我正在尝试从文本文件中获取特定的一行。
到目前为止,我只看到过像sed这样的东西(我只能使用sh -不是bash或sed或类似的东西)。我需要使用基本的shell脚本来完成这个任务。
cat file | while read line
do
#do something
done
我知道如何通过上面所示的方法遍历行,但如果我只需要获取特定行内容怎么办
sed:
sed '5!d' file
awk:
awk 'NR==5' file
5!d 表示删除除第五行以外的所有行。可以使用shell变量,但必须使用双引号。 - Kentsed -n 5p。对于新手来说,这似乎更容易记住,因为-n表示“默认情况下不输出”,而 p代表“打印”,没有可能引起混淆的删除提到(当人们谈论文件时,删除行往往意味着不同的事情)。 - Josip Rodin-n '5p' 对于这个问题也可以解决。不同之处在于,使用 5!d 可以添加 -i 将更改写回文件。然而,使用 -n 5p 你必须再次执行 sed -n '5p' f > f2&& mv f2 f,对于这个问题,我同意你的观点。 - Kent假设line是一个保存所需行号的变量,如果你可以使用head和tail,那么这很简单:
head -n $line file | tail -1
如果不行,这个应该可以起作用:
x=0
want=5
cat lines | while read line; do
x=$(( x+1 ))
if [ $x -eq "$want" ]; then
echo $line
break
fi
done
-eq比较是针对整数的,所以它需要一个行号,而不是行内容($line)。必须通过在循环之前定义例如want=5,然后在$want上使用-eq比较来修复此问题。[从被拒绝的编辑中移动] - Josip Rodinsed显然更快,但它并不能回答这个问题。如果你错过了,问题明确说明sed不可用,而sh是唯一可用的工具。 - micromoses您可以使用 sed -n 5p 文件 来获取文件的第五行。
您也可以获取一个范围,例如 sed -n 5,10p 文件 可以获取文件的第五到第十行。
grep -C中一样?这样可以方便地查找源代码中的错误。 - undefined最佳表现方法
sed '5q;d' file
由于 sed 在第五行之后停止读取任何行。
更新自Roger Dueck先生的实验
我安装了 wcanadian-insane(6.6MB),并使用 time 命令比较了 sed -n 1p /usr/share/dict/words 和 sed '1q;d' /usr/share/dict/words 的性能;前者花费了 0.043 秒,而后者只需 0.002 秒,因此使用 'q' 明显提高了性能!
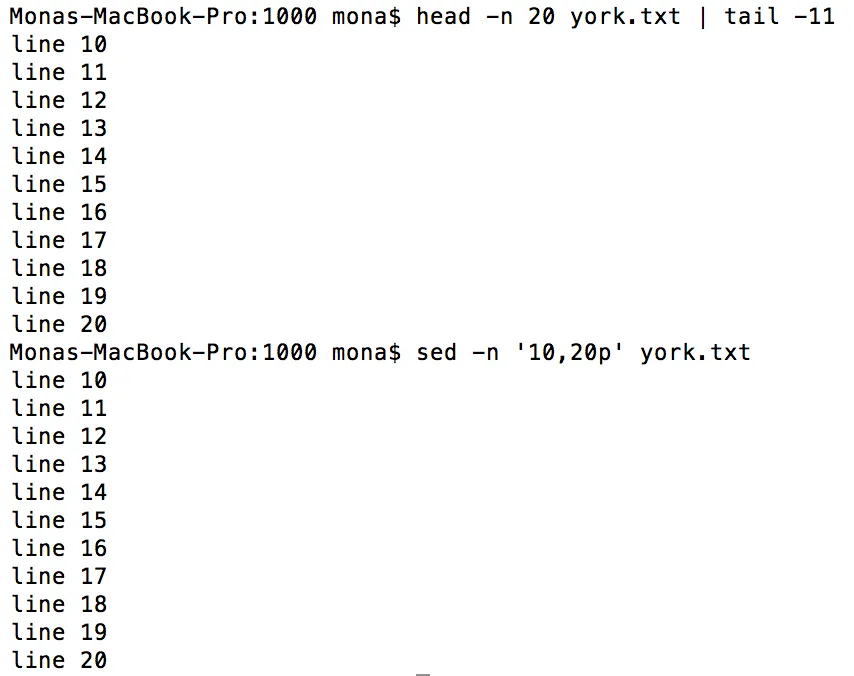
sed -n 5q。 - William Pursellsed在第五行后停止读取任何行。 - Anthony Geoghegantime命令比较了sed -n 1p /usr/share/dict/words和sed '1q;d' /usr/share/dict/words。第一个命令花费了0.043秒,而第二个命令只需要0.002秒,因此使用“q”肯定是一种性能提升! - Roger Dueckq 命令会导致 broken pipe。在这种情况下,必须采用 sed -n 5p。 - steveslivased -n 5q 对我来说什么也没打印出来。我认为答案给出的 sed -n '5{p;q}' 是最好的变体,但我也可以使用它。 - jmouhead -n 20 york.txt | tail -11
sed -n '10,20p' york.txt
p在上面的命令中代表打印。
你会看到以下内容:
sed 命令。sed -n '5p' filename #get the 5th line and prints the value (p stands for print)
sed -n '1,5p' filename #get the 1 to 5th line and prints the values
sed -n '1p;5p;' filename #get the 1st and 5th line values only
处理这种任务的标准方法是使用外部工具。在编写shell脚本时禁止使用外部工具是荒谬的。但是,如果您真的不想使用外部工具,可以使用以下代码打印第5行:
i=0; while read line; do test $((++i)) = 5 && echo "$line"; done < input-file
input-file包含行继续符,则它们将被视为单个行。您可以通过在读取命令中添加-r来更改此行为。(这可能是期望的行为。)$((i+=1)) 这样的简单解决方法在 Dash 中也可以使用。 - tripleee$(($i+1))是我想到的简单解决方法。 - Josip Rodin我并不特别喜欢任何一个答案。
以下是我的做法。
# Convert the file into an array of strings
lines=(`cat "foo.txt"`)
# Print out the lines via array index
echo "${lines[0]}"
echo "${lines[1]}"
echo "${lines[5]}"
#!/bin/bash
for i in {1..50}
do
line=$(sed "${i}q;d" file.txt)
echo $line
done
假设这个问题是针对bash的,以下就是最快最简单的方式。
readarray -t a <file ; echo ${a[5-1]}
当不再需要数组a时,您可以将其丢弃。
cat可以,但是sed不行?这毫无意义。 - William Pursell