当从IDLE运行时(Python 3.2.5 - OS X 10.4.11 iBook G4 PPC),剪刀字符显示正常,并且该代码在Ubuntu 13.10上完全正常工作。但是当我尝试在终端中运行它时,我会得到以下错误/ traceback:
Traceback (most recent call last):
File "snippets-convert.py", line 352, in <module>
main()
File "snippets-convert.py", line 41, in main
menu()
File "snippets-convert.py", line 47, in menu
print ("|\t ",snipper.decode(),"PySnipt'd",snipper.decode(),"\t|")
UnicodeEncodeError: 'ascii' codec can't encode character '\u2702' in position 0: ordinal not in range(128)
下面是出现问题的代码:
print ("|\t ",chr(9986),"PySnipt'd",chr(9986),"\t|")
这不是表示终端无法显示该字符吗?我知道这是一个老系统,但它目前是我唯一要使用的系统。操作系统的年龄是否会干扰程序运行?
我阅读了以下问题:
"UnicodeEncodeError: 'ascii' codec can't encode character" - 使用2.6,所以不知道是否适用
UnicodeEncodeError: 'ascii' codec can't encode character? - 似乎是我问题的一个可行解决方案
.encode('UTF-8'),我没有收到错误。但是,它显示了一个字符代码而不是我想要的字符,并且.decode()仍然会出现相同的错误。不确定我是否做对了。UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-6: ordinal not in range(128) - 不确定是否适用,他正在使用GUI,获取输入并全部使用希腊语。
是什么原因导致这个错误?是系统/操作系统的年龄、Python版本还是某些编程错误?
编辑:此错误稍后出现了重复问题(只是想添加它,因为它在同一程序中并且是相同的错误):
Traceback (most recent call last):
File "snippets-convert.py", line 353, in <module>
main()
File "snippets-convert.py", line 41, in main
menu()
File "snippets-convert.py", line 75, in menu
main()
File "snippets-convert.py", line 41, in main
menu()
File "snippets-convert.py", line 62, in menu
search()
File "snippets-convert.py", line 229, in search
print_results(search_returned) # Print the results for the user
File "snippets-convert.py", line 287, in print_results
getPath(toRead) # Get the path for the snippet
File "snippets-convert.py", line 324, in getPath
snipXMLParse(path)
File "snippets-convert.py", line 344, in snipXMLParse
print (chr(164),child.text)
UnicodeEncodeError: 'ascii' codec can't encode character '\xa4' in position 0: ordinal not in range(128)
编辑:
我进入了终端字符设置,发现它确实支持该字符(如下图所示:
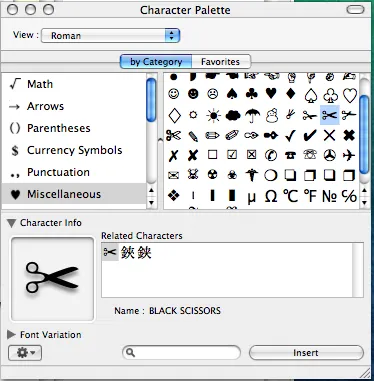
当我将其插入终端时,它输出:\342\234\202,当我按下Enter键后,它显示:-bash: ✂: command not found
编辑:按照@J.F. Sebastian的要求运行命令:
python3 test-io-encoding.py:
PYTHONIOENCODING: None
locale(False): US-ASCII
device(stdout): US-ASCII
stdout.encoding: US-ASCII
device(stderr): US-ASCII
stderr.encoding: US-ASCII
device(stdin): US-ASCII
stdin.encoding: US-ASCII
locale(False): US-ASCII
locale(True): US-ASCII
python3 -S test-io-encoding.py:
PYTHONIOENCODING: None
locale(False): US-ASCII
device(stdout): US-ASCII
stdout.encoding: US-ASCII
device(stderr): US-ASCII
stderr.encoding: US-ASCII
device(stdin): US-ASCII
stdin.encoding: US-ASCII
locale(False): US-ASCII
locale(True): US-ASCII
编辑 尝试了@PauloBu提供的“黑客式”解决方案:
正如您所看到的,这导致了一个(好极了!)剪刀,但现在我遇到了一个新的错误。跟踪/错误:
+-=============================-+
✂Traceback (most recent call last):
File "snippets-convert.py", line 357, in <module>
main()
File "snippets-convert.py", line 44, in main
menu()
File "snippets-convert.py", line 52, in menu
print("|\t "+sys.stdout.buffer.write(chr(9986).encode('UTF-8'))+" PySnipt'd "+ sys.stdout.buffer.write(chr(9986).encode('UTF-8'))+" \t|")
TypeError: Can't convert 'int' object to str implicitly
编辑:添加了@PauloBu的修复结果:
+-=============================-+
|
✂ PySnipt'd
✂ |
+-=============================-+
编辑:
他的修复方法如下:
+-=============================-+
✂✂| PySnipt'd |
+-=============================-+
b'\xe2\x9c\x82'- RPiAwesomeness