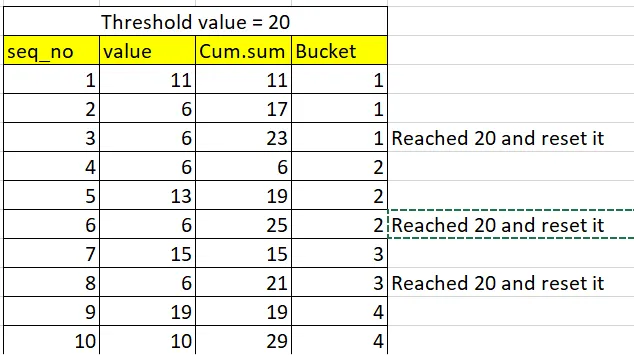
无法通过纯SQL找到解决方法,但这里有一个可行的plpgsql例程:
CREATE TABLE public.test(seq_no integer, val numeric);
INSERT INTO public.test(seq_no, val) VALUES (1, 11),(2, 6),(3, 6),(4, 6),(5, 13),(6, 6),(7, 15),(8, 6),(9, 19),(10, 10);
CREATE OR REPLACE FUNCTION public.test_cumolative_sum(arg_threshold integer)
RETURNS TABLE (seq_number integer, running_val NUMERIC, cum_sum NUMERIC, bucket integer)
LANGUAGE plpgsql AS
$$
DECLARE
var_table record;
var_cum_sum NUMERIC;
var_bucket integer;
BEGIN
var_cum_sum := 0;
var_bucket := 1;
FOR var_table IN SELECT seq_no, val FROM public.test ORDER BY seq_no LOOP
var_cum_sum := var_cum_sum + var_table.val;
RETURN query
SELECT
var_table.seq_no,
var_table.val,
var_cum_sum,
var_bucket;
IF var_cum_sum >= arg_threshold THEN
var_cum_sum := 0;
var_bucket := var_bucket + 1;
END IF;
END LOOP;
END;
$$;
SELECT * FROM public.test_cumolative_sum(20);