计算具有大量数据的表可能非常缓慢,有时需要几分钟; 在繁忙的服务器上还可能产生死锁。我想显示实际值,NOLOCK不是一个选项。
我使用的服务器是SQL Server 2005或2008标准版或企业版-如果有关系的话。 我可以想象SQL Server维护每个表的计数,如果没有WHERE子句,我可以很快地得到那个数字,对吗?
举例来说:
SELECT COUNT(*) FROM myTable
应该立即以正确的值返回。我需要依赖更新的统计数据吗?
计算具有大量数据的表可能非常缓慢,有时需要几分钟; 在繁忙的服务器上还可能产生死锁。我想显示实际值,NOLOCK不是一个选项。
我使用的服务器是SQL Server 2005或2008标准版或企业版-如果有关系的话。 我可以想象SQL Server维护每个表的计数,如果没有WHERE子句,我可以很快地得到那个数字,对吗?
举例来说:
SELECT COUNT(*) FROM myTable
应该立即以正确的值返回。我需要依赖更新的统计数据吗?
SELECT SUM(p.rows) FROM sys.partitions AS p
INNER JOIN sys.tables AS t
ON p.[object_id] = t.[object_id]
INNER JOIN sys.schemas AS s
ON s.[schema_id] = t.[schema_id]
WHERE t.name = N'myTable'
AND s.name = N'dbo'
AND p.index_id IN (0,1);
COUNT(*) 快得多,如果您的表正在快速更改,则实际上并不会更不准确 - 如果在您开始计数时(并且已获取锁定)和返回计数时(当释放锁定并允许所有等待写入事务写入表时)表已更改,那么它更有价值吗?我认为不是。WHERE some_column IS NULL),则可以在该列上创建一个过滤索引,并根据情况构造 where 子句,具体取决于其是异常还是规则(因此在较小的集合上创建过滤索引)。因此,这两个索引之一:CREATE INDEX IAmTheException ON dbo.table(some_column)
WHERE some_column IS NULL;
CREATE INDEX IAmTheRule ON dbo.table(some_column)
WHERE some_column IS NOT NULL;
然后您可以使用类似的方式获取计数:
SELECT SUM(p.rows) FROM sys.partitions AS p
INNER JOIN sys.tables AS t
ON p.[object_id] = t.[object_id]
INNER JOIN sys.schemas AS s
ON s.[schema_id] = t.[schema_id]
INNER JOIN sys.indexes AS i
ON p.index_id = i.index_id
WHERE t.name = N'myTable'
AND s.name = N'dbo'
AND i.name = N'IAmTheException' -- or N'IAmTheRule'
AND p.index_id IN (0,1);
“大量数据”指的是多大的数据量?- 应该先评论一下这个问题,但也许下面的代码会帮助你。
如果我在我的开发机器上(使用Oracle),查询一个静态表(意味着相当长一段时间内没有其他人进行读/写/更新,因此争用不是一个问题)的 2 亿行数据并在 15 秒内 COUNT(*),考虑到数据量的纯粹数量,这仍然相当快(至少对我来说是这样)。
正如你所说,NOLOCK 不是一个选项,你可以考虑……
exec sp_spaceused 'myTable'
但这几乎与NOLOCK相同(忽略争用+删除/更新,据我所知)。
我使用SSMS已经十多年了,但是在过去的一年中才发现它可以通过这个答案快速、轻松地提供这些信息。
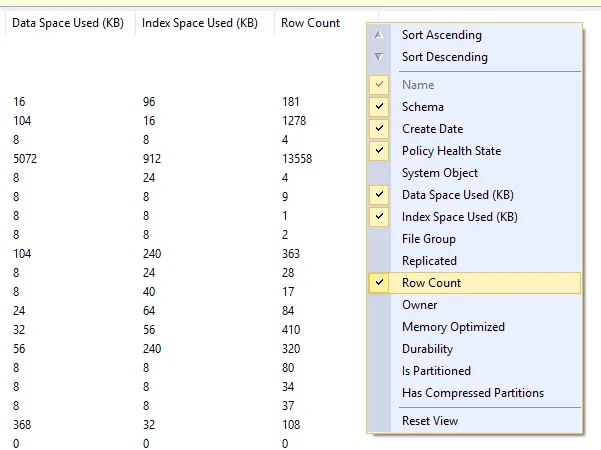
请注意,在Azure SQL数据库中对此的支持似乎最好是稀疏的 - 我猜测是来自SSMS的查询超时,因此每次刷新只返回少量表,但始终返回突出显示的表。
Count会执行表扫描或索引扫描。因此,对于大量行,它将变得很慢。如果您经常执行此操作,则最好的方法是在另一个表中保留计数记录。
但是,如果您不想这样做,可以创建一个虚拟索引(不会被查询使用),并查询其项目数量,例如:
select
row_count
from sys.dm_db_partition_stats as p
inner join sys.indexes as i
on p.index_id = i.index_id
and p.object_id = i.object_id
where i.name = 'your index'
MySQL> connect information_schema;
MySQL> select table_name,table_rows from tables;
SELECT COUNT直接查询表而不使用统计数据,因为统计数据可能已过期) - JustinId(bigint,主键,标识规范=true),它仍然很慢。 - ANeves