递归就像你展示的那样。如果函数A调用A,或者A调用B并且B调用A,那么这就是递归。
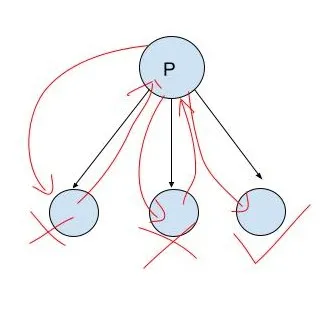
回溯不是一个算法,而是一种控制结构。使用回溯时,程序似乎能够向后运行。在编写类似国际象棋游戏的程序时非常有用,因为您想要预测几步。当程序想要进行移动时,它选择一种移动方式,然后切换到其镜像对手程序,该程序选择一种移动方式,以此类推。如果初始程序到达“好位置”,它希望说“耶”并执行它所做的第一步。如果任何程序到达“坏位置”,它都希望退出并尝试另一种移动方式。
您可以将此视为搜索树,但如果移动选择很复杂,则将其视为程序“备份”到上次选择移动的最后位置,选择不同的移动方式,然后再次前进可能更直观。
好了,如果这个想法有吸引力,怎么做呢?
首先,您需要一种表示选择(选择移动)的语句,您可以“备份”到并修改您的选择。
其次,在像A;B这样的一系列语句中,您将A设置为一个函数,并传递一个能够执行B的函数。类似于A(lambda()B(...))。因此,在A执行完成之前,它在返回之前调用其调用B的函数。
如果A想要“失败”并开始“向后运行”,它只需返回而不调用调用B的函数。
我知道这很难理解。我已经通过LISP中的宏来实现它,并且效果很好。在像C++这样的普通编译器语言中进行操作非常困难。
我已经在C/C++中完成了类似的操作,以保留“漂亮性”,但实际上并没有向后运行。
这个想法是您正在执行某种深度优先搜索树的操作。
但是,您可以将其作为从树的根部进行的一系列“刺”,每次“刺”都按不同的路径进行。
这可能会因性能问题而受到反对,但实际上并没有太多的成本,因为大部分工作发生在树的叶子上。如果树有3层深度,并且每个节点的分支因子为5,则意味着它有5 + 25 + 125或155个节点。但是在从根部进行的一系列“刺”中,它访问了125 * 3 = 375个节点,性能损失不到3倍,这可能是可以接受的,除非性能真正成为问题。 (请记住,真正的回溯可能涉及相当多的机制,生成lambda等。)
以下是我使用的基本代码:
#define NLEVEL 20
int ia[NLEVEL];
int na[NLEVEL];
int iLevel = 0;
int choose(int n){
if (ilevel >= ns){ na[ns]=n; ia[ns]=0; ns++; }
return ia[ilevel++];
}
void step(){
while (ns > 0){
if (++ia[ns-1] >= na[ns-1]) ns--;
else break;
}
}
bool search(int iLevel){
iLevel++;
switch(choose(2)){
break; case 0:;
break; case 1:
return search(iLevel);
}
return true;
}
void running(){
ns = 0;
do {
bool bSuccess = search(0);
if (bSuccess){
break;
}
step();
} while(ns > 0);
}
我使用这段代码来构建一个自制的定理证明器,取代了search函数。
ar甚至没有被定义。 - Asherah