你的问题是如何计算哪些城市最相关?例如,如果我正在查看城市1(巴黎),结果应该是:伦敦(2),纽约(3)。根据你提供的数据集,唯一需要关联的是城市之间的共同标签,因此共享相同标签的城市会更接近。以下是子查询,用于查找共享公共标签的城市(除了提供的城市以外)。
SELECT * FROM `cities` WHERE id IN (
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
工作中
我假设你会输入城市的id或名称来查找它们最接近的城市,在我的案例中,“巴黎”有id为1。
SELECT tag_id FROM `cities_tags` WHERE city_id=1
它将找到所有带有“paris” id 的标签。
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
它将获取除巴黎外所有具有与巴黎相同标签的城市。
这是您的
Fiddle。
在阅读关于Jaccard相似性/指数的内容时,发现了一些需要理解的东西,让我们以这个例子来说明,我们有两个集合A和B。
集合A={A,B,C,D,E}
集合B={I,H,G,F,E,D}
计算Jaccard相似性的公式为JS=(A intersect B)/(A
union B)
A intersect B = {D,E}= 2
A union B ={A, B, C, D, E,I, H, G, F} =9
JS=2/9 =0.2222222222222222
现在转向您的情况。
巴黎有标签id 1,3,因此我们将其集合并称为P = {欧洲,河流}
伦敦有标签id 1,3,因此我们将其集合并称为L = {欧洲,河流}
纽约有标签id 2,3,因此我们将其集合并称为NW = {北美,河流}
计算巴黎与伦敦的Jaccard相似度JSPL = P交L / P并L,JSPL = 2/2 = 1
计算巴黎与纽约的Jaccard相似度JSPNW = P交NW / P并NW,JSPNW = 1/3 = 0.3333333333
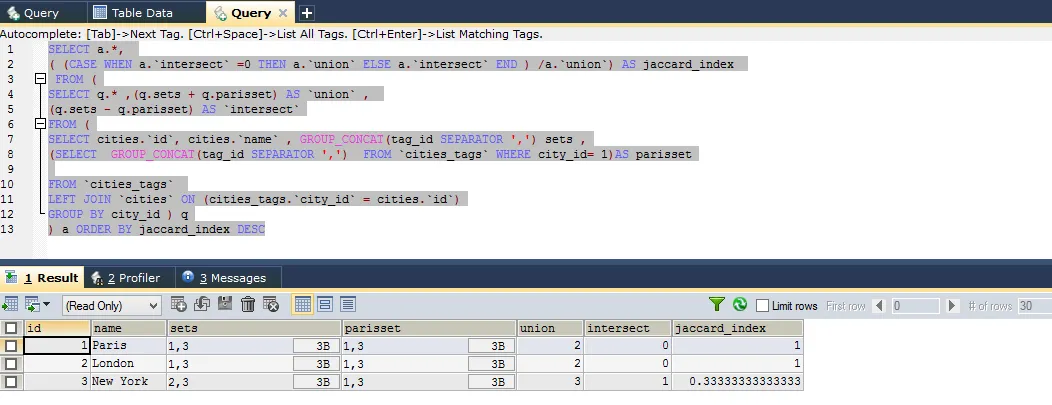
目前查询已经能够计算出完美的Jaccard指数,您可以在下面的fiddle示例中查看。
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`)
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
在上述查询中,我将结果集派生为两个子查询,以获取我的自定义计算别名。
你可以在上述查询中添加过滤器,以避免计算与自身的相似度。
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`) WHERE cities.`id` !=1
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
因此,结果显示巴黎与伦敦密切相关,然后与纽约相关。
Jaccard相似性演示