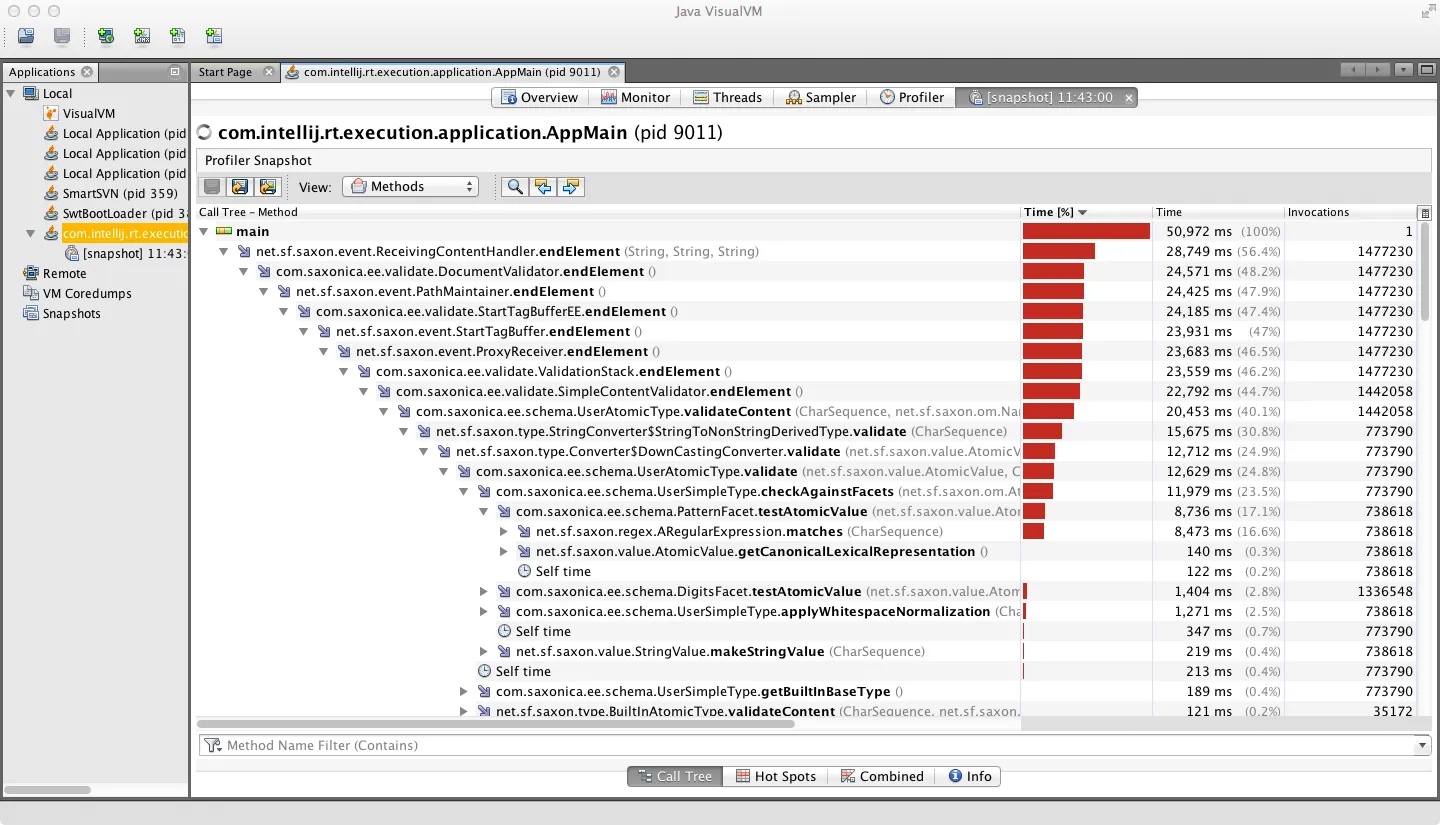
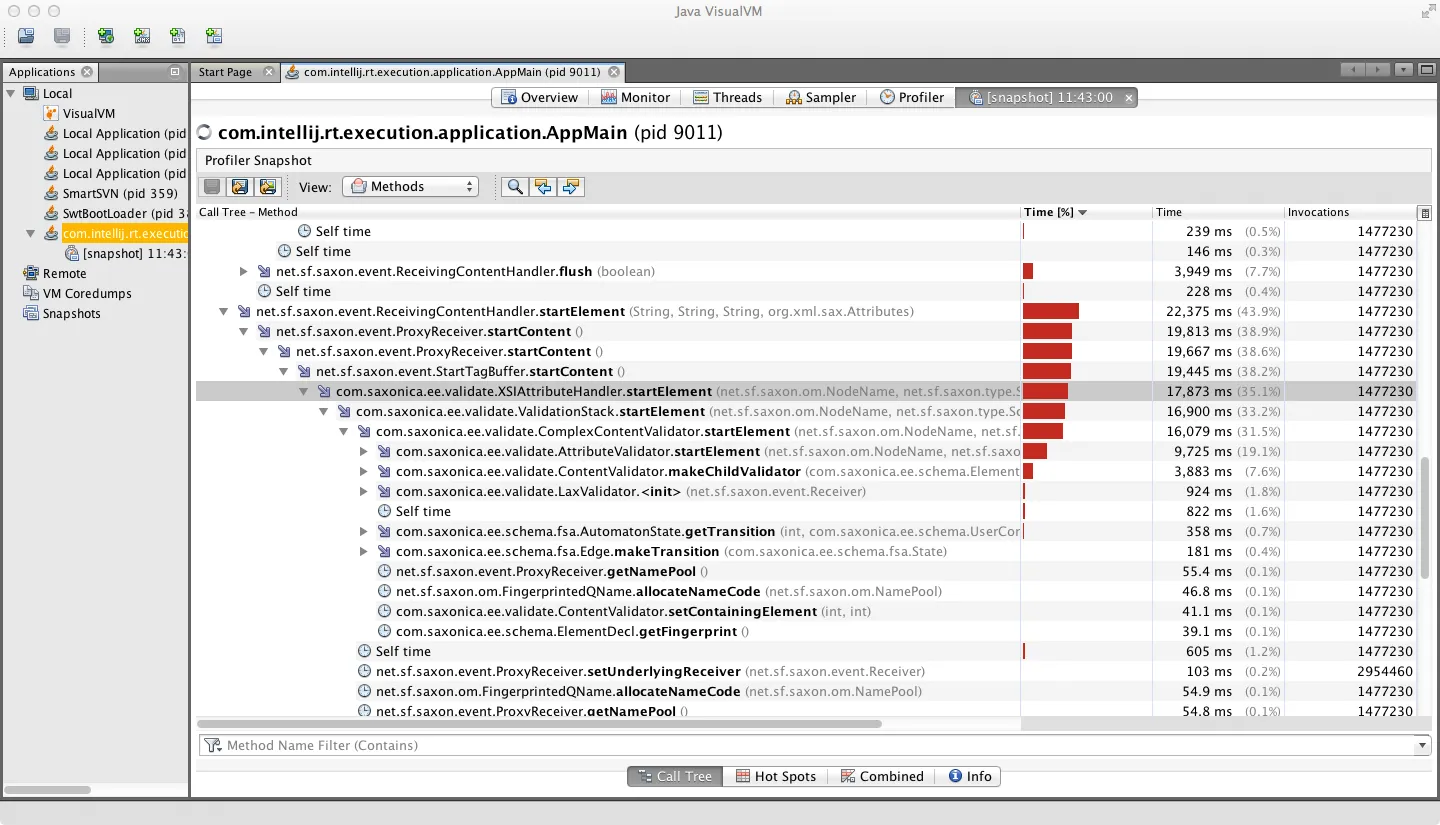 正如一些人猜测的那样,涉及到的工作是运行Saxon XML模式验证器(对9Gb输入文件)。 配置文件显示大约一半的时间用于根据简单类型验证元素内容(发生在endElement处理期间),另一半时间用于测试唯一性的关键约束; 两个分析器视图突出显示了该任务这两个方面中涉及的活动。
正如一些人猜测的那样,涉及到的工作是运行Saxon XML模式验证器(对9Gb输入文件)。 配置文件显示大约一半的时间用于根据简单类型验证元素内容(发生在endElement处理期间),另一半时间用于测试唯一性的关键约束; 两个分析器视图突出显示了该任务这两个方面中涉及的活动。
由于数据来自客户端,因此无法提供数据。
值得一提的是,涉及到的方法称为startContent(),用于通知解析事件。 该事件通过一系列过滤器(可能有十几个)传递下去,并且每个过滤器上的startContent()方法几乎什么也不做,只是在链中调用下一个过滤器上的startContent()。
这是纯Java代码,我在Mac上运行它。
附上CPU采样器输出的屏幕截图:
以下是显示调用堆栈的示例:
(由于度假而延迟后)这里有几张图片显示了分析器的输出。 这些数字更符合我期望的配置文件外观。 分析器输出似乎完全有意义,而采样器输出是虚假的。
正如一些人猜测的那样,涉及到的工作是运行Saxon XML模式验证器(对9Gb输入文件)。 配置文件显示大约一半的时间用于根据简单类型验证元素内容(发生在endElement处理期间),另一半时间用于测试唯一性的关键约束; 两个分析器视图突出显示了该任务这两个方面中涉及的活动。由于数据来自客户端,因此无法提供数据。