我相信我一定能够达到130 FPS的速度。
...甚至Quake2运行得更快
我必须承认,我的灵感来自OpenGL——它有几个部分与之相似(至少是我认为它可能会工作的方式),并进行了一些简化。
我也必须承认,我不明白caculateBarycentricWeights()函数到底有什么用。
然而,我基于以下概念实现了我的代码:
光栅化器必须在屏幕空间中工作
在光栅化之前,必须将3D顶点转换为屏幕空间
内部光栅化循环必须尽可能简单——最内部循环中的分支(即if和复杂函数)肯定是适得其反的。
因此,我创建了一个新的
rasterize()函数。因此,我考虑到
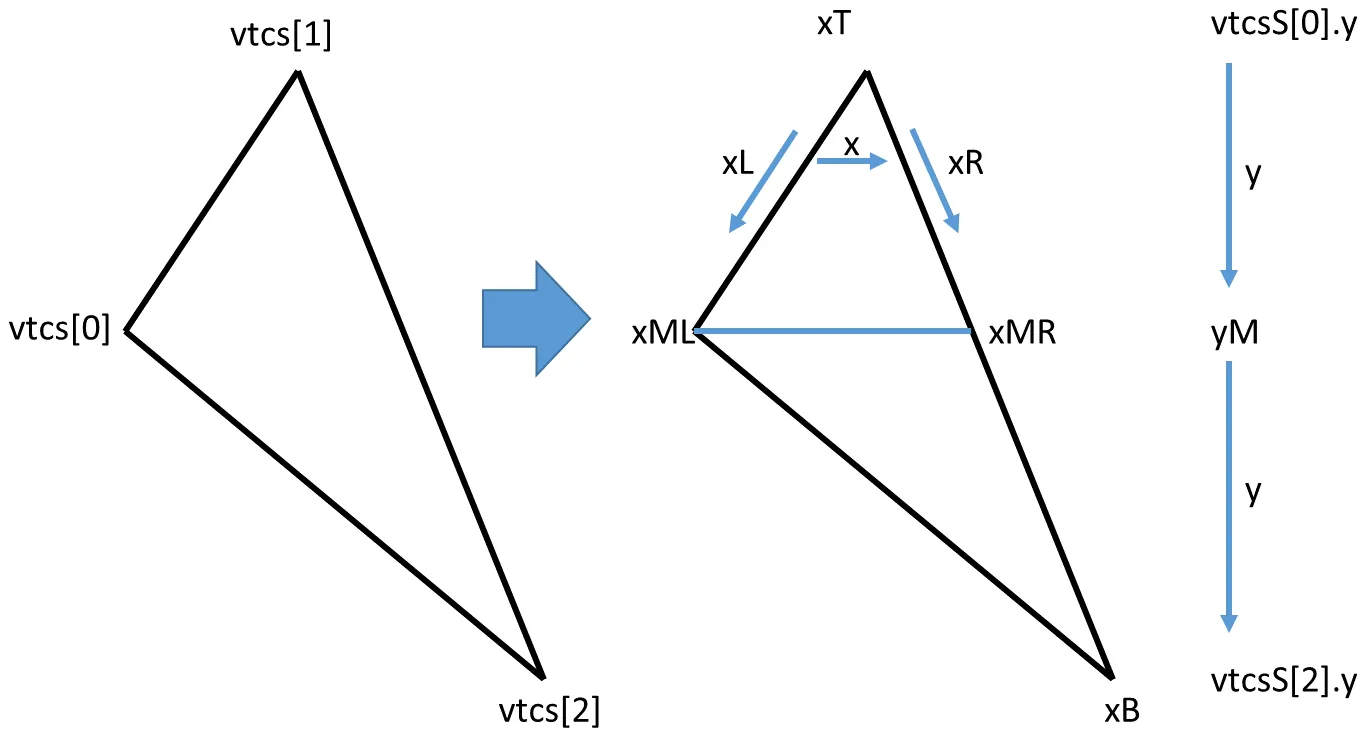
rasterize()必须填充水平屏幕线。为此,我按照它们的
y分量对3个三角形顶点进行排序。(请注意,顶点必须事先转换为屏幕空间)。在常规情况下,这样可以将三角形水平切成两部分:
- 上部位于水平基线之上的尖峰部分
- 下部位于水平基线之下的尖峰部分。
以下是源代码,但草图可以帮助更好地理解所有的插值:
为了将vtcs预先转换为屏幕空间,我使用了两个矩阵:
const Mat4x4f matProj(InitScale, 1.0f / Width, 1.0f / Height, 1.0f);
const Mat4x4f matScreen
= Mat4x4f(InitScale, 0.5f * Width, 0.5f * Height, 1.0f)
* Mat4x4f(InitTrans, Vec3f(1.0f, 1.0f, 0.0f));
const Mat4x4f mat = matScreen * matProj /* * matView * matModel */;
关于这个问题:
matProj 是投影矩阵,用于将模型坐标缩放到剪裁空间。matScreen 负责将剪裁空间转换为屏幕空间。
剪裁空间是一个空间,其中可见部分在 x、y 和 z 方向上的范围为 [-1, 1]。
屏幕空间的范围为 [0, width) 和 [0, height),其中我根据 OP 的要求使用了 width = 1024 和 height = 768。
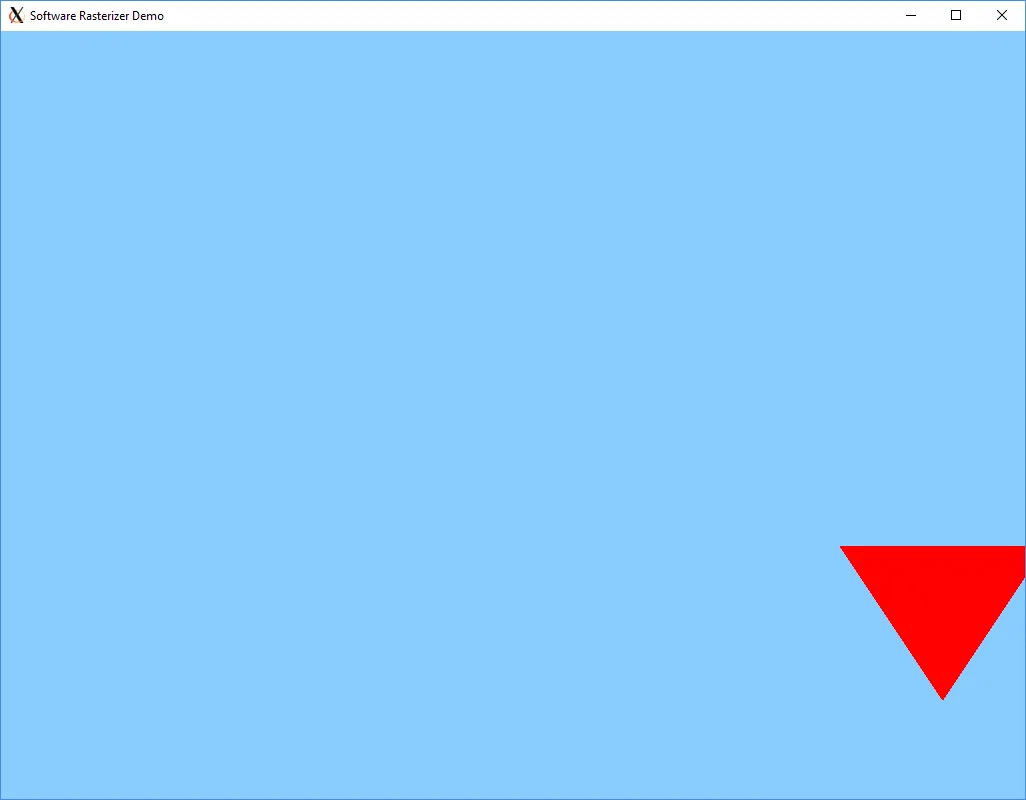
当我创建 OpenGL 程序时,通常会从蓝色屏幕开始(因为蓝色是我最喜欢的清晰颜色之一),这主要是由于某些矩阵操作的混淆,随后需要努力找到并修复这些操作。因此,我尝试将光栅化结果可视化,以确保我的基准测试不会过于热情,因为三角形的任何部分都在视图之外,因此被剪切掉了:

我认为这是一种视觉证明。为了实现这一点,我将光栅化器示例包装到一个简单的Qt应用程序中,在其中将FBO数据存储在QImage中,然后将其应用于使用QLabel显示的QPixmap。一旦我得到了这个,我想通过随时间修改模型视图矩阵来添加一些简单的动画效果。所以,我得到了以下示例:
#include <cstdint>
#include <algorithm>
#include <chrono>
#include <iostream>
#include <vector>
#include "linmath.h"
typedef unsigned uint;
typedef std::uint32_t uint32;
const int Width = 1024, Height = 768;
class FBO {
public:
const int width, height;
private:
std::vector<uint32> _rgba;
public:
FBO(int width, int height):
width(width), height(height),
_rgba(width * height, 0)
{ }
~FBO() = default;
FBO(const FBO&) = delete;
FBO& operator=(const FBO&) = delete;
void clear(uint32 rgba) { std::fill(_rgba.begin(), _rgba.end(), rgba); }
void set(int x, int y, uint32 rgba)
{
const size_t i = y * width + x;
_rgba[i] = rgba;
}
size_t getI(int y) const { return y * width; }
size_t getI(int x, int y) const { return y * width + x; }
void set(size_t i, uint32 rgba) { _rgba[i] = rgba; }
const std::vector<uint32>& getRGBA() const { return _rgba; }
};
void rasterize(FBO &fbo, const Vec3f vtcs[3], const uint32 rgba)
{
uint iVtcs[3] = { 0, 1, 2 };
if (vtcs[iVtcs[0]].y > vtcs[iVtcs[1]].y) std::swap(iVtcs[0], iVtcs[1]);
if (vtcs[iVtcs[1]].y > vtcs[iVtcs[2]].y) std::swap(iVtcs[1], iVtcs[2]);
if (vtcs[iVtcs[0]].y > vtcs[iVtcs[1]].y) std::swap(iVtcs[0], iVtcs[1]);
const Vec3f vtcsS[3] = { vtcs[iVtcs[0]], vtcs[iVtcs[1]], vtcs[iVtcs[2]] };
const float yM = vtcs[1].y;
const float xT = vtcsS[0].x;
float xML = vtcsS[1].x;
const float f = (yM - vtcsS[0].y) / (vtcsS[2].y - vtcsS[0].y);
float xMR = (1.0f - f) * xT + f * vtcsS[2].x;
if (xML > xMR) std::swap(xML, xMR);
if (vtcs[iVtcs[0]].y < yM) {
const float dY = yM - vtcsS[0].y;
for (int y = std::max((int)vtcsS[0].y, 0),
yE = std::min((int)(yM + 0.5f), fbo.height);
y < yE; ++y) {
const float f1 = (yM - y) / dY, f0 = 1.0f - f1;
const float xL = f0 * xT + f1 * xML, xR = f0 * xT + f1 * xMR;
const size_t i = fbo.getI(y);
for (int x = std::max((int)xL, 0),
xE = std::min((int)(xR + 0.5f), fbo.width);
x < xE; ++x) {
fbo.set(i + x, rgba);
}
}
}
if (yM < vtcs[2].y) {
const float xB = vtcsS[2].x;
const float dY = vtcsS[2].y - yM;
for (int y = std::max((int)yM, 0),
yE = std::min((int)(vtcsS[2].y + 0.5f), fbo.height);
y < yE; ++y) {
const float f1 = (y - yM) / dY, f0 = 1.0f - f1;
const float xL = f0 * xML + f1 * xB, xR = f0 * xMR + f1 * xB;
const size_t i = fbo.getI(y);
for (int x = std::max((int)xL, 0),
xE = std::min((int)(xR + 0.5f), fbo.width);
x < xE; ++x) {
fbo.set(i + x, rgba);
}
}
}
}
template <typename VALUE>
Vec3T<VALUE> transformPoint(const Mat4x4T<VALUE> &mat, const Vec3T<VALUE> &pt)
{
Vec4T<VALUE> pt_ = mat * Vec4T<VALUE>(pt.x, pt.y, pt.z, (VALUE)1);
return pt_.w != (VALUE)0
? Vec3T<VALUE>(pt_.x / pt_.w, pt_.y / pt_.w, pt_.z / pt_.w)
: Vec3T<VALUE>(pt_.x, pt_.y, pt_.z);
}
typedef std::chrono::high_resolution_clock HiResClock;
typedef std::chrono::microseconds MicroSecs;
int mainBench()
{
const Mat4x4f matProj(InitScale, 1.0f / Width, 1.0f / Height, 1.0f);
const Mat4x4f matScreen
= Mat4x4f(InitScale, 0.5f * Width, 0.5f * Height, 1.0f)
* Mat4x4f(InitTrans, Vec3f(1.0f, 1.0f, 0.0f));
const Mat4x4f mat = matScreen * matProj ;
FBO fbo(Width, Height);
HiResClock::time_point start = HiResClock::now();
size_t fps = 0;
for (;;) {
static Vec3f v0 = { -2000.0f, -2000.0, 10.0 };
static Vec3f v1 = { 2000.0f, -2000.0, 10.0 };
static Vec3f v2 = { 0.0f, 2000.0, 10.0 };
const Vec3f vtcs[] = {
transformPoint(mat, v0), transformPoint(mat, v1), transformPoint(mat, v2)
};
rasterize(fbo, vtcs, 0xff0000ff);
++fps;
HiResClock::time_point now = HiResClock::now();
auto timeDiff
= std::chrono::duration_cast<MicroSecs>(now - start).count();
static const long oneSecond = 1000000;
if (timeDiff >= oneSecond) {
std::cout << fps << " " << std::flush;
fps = 0;
start = now;
}
}
}
#include <stack>
#include <QtWidgets>
struct RenderContext {
FBO fbo;
Mat4x4f matModelView;
Mat4x4f matProj;
RenderContext(int width, int height):
fbo(width, height),
matModelView(InitIdent),
matProj(InitIdent)
{ }
~RenderContext() = default;
};
void render(RenderContext &context)
{
context.fbo.clear(0xffffcc88);
static Vec3f v0 = { -2000.0f, -2000.0, 10.0 };
static Vec3f v1 = { 2000.0f, -2000.0, 10.0 };
static Vec3f v2 = { 0.0f, 2000.0, 10.0 };
#if 0
const Mat4x4f matProj(InitScale, 1.0f / Width, 1.0f / Height, 1.0f);
const Mat4x4f matScreen
= Mat4x4f(InitScale, 0.5f * Width, 0.5f * Height, 1.0f)
* Mat4x4f(InitTrans, Vec3f(1.0f, 1.0f, 0.0f));
const Mat4x4f mat = matScreen * matProj ;
#else
const Mat4x4f matScreen
= Mat4x4f(InitScale, 0.5f * context.fbo.width, 0.5f * context.fbo.height, 1.0f)
* Mat4x4f(InitTrans, Vec3f(1.0f, 1.0f, 0.0f));
const Mat4x4f mat = matScreen * context.matProj * context.matModelView;
#endif
const Vec3f vtcs[] = {
transformPoint(mat, v0), transformPoint(mat, v1), transformPoint(mat, v2)
};
rasterize(context.fbo, vtcs, 0xff0000ff);
}
int main(int argc, char **argv)
{
const bool gui = argc > 1
&& (strcmp(argv[1], "gui") == 0 || strcmp(argv[1], "-gui") == 0);
if (!gui) return mainBench();
for (char **arg = argv + 1; *arg; ++arg) arg [0] = arg[1];
qDebug() << "Qt Version:" << QT_VERSION_STR;
QApplication app(argc, argv);
RenderContext context(Width, Height);
QPixmap qPixmapImg(Width, Height);
QLabel qLblImg;
qLblImg.setWindowTitle("Software Rasterizer Demo");
qLblImg.setPixmap(qPixmapImg);
qLblImg.show();
QTime qTime(0, 0);
QTimer qTimer;
qTimer.setInterval(50);
QObject::connect(&qTimer, &QTimer::timeout,
[&]() {
const float r = 1.0f, t = 0.001f * qTime.elapsed();
context.matModelView
= Mat4x4f(InitTrans, Vec3f(r * sin(t), r * cos(t), 0.0f))
* Mat4x4f(InitScale, 0.0001f, 0.0001f, 0.0001f);
render(context);
const QImage qImg((uchar*)context.fbo.getRGBA().data(),
Width, Height, QImage::Format_RGBA8888);
qPixmapImg.convertFromImage(qImg);
qLblImg.setPixmap(qPixmapImg);
});
qTime.start(); qTimer.start();
return app.exec();
}
我使用了linmath.h代替gmtl(我不知道它是什么)(这是我以前写的MCVE剩下的):
#ifndef LIN_MATH_H
#define LIN_MATH_H
#include <iostream>
#include <cassert>
#include <cmath>
double Pi = 3.1415926535897932384626433832795;
template <typename VALUE>
inline VALUE degToRad(VALUE angle)
{
return (VALUE)Pi * angle / (VALUE)180;
}
template <typename VALUE>
inline VALUE radToDeg(VALUE angle)
{
return (VALUE)180 * angle / (VALUE)Pi;
}
template <typename VALUE>
struct Vec2T {
VALUE x, y;
Vec2T() { }
Vec2T(VALUE x, VALUE y): x(x), y(y) { }
};
template <typename VALUE>
VALUE length(const Vec2T<VALUE> &vec)
{
return sqrt(vec.x * vec.x + vec.y * vec.y);
}
template <typename VALUE>
std::ostream& operator<<(std::ostream &out, const Vec2T<VALUE> &v)
{
return out << "( " << v.x << ", " << v.y << " )";
}
typedef Vec2T<float> Vec2f;
typedef Vec2T<double> Vec2;
template <typename VALUE>
struct Vec3T {
VALUE x, y, z;
Vec3T() { }
Vec3T(VALUE x, VALUE y, VALUE z): x(x), y(y), z(z) { }
Vec3T(const Vec2T<VALUE> &xy, VALUE z): x(xy.x), y(xy.y), z(z) { }
explicit operator Vec2T<VALUE>() const { return Vec2T<VALUE>(x, y); }
};
template <typename VALUE>
std::ostream& operator<<(std::ostream &out, const Vec3T<VALUE> &v)
{
return out << "( " << v.x << ", " << v.y << ", " << v.z << " )";
}
typedef Vec3T<float> Vec3f;
typedef Vec3T<double> Vec3;
template <typename VALUE>
struct Vec4T {
VALUE x, y, z, w;
Vec4T() { }
Vec4T(VALUE x, VALUE y, VALUE z, VALUE w): x(x), y(y), z(z), w(w) { }
Vec4T(const Vec2T<VALUE> &xy, VALUE z, VALUE w):
x(xy.x), y(xy.y), z(z), w(w)
{ }
Vec4T(const Vec3T<VALUE> &xyz, VALUE w):
x(xyz.x), y(xyz.y), z(xyz.z), w(w)
{ }
explicit operator Vec2T<VALUE>() const { return Vec2T<VALUE>(x, y); }
explicit operator Vec3T<VALUE>() const { return Vec3T<VALUE>(x, y, z); }
};
template <typename VALUE>
std::ostream& operator<<(std::ostream &out, const Vec4T<VALUE> &v)
{
return out << "( " << v.x << ", " << v.y << ", " << v.z << ", " << v.w << " )";
}
typedef Vec4T<float> Vec4f;
typedef Vec4T<double> Vec4;
enum ArgInitIdent { InitIdent };
enum ArgInitTrans { InitTrans };
enum ArgInitRot { InitRot };
enum ArgInitRotX { InitRotX };
enum ArgInitRotY { InitRotY };
enum ArgInitRotZ { InitRotZ };
enum ArgInitScale { InitScale };
template <typename VALUE>
struct Mat4x4T {
union {
VALUE comp[4 * 4];
struct {
VALUE _00, _01, _02, _03;
VALUE _10, _11, _12, _13;
VALUE _20, _21, _22, _23;
VALUE _30, _31, _32, _33;
};
};
Mat4x4T(
VALUE _00, VALUE _01, VALUE _02, VALUE _03,
VALUE _10, VALUE _11, VALUE _12, VALUE _13,
VALUE _20, VALUE _21, VALUE _22, VALUE _23,
VALUE _30, VALUE _31, VALUE _32, VALUE _33):
_00(_00), _01(_01), _02(_02), _03(_03),
_10(_10), _11(_11), _12(_12), _13(_13),
_20(_20), _21(_21), _22(_22), _23(_23),
_30(_30), _31(_31), _32(_32), _33(_33)
{ }
Mat4x4T(ArgInitIdent):
_00((VALUE)1), _01((VALUE)0), _02((VALUE)0), _03((VALUE)0),
_10((VALUE)0), _11((VALUE)1), _12((VALUE)0), _13((VALUE)0),
_20((VALUE)0), _21((VALUE)0), _22((VALUE)1), _23((VALUE)0),
_30((VALUE)0), _31((VALUE)0), _32((VALUE)0), _33((VALUE)1)
{ }
Mat4x4T(ArgInitTrans, const Vec3T<VALUE> &t):
_00((VALUE)1), _01((VALUE)0), _02((VALUE)0), _03((VALUE)t.x),
_10((VALUE)0), _11((VALUE)1), _12((VALUE)0), _13((VALUE)t.y),
_20((VALUE)0), _21((VALUE)0), _22((VALUE)1), _23((VALUE)t.z),
_30((VALUE)0), _31((VALUE)0), _32((VALUE)0), _33((VALUE)1)
{ }
Mat4x4T(ArgInitRot, const Vec3T<VALUE> &axis, VALUE angle):
_03((VALUE)0), _13((VALUE)0), _23((VALUE)0),
_30((VALUE)0), _31((VALUE)0), _32((VALUE)0), _33((VALUE)1)
{
const VALUE sinAngle = sin(angle), cosAngle = cos(angle);
const VALUE xx = axis.x * axis.x, xy = axis.x * axis.y;
const VALUE xz = axis.x * axis.z, yy = axis.y * axis.y;
const VALUE yz = axis.y * axis.z, zz = axis.z * axis.z;
_00 = xx + cosAngle * ((VALUE)1 - xx) ;
_01 = xy - cosAngle * xy - sinAngle * axis.z;
_02 = xz - cosAngle * xz + sinAngle * axis.y;
_10 = xy - cosAngle * xy + sinAngle * axis.z;
_11 = yy + cosAngle * ((VALUE)1 - yy) ;
_12 = yz - cosAngle * yz - sinAngle * axis.x;
_20 = xz - cosAngle * xz - sinAngle * axis.y;
_21 = yz - cosAngle * yz + sinAngle * axis.x;
_22 = zz + cosAngle * ((VALUE)1 - zz) ;
}
Mat4x4T(ArgInitRotX, VALUE angle):
_00((VALUE)1), _01((VALUE)0), _02((VALUE)0), _03((VALUE)0),
_10((VALUE)0), _11(cos(angle)), _12(-sin(angle)), _13((VALUE)0),
_20((VALUE)0), _21(sin(angle)), _22(cos(angle)), _23((VALUE)0),
_30((VALUE)0), _31((VALUE)0), _32((VALUE)0), _33((VALUE)1)
{ }
Mat4x4T(ArgInitRotY, VALUE angle):
_00(cos(angle)), _01((VALUE)0), _02(sin(angle)), _03((VALUE)0),
_10((VALUE)0), _11((VALUE)1), _12((VALUE)0), _13((VALUE)0),
_20(-sin(angle)), _21((VALUE)0), _22(cos(angle)), _23((VALUE)0),
_30((VALUE)0), _31((VALUE)0), _32((VALUE)0), _33((VALUE)1)
{ }
Mat4x4T(ArgInitRotZ, VALUE angle):
_00(cos(angle)), _01(-sin(angle)), _02((VALUE)0), _03((VALUE)0),
_10(sin(angle)), _11(cos(angle)), _12((VALUE)0), _13((VALUE)0),
_20((VALUE)0), _21((VALUE)0), _22((VALUE)1), _23((VALUE)0),
_30((VALUE)0), _31((VALUE)0), _32((VALUE)0), _33((VALUE)1)
{ }
Mat4x4T(ArgInitScale, VALUE sx, VALUE sy, VALUE sz):
_00((VALUE)sx), _01((VALUE)0), _02((VALUE)0), _03((VALUE)0),
_10((VALUE)0), _11((VALUE)sy), _12((VALUE)0), _13((VALUE)0),
_20((VALUE)0), _21((VALUE)0), _22((VALUE)sz), _23((VALUE)0),
_30((VALUE)0), _31((VALUE)0), _32((VALUE)0), _33((VALUE)1)
{ }
double* operator [] (int i)
{
assert(i >= 0 && i < 4);
return comp + 4 * i;
}
const double* operator [] (int i) const
{
assert(i >= 0 && i < 4);
return comp + 4 * i;
}
Mat4x4T operator * (const Mat4x4T &mat) const
{
return Mat4x4T(
_00 * mat._00 + _01 * mat._10 + _02 * mat._20 + _03 * mat._30,
_00 * mat._01 + _01 * mat._11 + _02 * mat._21 + _03 * mat._31,
_00 * mat._02 + _01 * mat._12 + _02 * mat._22 + _03 * mat._32,
_00 * mat._03 + _01 * mat._13 + _02 * mat._23 + _03 * mat._33,
_10 * mat._00 + _11 * mat._10 + _12 * mat._20 + _13 * mat._30,
_10 * mat._01 + _11 * mat._11 + _12 * mat._21 + _13 * mat._31,
_10 * mat._02 + _11 * mat._12 + _12 * mat._22 + _13 * mat._32,
_10 * mat._03 + _11 * mat._13 + _12 * mat._23 + _13 * mat._33,
_20 * mat._00 + _21 * mat._10 + _22 * mat._20 + _23 * mat._30,
_20 * mat._01 + _21 * mat._11 + _22 * mat._21 + _23 * mat._31,
_20 * mat._02 + _21 * mat._12 + _22 * mat._22 + _23 * mat._32,
_20 * mat._03 + _21 * mat._13 + _22 * mat._23 + _23 * mat._33,
_30 * mat._00 + _31 * mat._10 + _32 * mat._20 + _33 * mat._30,
_30 * mat._01 + _31 * mat._11 + _32 * mat._21 + _33 * mat._31,
_30 * mat._02 + _31 * mat._12 + _32 * mat._22 + _33 * mat._32,
_30 * mat._03 + _31 * mat._13 + _32 * mat._23 + _33 * mat._33);
}
Vec4T<VALUE> operator * (const Vec4T<VALUE> &vec) const
{
return Vec4T<VALUE>(
_00 * vec.x + _01 * vec.y + _02 * vec.z + _03 * vec.w,
_10 * vec.x + _11 * vec.y + _12 * vec.z + _13 * vec.w,
_20 * vec.x + _21 * vec.y + _22 * vec.z + _23 * vec.w,
_30 * vec.x + _31 * vec.y + _32 * vec.z + _33 * vec.w);
}
};
template <typename VALUE>
std::ostream& operator<<(std::ostream &out, const Mat4x4T<VALUE> &m)
{
return out
<< m._00 << '\t' << m._01 << '\t' << m._02 << '\t' << m._03 << '\n'
<< m._10 << '\t' << m._11 << '\t' << m._12 << '\t' << m._13 << '\n'
<< m._20 << '\t' << m._21 << '\t' << m._22 << '\t' << m._23 << '\n'
<< m._30 << '\t' << m._31 << '\t' << m._32 << '\t' << m._33 << '\n';
}
typedef Mat4x4T<float> Mat4x4f;
typedef Mat4x4T<double> Mat4x4;
enum RotAxis {
RotX,
RotY,
RotZ
};
enum EulerAngle {
RotXYX = RotX + 3 * RotY + 9 * RotX,
RotXYZ = RotX + 3 * RotY + 9 * RotZ,
RotXZX = RotX + 3 * RotZ + 9 * RotX,
RotXZY = RotX + 3 * RotZ + 9 * RotY,
RotYXY = RotY + 3 * RotX + 9 * RotY,
RotYXZ = RotY + 3 * RotX + 9 * RotZ,
RotYZX = RotY + 3 * RotZ + 9 * RotX,
RotYZY = RotY + 3 * RotZ + 9 * RotY,
RotZXY = RotZ + 3 * RotX + 9 * RotY,
RotZXZ = RotZ + 3 * RotX + 9 * RotZ,
RotZYX = RotZ + 3 * RotY + 9 * RotX,
RotZYZ = RotZ + 3 * RotY + 9 * RotZ,
RotHPR = RotZXY,
RotABC = RotZYX
};
inline void decompose(
EulerAngle type, RotAxis &axis1, RotAxis &axis2, RotAxis &axis3)
{
unsigned type_ = (unsigned)type;
axis1 = (RotAxis)(type_ % 3); type_ /= 3;
axis2 = (RotAxis)(type_ % 3); type_ /= 3;
axis3 = (RotAxis)type_;
}
template <typename VALUE>
Mat4x4T<VALUE> makeEuler(
EulerAngle mode, VALUE rot1, VALUE rot2, VALUE rot3)
{
RotAxis axis1, axis2, axis3;
decompose(mode, axis1, axis2, axis3);
const static VALUE axes[3][3] = {
{ (VALUE)1, (VALUE)0, (VALUE)0 },
{ (VALUE)0, (VALUE)1, (VALUE)0 },
{ (VALUE)0, (VALUE)0, (VALUE)1 }
};
return
Mat4x4T<VALUE>(InitRot,
Vec3T<VALUE>(axes[axis1][0], axes[axis1][1], axes[axis1][2]),
rot1)
* Mat4x4T<VALUE>(InitRot,
Vec3T<VALUE>(axes[axis2][0], axes[axis2][1], axes[axis2][2]),
rot2)
* Mat4x4T<VALUE>(InitRot,
Vec3T<VALUE>(axes[axis3][0], axes[axis3][1], axes[axis3][2]),
rot3);
}
template <typename VALUE>
void decompose(
const Mat4x4T<VALUE> &mat,
RotAxis axis1, RotAxis axis2, RotAxis axis3,
VALUE &angle1, VALUE &angle2, VALUE &angle3)
{
assert(axis1 != axis2 && axis2 != axis3);
const int odd = (axis1 + 1) % 3 == axis2 ? 0 : 1;
const int i = axis1;
const int j = (axis1 + 1 + odd) % 3;
const int k = (axis1 + 2 - odd) % 3;
if (axis1 == axis3) {
angle1 = atan2(mat[j][i], mat[k][i]);
if ((odd && angle1 < (VALUE)0) || (!odd && angle1 > (VALUE)0)) {
angle1 = angle1 > (VALUE)0 ? angle1 - (VALUE)Pi : angle1 + (VALUE)Pi;
const VALUE s2 = length(Vec2T<VALUE>(mat[j][i], mat[k][i]));
angle2 = -atan2(s2, mat[i][i]);
} else {
const VALUE s2 = length(Vec2T<VALUE>(mat[j][i], mat[k][i]));
angle2 = atan2(s2, mat[i][i]);
}
const VALUE s1 = sin(angle1);
const VALUE c1 = cos(angle1);
angle3 = atan2(c1 * mat[j][k] - s1 * mat[k][k],
c1 * mat[j][j] - s1 * mat[k][j]);
} else {
angle1 = atan2(mat[j][k], mat[k][k]);
const VALUE c2 = length(Vec2T<VALUE>(mat[i][i], mat[i][j]));
if ((odd && angle1<(VALUE)0) || (!odd && angle1 > (VALUE)0)) {
angle1 = (angle1 > (VALUE)0)
? angle1 - (VALUE)Pi : angle1 + (VALUE)Pi;
angle2 = atan2(-mat[i][k], -c2);
} else angle2 = atan2(-mat[i][k], c2);
const VALUE s1 = sin(angle1);
const VALUE c1 = cos(angle1);
angle3 = atan2(s1 * mat[k][i] - c1 * mat[j][i],
c1 * mat[j][j] - s1 * mat[k][j]);
}
if (!odd) {
angle1 = -angle1; angle2 = -angle2; angle3 = -angle3;
}
}
#endif
在我添加 Qt 代码之前,我只是使用以下命令进行编译:
$ g++ -std=c++11 -o rasterizerSimple rasterizerSimple.cc
为了使用Qt编译,我编写了一个Qt项目
rasterizerSimple.pro:
SOURCES = rasterizerSimple.cc
QT += widgets
在 Windows 10 上 cygwin64 编译并测试通过:
$ qmake-qt5 rasterizerSimple.pro
$ make
$ ./rasterizerSimple
2724 2921 3015 2781 2800 2805 2859 2783 2931 2871 2902 2983 2995 2882 2940 2878 3007 2993 3066 3067 3118 3144 2849 3084 3020 3005 3030 2991 2999 3065 2941 3123 3119 2905 3135 2938
CtrlC
我的笔记本电脑有一个英特尔 i7 处理器(当我让程序运行更长时间时,会产生一点冷却噪音)。
看起来还不错——平均每秒3000个三角形。(如果OP的i7不比我的慢太多,那么就超过了他的130 FPS。)
也许,通过进一步的改进,FPS 可以再提高一点。例如,可以使用Bresenham's line algorithm进行插值,尽管它在大多数内部循环中并没有出现。为了优化大多数内部循环,应该以更快的方式填充水平线(虽然我不太确定如何实现这一点)。
要启动 Qt 可视化,必须使用gui启动应用程序:
$ ./rasterizerSimple gui
这个示例激发了我一个玩具项目的灵感,可以在github上找到
No-GL 3D渲染器。
{kind=link}