在 Ulrich Drepper 的 《每个程序员都应该了解的内存知识》 这篇论文中,第三部分:CPU 缓存,他展示了一张图表,显示了“工作集”大小与每个操作(本例中为顺序读取)消耗的 CPU 循环次数之间的关系。图表中有两个跳跃点,表示 L1 缓存和 L2 缓存的大小。我编写了自己的程序以在 C 语言中重现这种效果。它只是简单地从头到尾顺序读取一个 int[] 数组,并尝试了不同大小的数组(从 1KB 到 1MB)。我将数据绘制成一张图表,但没有跳跃,图表是一条直线。
我的问题是:
在main()函数中,我尝试了从1KB到100MB的数组大小,仍然相同,每个元素的平均耗时为2纳秒。我认为这个时间是L1d的访问时间。
我的缓存大小:
L1d == 32k
L2 == 256k
L3 == 6144k
最后,我将使用printf输出globalSum,以避免编译器优化。正如您所看到的,这仍然是一个顺序读取,我甚至尝试了高达500MB的数组大小,每个元素的平均时间约为4纳秒(可能是因为它必须访问数据“pad”和指针“n”,两个访问),与1KB的数组大小相同。因此,我认为这是因为缓存优化(如预取)很好地隐藏了延迟,我是正确的吗?我将尝试随机访问,并稍后发布结果。
我的问题是:
- 我的方法有问题吗?生产CPU缓存效果的正确方法是什么(以查看跳转)。
- 我在想,如果是顺序读取,那么它应该像这样操作:当读取第一个元素时,会发生缓存未命中,并且在缓存行大小(64K)内会出现命中。借助预取技术,将隐藏读取下一个缓存行的延迟。它将连续地读取数据到L1缓存中,即使工作集大小超过L1缓存大小,它也会驱逐最近最少使用的数据,并继续预取。因此,大多数缓存未命中将被隐藏,从L2获取数据所需的时间将被隐藏在读取活动背后,这意味着它们同时运行。关联性(在我的情况下为8路)将隐藏从L2读取数据的延迟。因此,我的程序现象应该是正确的,我错过了什么吗?
- 在Java中是否可能获得相同的效果?
顺便说一下,我是在Linux上进行这个操作的。
编辑1
感谢Stephen C的建议,以下是一些额外的信息: 这是我的代码:
int *arrayInt;
void initInt(long len) {
int i;
arrayInt = (int *)malloc(len * sizeof(int));
memset(arrayInt, 0, len * sizeof(int));
}
long sreadInt(long len) {
int sum = 0;
struct timespec tsStart, tsEnd;
initInt(len);
clock_gettime(CLOCK_REALTIME, &tsStart);
for(i = 0; i < len; i++) {
sum += arrayInt[i];
}
clock_gettime(CLOCK_REALTIME, &tsEnd);
free(arrayInt);
return (tsEnd.tv_nsec - tsStart.tv_nsec) / len;
}
在main()函数中,我尝试了从1KB到100MB的数组大小,仍然相同,每个元素的平均耗时为2纳秒。我认为这个时间是L1d的访问时间。
我的缓存大小:
L1d == 32k
L2 == 256k
L3 == 6144k
编辑 2
我已经更改了我的代码,使用了链表。
// element type
struct l {
struct l *n;
long int pad[NPAD]; // the NPAD could be changed, in my case I set it to 1
};
struct l *array;
long globalSum;
// for init the array
void init(long len) {
long i, j;
struct l *ptr;
array = (struct l*)malloc(sizeof(struct l));
ptr = array;
for(j = 0; j < NPAD; j++) {
ptr->pad[j] = j;
}
ptr->n = NULL;
for(i = 1; i < len; i++) {
ptr->n = (struct l*)malloc(sizeof(struct l));
ptr = ptr->n;
for(j = 0; j < NPAD; j++) {
ptr->pad[j] = i + j;
}
ptr->n = NULL;
}
}
// for free the array when operation is done
void release() {
struct l *ptr = array;
struct l *tmp = NULL;
while(ptr) {
tmp = ptr;
ptr = ptr->n;
free(tmp);
}
}
double sread(long len) {
int i;
long sum = 0;
struct l *ptr;
struct timespec tsStart, tsEnd;
init(len);
ptr = array;
clock_gettime(CLOCK_REALTIME, &tsStart);
while(ptr) {
for(i = 0; i < NPAD; i++) {
sum += ptr->pad[i];
}
ptr = ptr->n;
}
clock_gettime(CLOCK_REALTIME, &tsEnd);
release();
globalSum += sum;
return (double)(tsEnd.tv_nsec - tsStart.tv_nsec) / (double)len;
}
最后,我将使用printf输出globalSum,以避免编译器优化。正如您所看到的,这仍然是一个顺序读取,我甚至尝试了高达500MB的数组大小,每个元素的平均时间约为4纳秒(可能是因为它必须访问数据“pad”和指针“n”,两个访问),与1KB的数组大小相同。因此,我认为这是因为缓存优化(如预取)很好地隐藏了延迟,我是正确的吗?我将尝试随机访问,并稍后发布结果。
编辑3
我尝试了对链表进行随机访问,这是结果:
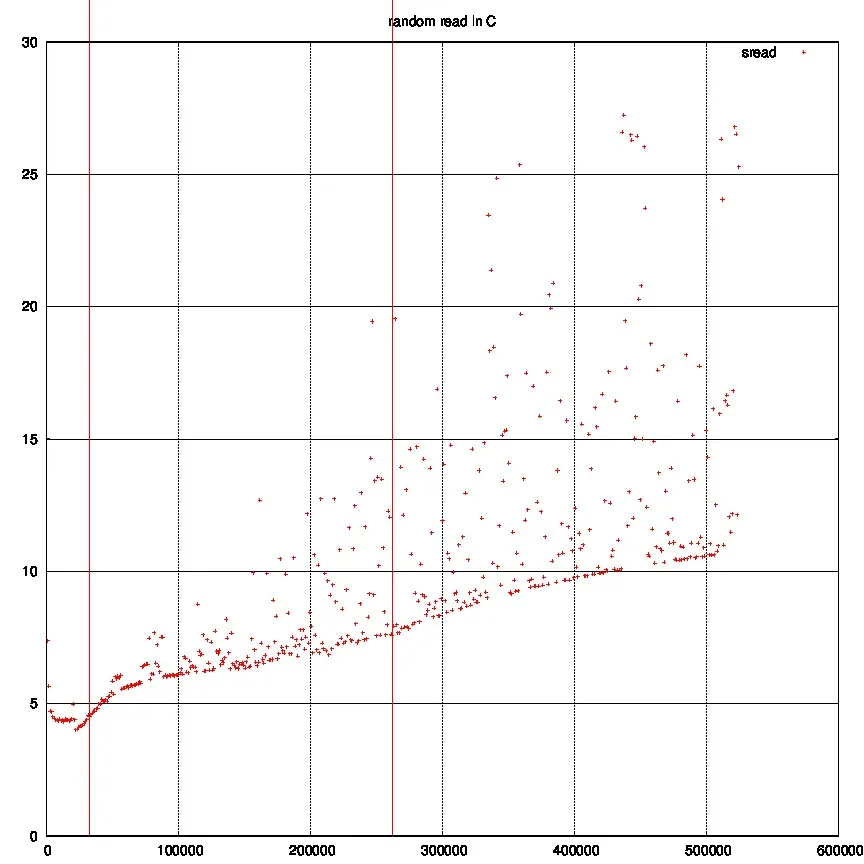
第一条红线是我的L1缓存大小,第二条是L2。因此我们可以看到有一点跳跃。有时延迟仍然被很好地隐藏。
main()函数中调用了多少次sreadInt()函数?这很关键——只有当你多次读取内存位置时,缓存才能为你带来好处! - j_random_hackermemset()写入了每个位置...不确定是否具有预热缓存的相同效果,但我怀疑它会。在任何情况下,多次调用sreadInt()是值得尝试的。 - j_random_hacker