我有一个表示安全摄像机 NVR 元数据的数据库。对于每个 1 分钟的视频段,都有一个 26 字节的 recording 行。(如果你感兴趣,正在编写一份设计文档,在这里。)我的设计限制是 8 个摄像机,1 年 (~400 万行,每个摄像机约 50 万行)。我虚构了一些数据来测试性能。这个查询比我预期的要慢:
select
recording.start_time_90k,
recording.duration_90k,
recording.video_samples,
recording.sample_file_bytes,
recording.video_sample_entry_id
from
recording
where
camera_id = ?
order by
recording.start_time_90k;
这只是扫描所有摄像头的数据,使用索引来过滤其他摄像头并进行排序。索引看起来像这样:
create index recording_camera_start on recording (camera_id, start_time_90k);
explain query plan 看起来符合预期:
0|0|0|SEARCH TABLE recording USING INDEX recording_camera_start (camera_id=?)
行的大小相当小。
$ sqlite3_analyzer duplicated.db
...
*** Table RECORDING w/o any indices *******************************************
Percentage of total database...................... 66.3%
Number of entries................................. 4225560
Bytes of storage consumed......................... 143418368
Bytes of payload.................................. 109333605 76.2%
B-tree depth...................................... 4
Average payload per entry......................... 25.87
Average unused bytes per entry.................... 0.99
Average fanout.................................... 94.00
Non-sequential pages.............................. 1 0.0%
Maximum payload per entry......................... 26
Entries that use overflow......................... 0 0.0%
Index pages used.................................. 1488
Primary pages used................................ 138569
Overflow pages used............................... 0
Total pages used.................................. 140057
Unused bytes on index pages....................... 188317 12.4%
Unused bytes on primary pages..................... 3987216 2.8%
Unused bytes on overflow pages.................... 0
Unused bytes on all pages......................... 4175533 2.9%
*** Index RECORDING_CAMERA_START of table RECORDING ***************************
Percentage of total database...................... 33.7%
Number of entries................................. 4155718
Bytes of storage consumed......................... 73003008
Bytes of payload.................................. 58596767 80.3%
B-tree depth...................................... 4
Average payload per entry......................... 14.10
Average unused bytes per entry.................... 0.21
Average fanout.................................... 49.00
Non-sequential pages.............................. 1 0.001%
Maximum payload per entry......................... 14
Entries that use overflow......................... 0 0.0%
Index pages used.................................. 1449
Primary pages used................................ 69843
Overflow pages used............................... 0
Total pages used.................................. 71292
Unused bytes on index pages....................... 8463 0.57%
Unused bytes on primary pages..................... 865598 1.2%
Unused bytes on overflow pages.................... 0
Unused bytes on all pages......................... 874061 1.2%
...
我希望每次访问特定网页时都能运行类似于这样的功能(也许只有一个月的时间,而不是一整年),因此我希望它非常快速。但在我的笔记本电脑上,它需要大部分时间,而在我想要支持的 Raspberry Pi 2 上,则太慢了。下面是用秒表示的时间;它受限于 CPU(用户+系统时间 ~= 实际时间):
laptop$ time ./bench-profiled
trial 0: time 0.633 sec
trial 1: time 0.636 sec
trial 2: time 0.639 sec
trial 3: time 0.679 sec
trial 4: time 0.649 sec
trial 5: time 0.642 sec
trial 6: time 0.609 sec
trial 7: time 0.640 sec
trial 8: time 0.666 sec
trial 9: time 0.715 sec
...
PROFILE: interrupts/evictions/bytes = 1974/489/72648
real 0m20.546s
user 0m16.564s
sys 0m3.976s
(This is Ubuntu 15.10, SQLITE_VERSION says "3.8.11.1")
raspberrypi2$ time ./bench-profiled
trial 0: time 6.334 sec
trial 1: time 6.216 sec
trial 2: time 6.364 sec
trial 3: time 6.412 sec
trial 4: time 6.398 sec
trial 5: time 6.389 sec
trial 6: time 6.395 sec
trial 7: time 6.424 sec
trial 8: time 6.391 sec
trial 9: time 6.396 sec
...
PROFILE: interrupts/evictions/bytes = 19066/2585/43124
real 3m20.083s
user 2m47.120s
sys 0m30.620s
(This is Raspbian Jessie; SQLITE_VERSION says "3.8.7.1")
我可能最终会采用某种非规范化的数据,但我首先想看看能否让这个简单的查询尽可能地高效。我的基准测试非常简单;它提前准备好语句,然后循环执行以下操作:
void Trial(sqlite3_stmt *stmt) {
int ret;
while ((ret = sqlite3_step(stmt)) == SQLITE_ROW) ;
if (ret != SQLITE_DONE) {
errx(1, "sqlite3_step: %d (%s)", ret, sqlite3_errstr(ret));
}
ret = sqlite3_reset(stmt);
if (ret != SQLITE_OK) {
errx(1, "sqlite3_reset: %d (%s)", ret, sqlite3_errstr(ret));
}
}
我使用gperftools制作了一个CPU性能分析报告。图像:
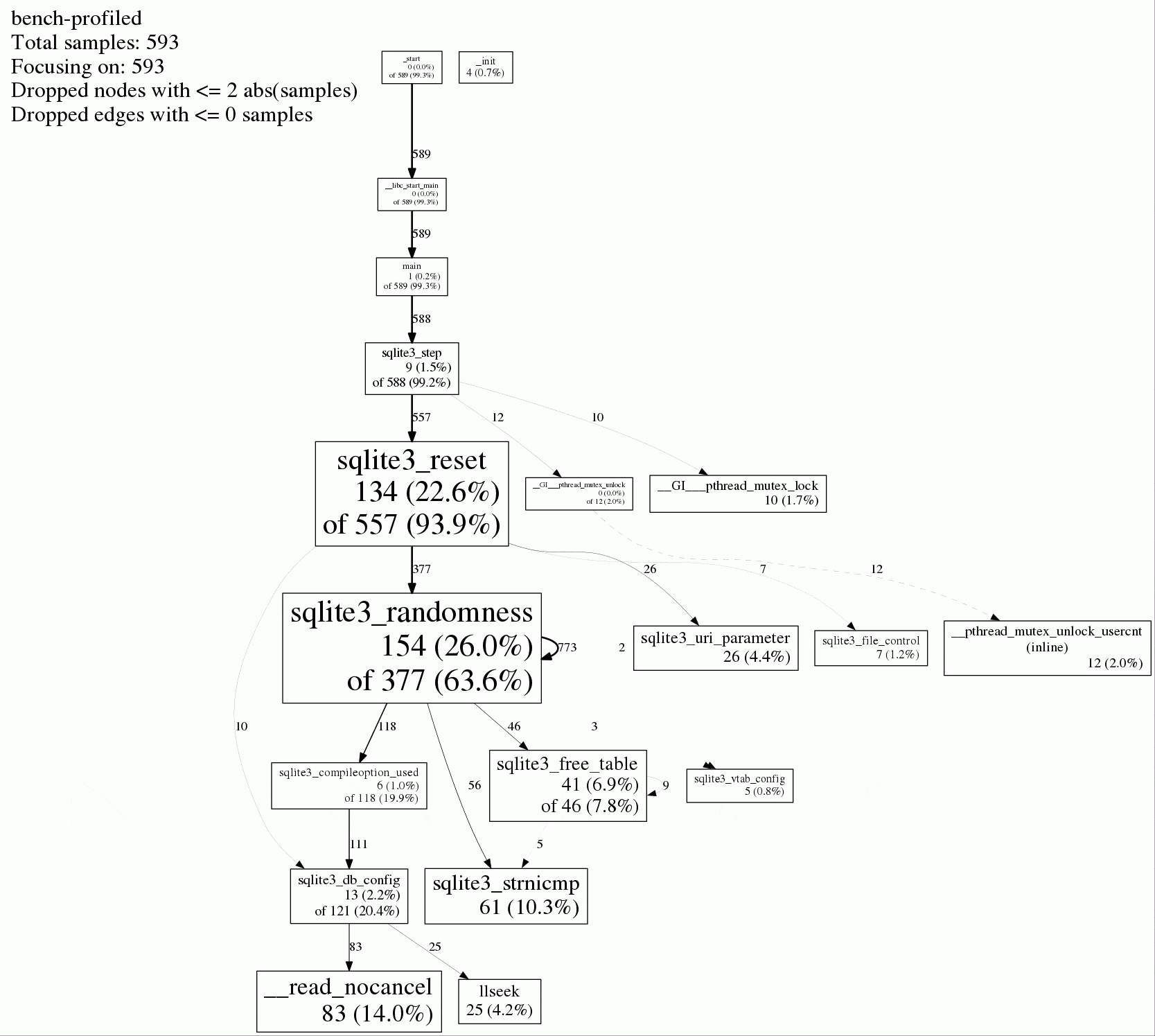
$ google-pprof bench-profiled timing.pprof
Using local file bench-profiled.
Using local file timing.pprof.
Welcome to pprof! For help, type 'help'.
(pprof) top 10
Total: 593 samples
154 26.0% 26.0% 377 63.6% sqlite3_randomness
134 22.6% 48.6% 557 93.9% sqlite3_reset
83 14.0% 62.6% 83 14.0% __read_nocancel
61 10.3% 72.8% 61 10.3% sqlite3_strnicmp
41 6.9% 79.8% 46 7.8% sqlite3_free_table
26 4.4% 84.1% 26 4.4% sqlite3_uri_parameter
25 4.2% 88.4% 25 4.2% llseek
13 2.2% 90.6% 121 20.4% sqlite3_db_config
12 2.0% 92.6% 12 2.0% __pthread_mutex_unlock_usercnt (inline)
10 1.7% 94.3% 10 1.7% __GI___pthread_mutex_lock
这看起来很奇怪,让我有希望它可以改进。也许我做了一些愚蠢的事情。我特别怀疑 sqlite3_randomness 和 sqlite3_strnicmp 操作:
- 文档说
sqlite3_randomness在某些情况下用于插入rowid,但我只是执行select查询。为什么现在要使用它?从浏览sqlite3源代码中,我发现它在sqlite3ColumnsFromExprList的选择中使用,但那似乎是准备语句时才会发生的事情。我只做一次,不在被基准测试的部分。 strnicmp用于不区分大小写的字符串比较。但此表中的每个字段都是整数。为什么要使用此函数?它在比较什么?- 总的来说,我不知道为什么
sqlite3_reset会很昂贵或者为什么它会从sqlite3_step调用。
模式:
-- Each row represents a single recorded segment of video.
-- Segments are typically ~60 seconds; never more than 5 minutes.
-- Each row should have a matching recording_detail row.
create table recording (
id integer primary key,
camera_id integer references camera (id) not null,
sample_file_bytes integer not null check (sample_file_bytes > 0),
-- The starting time of the recording, in 90 kHz units since
-- 1970-01-01 00:00:00 UTC.
start_time_90k integer not null check (start_time_90k >= 0),
-- The duration of the recording, in 90 kHz units.
duration_90k integer not null
check (duration_90k >= 0 and duration_90k < 5*60*90000),
video_samples integer not null check (video_samples > 0),
video_sync_samples integer not null check (video_samples > 0),
video_sample_entry_id integer references video_sample_entry (id)
);
我已将测试数据和测试程序打成tar包,你可以在这里下载。
编辑1:
哦,翻看SQLite代码,我发现了一个线索:
int sqlite3_step(sqlite3_stmt *pStmt){
int rc = SQLITE_OK; /* Result from sqlite3Step() */
int rc2 = SQLITE_OK; /* Result from sqlite3Reprepare() */
Vdbe *v = (Vdbe*)pStmt; /* the prepared statement */
int cnt = 0; /* Counter to prevent infinite loop of reprepares */
sqlite3 *db; /* The database connection */
if( vdbeSafetyNotNull(v) ){
return SQLITE_MISUSE_BKPT;
}
db = v->db;
sqlite3_mutex_enter(db->mutex);
v->doingRerun = 0;
while( (rc = sqlite3Step(v))==SQLITE_SCHEMA
&& cnt++ < SQLITE_MAX_SCHEMA_RETRY ){
int savedPc = v->pc;
rc2 = rc = sqlite3Reprepare(v);
if( rc!=SQLITE_OK) break;
sqlite3_reset(pStmt);
if( savedPc>=0 ) v->doingRerun = 1;
assert( v->expired==0 );
}
看起来sqlite3_step在模式更改时调用sqlite3_reset。(FAQ条目)尽管我的语句是预处理的,但我不知道为什么会有模式更改...
编辑2:
我下载了SQLite 3.10.1“ amalgation”并使用调试符号编译。现在我得到了一个非常不同的配置文件,看起来不那么奇怪,但速度并没有提高。也许我之前看到的奇怪结果是由于完全相同的代码折叠或其他原因。
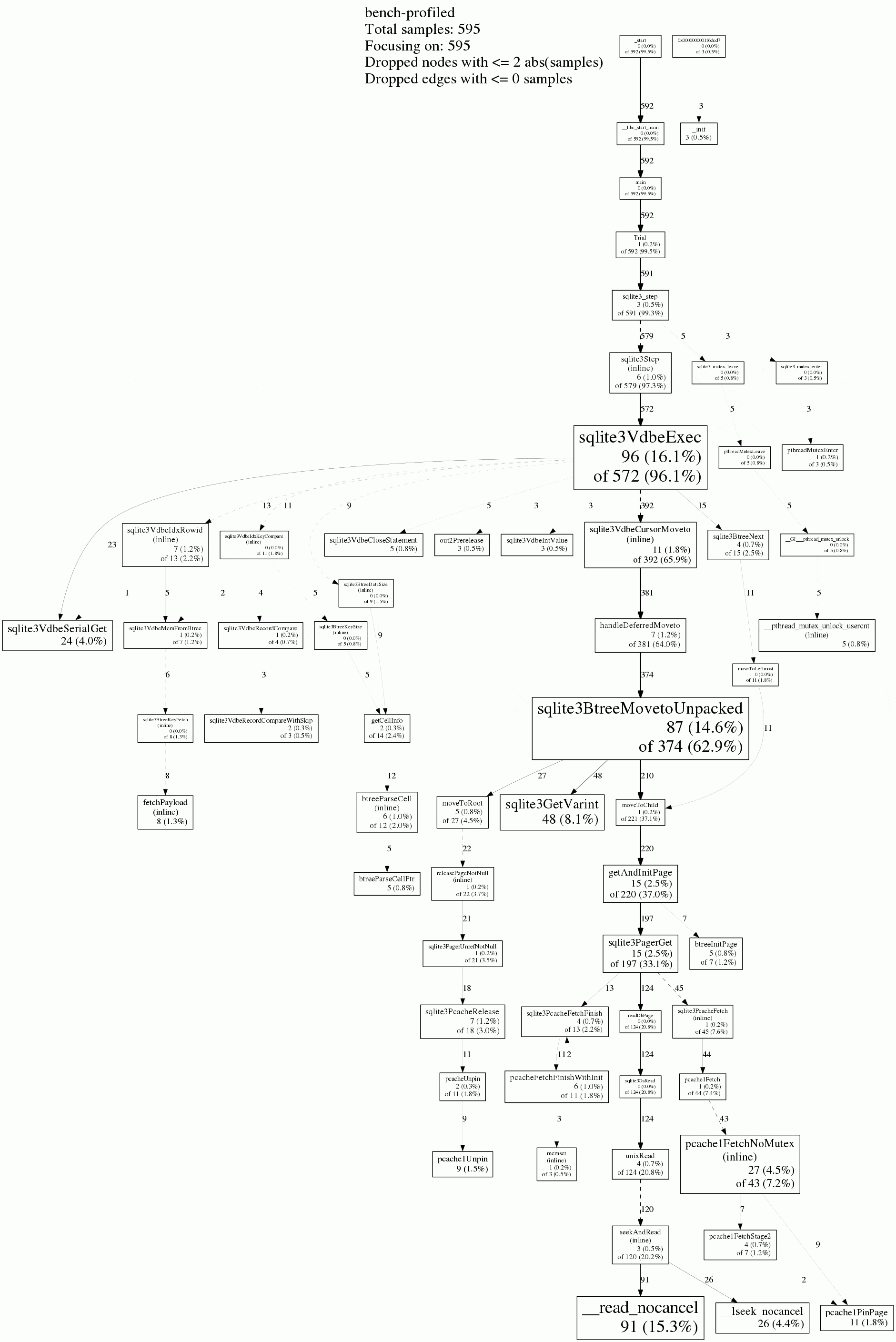
编辑3:
尝试Ben下面的聚集索引解决方案,速度约快3.6倍。我认为这是我可以在此查询中做到最好的了。 SQLite在我的笔记本电脑上的CPU性能大约为700 MB / s。除了重写以使用其虚拟机的JIT编译器之类的方法外,我不会做得更好。特别是,我认为我在第一个配置文件中看到的奇怪调用实际上并没有发生;由于优化或其他原因,gcc必须编写误导性的调试信息。
即使CPU性能得到提高,那种吞吐量也超过了我的存储器在冷读取时可以承受的范围,我认为Pi上也是如此(其具有有限的USB 2.0总线,用于SD卡)。
$ time ./bench
sqlite3 version: 3.10.1
trial 0: realtime 0.172 sec cputime 0.172 sec
trial 1: realtime 0.172 sec cputime 0.172 sec
trial 2: realtime 0.175 sec cputime 0.175 sec
trial 3: realtime 0.173 sec cputime 0.173 sec
trial 4: realtime 0.182 sec cputime 0.182 sec
trial 5: realtime 0.187 sec cputime 0.187 sec
trial 6: realtime 0.173 sec cputime 0.173 sec
trial 7: realtime 0.185 sec cputime 0.185 sec
trial 8: realtime 0.190 sec cputime 0.190 sec
trial 9: realtime 0.192 sec cputime 0.192 sec
trial 10: realtime 0.191 sec cputime 0.191 sec
trial 11: realtime 0.188 sec cputime 0.188 sec
trial 12: realtime 0.186 sec cputime 0.186 sec
trial 13: realtime 0.179 sec cputime 0.179 sec
trial 14: realtime 0.179 sec cputime 0.179 sec
trial 15: realtime 0.188 sec cputime 0.188 sec
trial 16: realtime 0.178 sec cputime 0.178 sec
trial 17: realtime 0.175 sec cputime 0.175 sec
trial 18: realtime 0.182 sec cputime 0.182 sec
trial 19: realtime 0.178 sec cputime 0.178 sec
trial 20: realtime 0.189 sec cputime 0.189 sec
trial 21: realtime 0.191 sec cputime 0.191 sec
trial 22: realtime 0.179 sec cputime 0.179 sec
trial 23: realtime 0.185 sec cputime 0.185 sec
trial 24: realtime 0.190 sec cputime 0.190 sec
trial 25: realtime 0.189 sec cputime 0.189 sec
trial 26: realtime 0.182 sec cputime 0.182 sec
trial 27: realtime 0.176 sec cputime 0.176 sec
trial 28: realtime 0.173 sec cputime 0.173 sec
trial 29: realtime 0.181 sec cputime 0.181 sec
PROFILE: interrupts/evictions/bytes = 547/178/24592
real 0m5.651s
user 0m5.292s
sys 0m0.356s
我可能需要保留一些非规范化的数据。幸运的是,我认为只要它不太大,启动速度不必惊人,并且只有一个进程会向数据库写入,我可以将其保存在我的应用程序的RAM中。