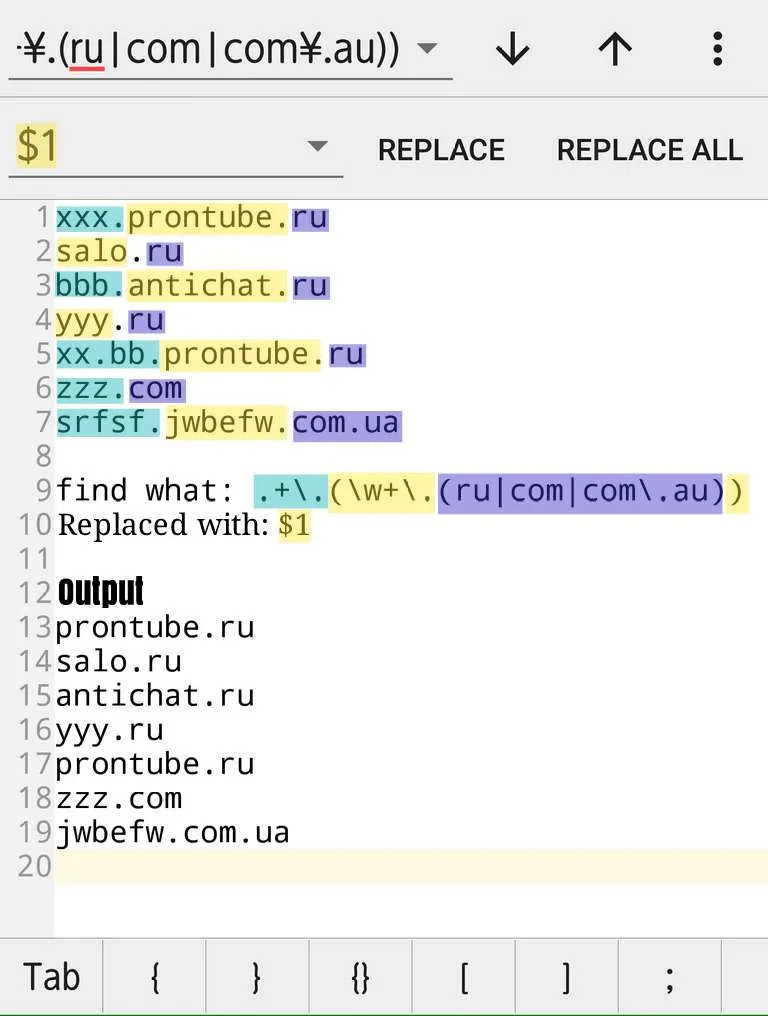
.+?\.([\w-]*?\.(?:ru|ua|com\.ua|com|net|info))$
这个答案仍然使用了原始问题所涉及的特定域名。由于某些顶级域名(TLD)中含有句点,并且您可以理论上包括多个子域,因此如果它适用于您的数据集,则在正则表达式中列出白名单的TLD是一个好主意。两个当前答案(从2013年起)都无法正确处理“xx.bb.prontube.ru”和“srfsf.jwbefw.com.ua”之间的区别。
以下是为什么此psnig的原始正则表达式未按预期工作的简要说明:
+ 是贪婪模式。
.+ 将一直向右滑动到行末捕获所有内容,
然后向后(向左)工作,从这里寻找匹配项:
(ru|ua|com\.ua|com|net|info)
使用
srfsf.jwbefw.com.ua,正则表达式引擎首先无法匹配
a,
然后它将令牌向左移动一个位置以查看 "ua"。
此时,来自正则表达式的
ua(第二个选项)是匹配项。
引擎不会继续寻找 "com.ua",因为 ".ua" 满足了该要求。
Niet the Dark Absol 的答案告诉正则表达式要“懒惰”
.+? 将匹配任何字符(至少一个),然后尝试查找正则表达式的下一部分。如果失败,则它将推进令牌,
.+ 匹配一个或多个字符,然后再次评估其余的正则表达式。
最终,.+? 将消耗:
srfsf.jwbefw,然后匹配句点,然后匹配
com.ua。
但是添加问号会使第一个 .+ 变成懒惰模式,但随后导致 group1 匹配
bb.prontube.ru而不是
prontube.ru。
这是因为在bb之后第一个句号会匹配,然后在第一组
(.*?)中匹配
bb.prontube。在
\.(ru|ua|com\.ua|com|net|info))$之前匹配
.ru。
为了避免这种情况,将第三组从
(.*?)更改为
([\w-]*?),这样就不会捕获
。只有字母、数字或破折号。
结果的正则表达式:
.+?\.(([\w-])*?\.(ru|ua|com\.ua|com|net|info))$
请注意,除了第一组外,您不需要捕获任何其他组。添加?:可以使TLD选项不捕获。
最后更改:
.+?\.([\w-]*?\.(?:ru|ua|com\.ua|com|net|info))$