我希望你能够:
- 通过
time_create==last_timestamp条件筛选 df1, - 根据 df1 中选择的
store_product_id筛选 df2。
注意:请保留 HTML 标签。
这里我只是举例使用了df1,
按照时间创建进行选择很好:
df1[df1.time_create==last_timestamp].show()

然而,使用选定的store_product_id来过滤原始数据框df1给了我很多行。
df1[df1.store_product_id.isin(df1[df1.time_create==last_timestamp].store_product_id)].show()
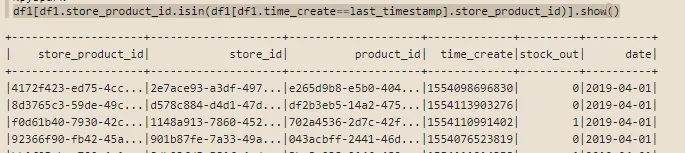
time_create==last_timestamp 匹配的 store_product_id 列表。ids = df1[df1.time_create==last_timestamp].select('store_product_id').collect()
df1[df1.store_product_id.isin(ids)].show()
但是出现了错误:
Py4JJavaError: An error occurred while calling z:org.apache.spark.sql.functions.lit.
: java.lang.RuntimeException: Unsupported literal type class java.util.ArrayList [01e8f3c0-3ad5-4b69-b46d-f5feb3cadd5f]
at org.apache.spark.sql.catalyst.expressions.Literal$.apply(literals.scala:78)
at org.apache.spark.sql.catalyst.expressions.Literal$$anonfun$create$2.apply(literals.scala:164)
at org.apache.spark.sql.catalyst.expressions.Literal$$anonfun$create$2.apply(literals.scala:164)
at scala.util.Try.getOrElse(Try.scala:79)
at org.apache.spark.sql.catalyst.expressions.Literal$.create(literals.scala:163)
at org.apache.spark.sql.functions$.typedLit(functions.scala:127)
at org.apache.spark.sql.functions$.lit(functions.scala:110)
at org.apache.spark.sql.functions.lit(functions.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.GatewayConnection.run(GatewayConnection.java:238)
at java.lang.Thread.run(Thread.java:748)
什么是正确的方式?
.select('store_product_id')替换为.select(['store_product_id'])? - ma3oun.select('store_product_id')已经可以正常工作。错误来自于df1[df1.store_product_id.isin(ids)]。看起来isin只接受 Python 的列表或元组。但是之前的代码甚至没有失败,非常奇怪。 - Mithrilids可能是以列表行数据结构的形式存在,我猜你需要一个值列表,所以使用toPandas而不是 collect,然后提取值列表。 - ags29