有没有办法在C#中确定字符串的编码?
比如说,我有一个文件名字符串,但我不知道它是用Unicode UTF-16还是系统默认编码进行编码的,我该如何找出?
有没有办法在C#中确定字符串的编码?
比如说,我有一个文件名字符串,但我不知道它是用Unicode UTF-16还是系统默认编码进行编码的,我该如何找出?
Encoding.GetEncodings();查找完整的编码列表。// Function to detect the encoding for UTF-7, UTF-8/16/32 (bom, no bom, little
// & big endian), and local default codepage, and potentially other codepages.
// 'taster' = number of bytes to check of the file (to save processing). Higher
// value is slower, but more reliable (especially UTF-8 with special characters
// later on may appear to be ASCII initially). If taster = 0, then taster
// becomes the length of the file (for maximum reliability). 'text' is simply
// the string with the discovered encoding applied to the file.
public Encoding detectTextEncoding(string filename, out String text, int taster = 1000)
{
byte[] b = File.ReadAllBytes(filename);
//////////////// First check the low hanging fruit by checking if a
//////////////// BOM/signature exists (sourced from http://www.unicode.org/faq/utf_bom.html#bom4)
if (b.Length >= 4 && b[0] == 0x00 && b[1] == 0x00 && b[2] == 0xFE && b[3] == 0xFF) { text = Encoding.GetEncoding("utf-32BE").GetString(b, 4, b.Length - 4); return Encoding.GetEncoding("utf-32BE"); } // UTF-32, big-endian
else if (b.Length >= 4 && b[0] == 0xFF && b[1] == 0xFE && b[2] == 0x00 && b[3] == 0x00) { text = Encoding.UTF32.GetString(b, 4, b.Length - 4); return Encoding.UTF32; } // UTF-32, little-endian
else if (b.Length >= 2 && b[0] == 0xFE && b[1] == 0xFF) { text = Encoding.BigEndianUnicode.GetString(b, 2, b.Length - 2); return Encoding.BigEndianUnicode; } // UTF-16, big-endian
else if (b.Length >= 2 && b[0] == 0xFF && b[1] == 0xFE) { text = Encoding.Unicode.GetString(b, 2, b.Length - 2); return Encoding.Unicode; } // UTF-16, little-endian
else if (b.Length >= 3 && b[0] == 0xEF && b[1] == 0xBB && b[2] == 0xBF) { text = Encoding.UTF8.GetString(b, 3, b.Length - 3); return Encoding.UTF8; } // UTF-8
else if (b.Length >= 3 && b[0] == 0x2b && b[1] == 0x2f && b[2] == 0x76) { text = Encoding.UTF7.GetString(b,3,b.Length-3); return Encoding.UTF7; } // UTF-7
//////////// If the code reaches here, no BOM/signature was found, so now
//////////// we need to 'taste' the file to see if can manually discover
//////////// the encoding. A high taster value is desired for UTF-8
if (taster == 0 || taster > b.Length) taster = b.Length; // Taster size can't be bigger than the filesize obviously.
// Some text files are encoded in UTF8, but have no BOM/signature. Hence
// the below manually checks for a UTF8 pattern. This code is based off
// the top answer at: https://dev59.com/RGw15IYBdhLWcg3whMO_
// For our purposes, an unnecessarily strict (and terser/slower)
// implementation is shown at: https://dev59.com/13NA5IYBdhLWcg3wQ7e4
// For the below, false positives should be exceedingly rare (and would
// be either slightly malformed UTF-8 (which would suit our purposes
// anyway) or 8-bit extended ASCII/UTF-16/32 at a vanishingly long shot).
int i = 0;
bool utf8 = false;
while (i < taster - 4)
{
if (b[i] <= 0x7F) { i += 1; continue; } // If all characters are below 0x80, then it is valid UTF8, but UTF8 is not 'required' (and therefore the text is more desirable to be treated as the default codepage of the computer). Hence, there's no "utf8 = true;" code unlike the next three checks.
if (b[i] >= 0xC2 && b[i] < 0xE0 && b[i + 1] >= 0x80 && b[i + 1] < 0xC0) { i += 2; utf8 = true; continue; }
if (b[i] >= 0xE0 && b[i] < 0xF0 && b[i + 1] >= 0x80 && b[i + 1] < 0xC0 && b[i + 2] >= 0x80 && b[i + 2] < 0xC0) { i += 3; utf8 = true; continue; }
if (b[i] >= 0xF0 && b[i] < 0xF5 && b[i + 1] >= 0x80 && b[i + 1] < 0xC0 && b[i + 2] >= 0x80 && b[i + 2] < 0xC0 && b[i + 3] >= 0x80 && b[i + 3] < 0xC0) { i += 4; utf8 = true; continue; }
utf8 = false; break;
}
if (utf8 == true) {
text = Encoding.UTF8.GetString(b);
return Encoding.UTF8;
}
// The next check is a heuristic attempt to detect UTF-16 without a BOM.
// We simply look for zeroes in odd or even byte places, and if a certain
// threshold is reached, the code is 'probably' UF-16.
double threshold = 0.1; // proportion of chars step 2 which must be zeroed to be diagnosed as utf-16. 0.1 = 10%
int count = 0;
for (int n = 0; n < taster; n += 2) if (b[n] == 0) count++;
if (((double)count) / taster > threshold) { text = Encoding.BigEndianUnicode.GetString(b); return Encoding.BigEndianUnicode; }
count = 0;
for (int n = 1; n < taster; n += 2) if (b[n] == 0) count++;
if (((double)count) / taster > threshold) { text = Encoding.Unicode.GetString(b); return Encoding.Unicode; } // (little-endian)
// Finally, a long shot - let's see if we can find "charset=xyz" or
// "encoding=xyz" to identify the encoding:
for (int n = 0; n < taster-9; n++)
{
if (
((b[n + 0] == 'c' || b[n + 0] == 'C') && (b[n + 1] == 'h' || b[n + 1] == 'H') && (b[n + 2] == 'a' || b[n + 2] == 'A') && (b[n + 3] == 'r' || b[n + 3] == 'R') && (b[n + 4] == 's' || b[n + 4] == 'S') && (b[n + 5] == 'e' || b[n + 5] == 'E') && (b[n + 6] == 't' || b[n + 6] == 'T') && (b[n + 7] == '=')) ||
((b[n + 0] == 'e' || b[n + 0] == 'E') && (b[n + 1] == 'n' || b[n + 1] == 'N') && (b[n + 2] == 'c' || b[n + 2] == 'C') && (b[n + 3] == 'o' || b[n + 3] == 'O') && (b[n + 4] == 'd' || b[n + 4] == 'D') && (b[n + 5] == 'i' || b[n + 5] == 'I') && (b[n + 6] == 'n' || b[n + 6] == 'N') && (b[n + 7] == 'g' || b[n + 7] == 'G') && (b[n + 8] == '='))
)
{
if (b[n + 0] == 'c' || b[n + 0] == 'C') n += 8; else n += 9;
if (b[n] == '"' || b[n] == '\'') n++;
int oldn = n;
while (n < taster && (b[n] == '_' || b[n] == '-' || (b[n] >= '0' && b[n] <= '9') || (b[n] >= 'a' && b[n] <= 'z') || (b[n] >= 'A' && b[n] <= 'Z')))
{ n++; }
byte[] nb = new byte[n-oldn];
Array.Copy(b, oldn, nb, 0, n-oldn);
try {
string internalEnc = Encoding.ASCII.GetString(nb);
text = Encoding.GetEncoding(internalEnc).GetString(b);
return Encoding.GetEncoding(internalEnc);
}
catch { break; } // If C# doesn't recognize the name of the encoding, break.
}
}
// If all else fails, the encoding is probably (though certainly not
// definitely) the user's local codepage! One might present to the user a
// list of alternative encodings as shown here: https://dev59.com/wmoy5IYBdhLWcg3wfeMR
// A full list can be found using Encoding.GetEncodings();
text = Encoding.Default.GetString(b);
return Encoding.Default;
}
<= 0xF0更改为< 0xF0。为了保持一致性,即使代码是正确的,我也将上面的<= 0xDF更改为< 0xE0,下面的<= 0xF4也更改为< 0xF5。 - Dan W这取决于字符串的“来源”。.NET字符串是Unicode(UTF-16)格式的。除非你从数据库中读取数据到一个字节数组中,否则它不会出现不同的情况。
这篇CodeProject文章可能会引起兴趣:检测输入和输出文本的编码
Jon Skeet的C#和.NET中的字符串是对.NET字符串的很好解释。
/// <summary>
/// return the detected encoding and the contents of the file.
/// </summary>
/// <param name="fileName"></param>
/// <param name="contents"></param>
/// <returns></returns>
public static Encoding DetectEncoding(String fileName, out String contents)
{
// open the file with the stream-reader:
using (StreamReader reader = new StreamReader(fileName, true))
{
// read the contents of the file into a string
contents = reader.ReadToEnd();
// return the encoding.
return reader.CurrentEncoding;
}
}
Encoding.Default添加为StreamReader参数来修复后者,但这样代码就无法检测没有BOM的UTF8编码。 - Dan W还有一个选项,很晚才出现,抱歉:
http://www.architectshack.com/TextFileEncodingDetector.ashx
这个只使用C#语言编写的小类,如果有BOM(字节序标记)存在,则使用BOMS,否则尝试自动检测可能的Unicode编码,如果没有可用或可能的Unicode编码,则退而求其次。
听起来像是上面提到的UTF8Checker做的事情类似,但我认为它的范围略微广泛--除了UTF8之外,它还检查其他可能缺少BOM的Unicode编码(如UTF-16 LE或BE)。
希望这可以帮助某些人!
SimpleHelpers.FileEncoding Nuget 包将 Mozilla Universal Charset Detector 的 C# 移植版 封装成一个简单易用的 API:
var encoding = FileEncoding.DetectFileEncoding(txtFile);
我的解决方案是使用内置的东西以及一些备选方案。
我从stackoverflow上另一个类似问题的答案中选择了这种策略,但现在找不到它了。
它首先使用StreamReader中的内置逻辑检查BOM,如果有BOM,则编码将是除Encoding.Default之外的其他内容,我们应该信任该结果。
如果没有BOM,则检查字节序列是否为有效的UTF-8序列。如果是,则猜测编码为UTF-8,如果不是,则默认的ASCII编码将是结果。
static Encoding getEncoding(string path) {
var stream = new FileStream(path, FileMode.Open);
var reader = new StreamReader(stream, Encoding.Default, true);
reader.Read();
if (reader.CurrentEncoding != Encoding.Default) {
reader.Close();
return reader.CurrentEncoding;
}
stream.Position = 0;
reader = new StreamReader(stream, new UTF8Encoding(false, true));
try {
reader.ReadToEnd();
reader.Close();
return Encoding.UTF8;
}
catch (Exception) {
reader.Close();
return Encoding.Default;
}
}
/// <summary>
/// Reads a text file, and detects whether its encoding is valid UTF-8 or ascii.
/// If not, decodes the text using the given fallback encoding.
/// Bit-wise mechanism for detecting valid UTF-8 based on
/// https://ianthehenry.com/2015/1/17/decoding-utf-8/
/// </summary>
/// <param name="docBytes">The bytes read from the file.</param>
/// <param name="encoding">The default encoding to use as fallback if the text is detected not to be pure ascii or UTF-8 compliant. This ref parameter is changed to the detected encoding.</param>
/// <returns>The contents of the read file, as String.</returns>
public static String ReadFileAndGetEncoding(Byte[] docBytes, ref Encoding encoding)
{
if (encoding == null)
encoding = Encoding.GetEncoding(1252);
Int32 len = docBytes.Length;
// byte order mark for utf-8. Easiest way of detecting encoding.
if (len > 3 && docBytes[0] == 0xEF && docBytes[1] == 0xBB && docBytes[2] == 0xBF)
{
encoding = new UTF8Encoding(true);
// Note that even when initialising an encoding to have
// a BOM, it does not cut it off the front of the input.
return encoding.GetString(docBytes, 3, len - 3);
}
Boolean isPureAscii = true;
Boolean isUtf8Valid = true;
for (Int32 i = 0; i < len; ++i)
{
Int32 skip = TestUtf8(docBytes, i);
if (skip == 0)
continue;
if (isPureAscii)
isPureAscii = false;
if (skip < 0)
{
isUtf8Valid = false;
// if invalid utf8 is detected, there's no sense in going on.
break;
}
i += skip;
}
if (isPureAscii)
encoding = new ASCIIEncoding(); // pure 7-bit ascii.
else if (isUtf8Valid)
encoding = new UTF8Encoding(false);
// else, retain given encoding. This should be an 8-bit encoding like Windows-1252.
return encoding.GetString(docBytes);
}
/// <summary>
/// Tests if the bytes following the given offset are UTF-8 valid, and
/// returns the amount of bytes to skip ahead to do the next read if it is.
/// If the text is not UTF-8 valid it returns -1.
/// </summary>
/// <param name="binFile">Byte array to test</param>
/// <param name="offset">Offset in the byte array to test.</param>
/// <returns>The amount of bytes to skip ahead for the next read, or -1 if the byte sequence wasn't valid UTF-8</returns>
public static Int32 TestUtf8(Byte[] binFile, Int32 offset)
{
// 7 bytes (so 6 added bytes) is the maximum the UTF-8 design could support,
// but in reality it only goes up to 3, meaning the full amount is 4.
const Int32 maxUtf8Length = 4;
Byte current = binFile[offset];
if ((current & 0x80) == 0)
return 0; // valid 7-bit ascii. Added length is 0 bytes.
Int32 len = binFile.Length;
for (Int32 addedlength = 1; addedlength < maxUtf8Length; ++addedlength)
{
Int32 fullmask = 0x80;
Int32 testmask = 0;
// This code adds shifted bits to get the desired full mask.
// If the full mask is [111]0 0000, then test mask will be [110]0 0000. Since this is
// effectively always the previous step in the iteration I just store it each time.
for (Int32 i = 0; i <= addedlength; ++i)
{
testmask = fullmask;
fullmask += (0x80 >> (i+1));
}
// figure out bit masks from level
if ((current & fullmask) == testmask)
{
if (offset + addedlength >= len)
return -1;
// Lookahead. Pattern of any following bytes is always 10xxxxxx
for (Int32 i = 1; i <= addedlength; ++i)
{
if ((binFile[offset + i] & 0xC0) != 0x80)
return -1;
}
return addedlength;
}
}
// Value is greater than the maximum allowed for utf8. Deemed invalid.
return -1;
}
if ((current & 0xE0) == 0xC0) { ... } else if ((current & 0xF0) == 0xE0) { ... } else if ((current & 0xF0) == 0xE0) { ... } else if ((current & 0xF8) == 0xF0) { ... } 后面没有最后的 else 语句。我认为 else 情况将是无效的 utf8:isUtf8Valid = false;。你觉得呢? - hal /// <summary>
/// detect invalid characters in string, use to detect improper encoding
/// </summary>
/// <param name="s"></param>
/// <returns></returns>
public static bool DetectInvalidChars(string s)
{
const string specialChars = "\r\n\t .,;:-_!\"'?()[]{}&%$§=*+~#@|<>äöüÄÖÜß/\\^€";
return s.Any(ch => !(
specialChars.Contains(ch) ||
(ch >= '0' && ch <= '9') ||
(ch >= 'a' && ch <= 'z') ||
(ch >= 'A' && ch <= 'Z')));
}
注意:如果您需要考虑其他基于拉丁语的语言,请根据代码中的 specialChars 常量字符串进行调整。
然后我像这样使用它(我只期望 UTF-8 或默认编码):
// determine encoding by detecting invalid characters in string
var invoiceXmlText = Encoding.UTF8.GetString(invoiceXmlBytes); // try utf-8 first
if (StringFuncs.DetectInvalidChars(invoiceXmlText))
invoiceXmlText = Encoding.Default.GetString(invoiceXmlBytes); // fallback to default
这是一个使用C#构建的字符集检测器,适用于 .NET Core 2-3、.NET standard 1-2 和 .NET 4+。
它还是Mozilla Universal Charset Detector的一个移植版本,基于其他存储库。
CharsetDetector/UTF-unknown有一个名为CharsetDetector的类。
CharsetDetector包含一些静态编码检测方法:
CharsetDetector.DetectFromFile()CharsetDetector.DetectFromStream()CharsetDetector.DetectFromBytes()DetectionResult 中,具有属性 Detected,该属性是类 DetectionDetail 的实例,具有以下属性:
EncodingNameEncodingConfidence// Program.cs
using System;
using System.Text;
using UtfUnknown;
namespace ConsoleExample
{
public class Program
{
public static void Main(string[] args)
{
string filename = @"E:\new-file.txt";
DetectDemo(filename);
}
/// <summary>
/// Command line example: detect the encoding of the given file.
/// </summary>
/// <param name="filename">a filename</param>
public static void DetectDemo(string filename)
{
// Detect from File
DetectionResult result = CharsetDetector.DetectFromFile(filename);
// Get the best Detection
DetectionDetail resultDetected = result.Detected;
// detected result may be null.
if (resultDetected != null)
{
// Get the alias of the found encoding
string encodingName = resultDetected.EncodingName;
// Get the System.Text.Encoding of the found encoding (can be null if not available)
Encoding encoding = resultDetected.Encoding;
// Get the confidence of the found encoding (between 0 and 1)
float confidence = resultDetected.Confidence;
if (encoding != null)
{
Console.WriteLine($"Detection completed: {filename}");
Console.WriteLine($"EncodingWebName: {encoding.WebName}{Environment.NewLine}Confidence: {confidence}");
}
else
{
Console.WriteLine($"Detection completed: {filename}");
Console.WriteLine($"(Encoding is null){Environment.NewLine}EncodingName: {encodingName}{Environment.NewLine}Confidence: {confidence}");
}
}
else
{
Console.WriteLine($"Detection failed: {filename}");
}
}
}
}
示例结果截图: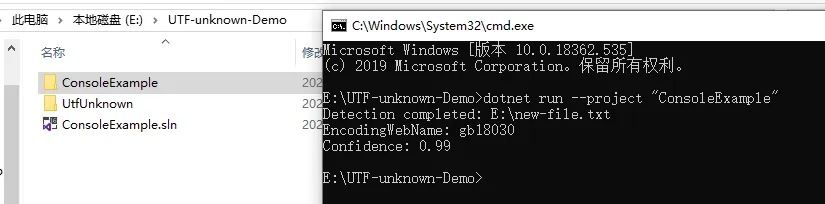
正如其他人所提到的,C#中的string始终以UTF-16LE编码(System.Text.Encoding.Unicode)。
在字里行间中,我认为您实际上关心的是您的string中的字符是否与某些其他已知编码兼容(即它们是否“适合”于该其他代码页?)。
在这种情况下,我发现最正确的解决方案是尝试转换并查看字符串是否更改。如果您的string中的字符不适合目标编码,则编码器将用一些哨兵字符替换它(例如“?”很常见)。
// using System.Text;
// And if you're using the "System.Text.Encoding.CodePages" NuGet package, you
// need to call this once or GetEncoding will raise a NotSupportedException:
// Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
var srcEnc = Encoding.Unicode;
var dstEnc = Encoding.GetEncoding(1252); // 1252 Requires use of the "System.Text.Encoding.CodePages" NuGet package.
string srcText = "Some text you want to check";
string dstText = dstEnc.GetString(Encoding.Convert(srcEnc, dstEnc, srcEnc.GetBytes(srcText)));
// if (srcText == dstText) the srcText "fits" (it's compatible).
// else the srcText doesn't "fit" (it's not compatible)