您需要指定
source_dir。然后在您的脚本中,您可以像平常一样导入模块。
source_dir(str或PipelineVariable)-路径(绝对路径、相对路径或S3 URI),指向除入口文件以外的任何其他训练源代码依赖项的目录(默认值:无)。如果source_dir是S3 URI,则它必须指向tar.gz文件。在Amazon SageMaker上训练时,保留此目录内的结构。
请参阅处理的
一般文档(您必须使用
FrameworkProcessor而不是特定的处理器,如SKLearnProcessor)。
附注:答案类似于问题“
如何在sagemaker管道中安装其他软件包”。
在指定的文件夹中,必须有脚本(在您的情况下为preprocess.py)、可能需要的任何其他文件/模块,以及requirements.txt文件(如果有)。
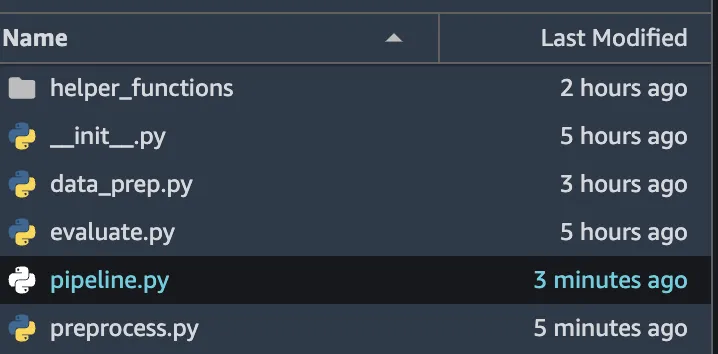
然后文件夹的结构将是:
BASE_DIR/
|─ helper_functions/
| |─ your_utils.py
|─ requirements.txt
|─ preprocess.py
在您的preprocess.py文件中,您可以通过简单地调用脚本来运行它们:
from helper_functions.your_utils import your_class, your_func
因此,你的代码变成了:
from sagemaker.processing import FrameworkProcessor
from sagemaker.sklearn import SKLearn
from sagemaker.workflow.steps import ProcessingStep
from sagemaker.processing import ProcessingInput, ProcessingOutput
BASE_DIR = your_script_dir_path
sklearn_processor = FrameworkProcessor(
estimator_cls=SKLearn,
framework_version=framework_version,
instance_type=processing_instance_type,
instance_count=processing_instance_count,
base_job_name=base_job_name,
sagemaker_session=pipeline_session,
role=role
)
step_args = sklearn_processor.run(
inputs=[your_inputs],
outputs=[your_outputs],
code="preprocess.py",
source_dir=BASE_DIR,
arguments=[your_arguments],
)
step_process = ProcessingStep(
name="ProcessingName",
step_args=step_args
)
将各个步骤的文件夹分开并避免重叠是一个良好的实践。