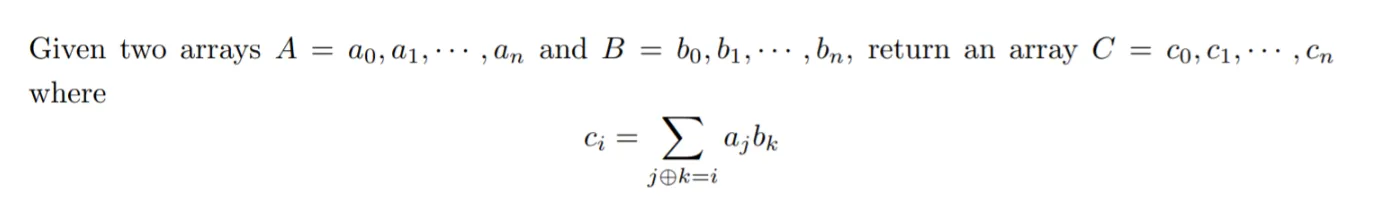我正在尝试解决这个 Hackerrank 的问题 https://www.hackerrank.com/challenges/xor-subsequence/problem。
但是由于它的时间复杂度为O(n^3),所以超时了。 我感觉有一些数学技巧,有人能解释一下解决方案吗?我尝试阅读了一些讨论中的解决方案,但是我没有完全理解。
考虑一个包含n个整数(A=a0,a1,...,an-1)的数组A。我们取数组中满足以下条件的所有连续子序列: {ai,ai+1,...,aj-1,aj},其中0≤i≤j≤n。
对于每个子序列,我们对所有整数应用按位异或(⊕)操作,并记录结果值。
给定数组A,找到A的每个子序列的异或和,并确定每个数字出现的频率。然后将数字和其相应的频率作为两个以空格分隔的值打印在同一行上。
输出格式:
在单独的一行上打印两个以空格分隔的整数。 第一个整数应该是具有最高频率的数字, 第二个整数应该是该数字的频率(即它出现的次数)。 如果有多个具有最大频率的数字, 选择最小的一个。
约束条件:
• 1≤n≤105 • 1≤ai<216
from functools import reduce
def xor_sum(arr):
return reduce(lambda x,y: x^y, arr)
def xorSubsequence(arr):
freq = {}
max_c = float("-inf") # init val
min_n = float("inf") # init val
for slice_size in range(1, len(arr)+1):
for step in range(0, len(arr)+1-slice_size):
n = xor_sum(arr[i] for i in range(step,step+slice_size))
freq[n] = freq.get(n,0)+1
if freq[n] >= max_c and (n < min_n or freq[n]> max_c):
min_n = n
max_c = freq[n]
return min_n, freq[min_n]
但是由于它的时间复杂度为O(n^3),所以超时了。 我感觉有一些数学技巧,有人能解释一下解决方案吗?我尝试阅读了一些讨论中的解决方案,但是我没有完全理解。
考虑一个包含n个整数(A=a0,a1,...,an-1)的数组A。我们取数组中满足以下条件的所有连续子序列: {ai,ai+1,...,aj-1,aj},其中0≤i≤j≤n。
对于每个子序列,我们对所有整数应用按位异或(⊕)操作,并记录结果值。
给定数组A,找到A的每个子序列的异或和,并确定每个数字出现的频率。然后将数字和其相应的频率作为两个以空格分隔的值打印在同一行上。
输出格式:
在单独的一行上打印两个以空格分隔的整数。 第一个整数应该是具有最高频率的数字, 第二个整数应该是该数字的频率(即它出现的次数)。 如果有多个具有最大频率的数字, 选择最小的一个。
约束条件:
• 1≤n≤105 • 1≤ai<216