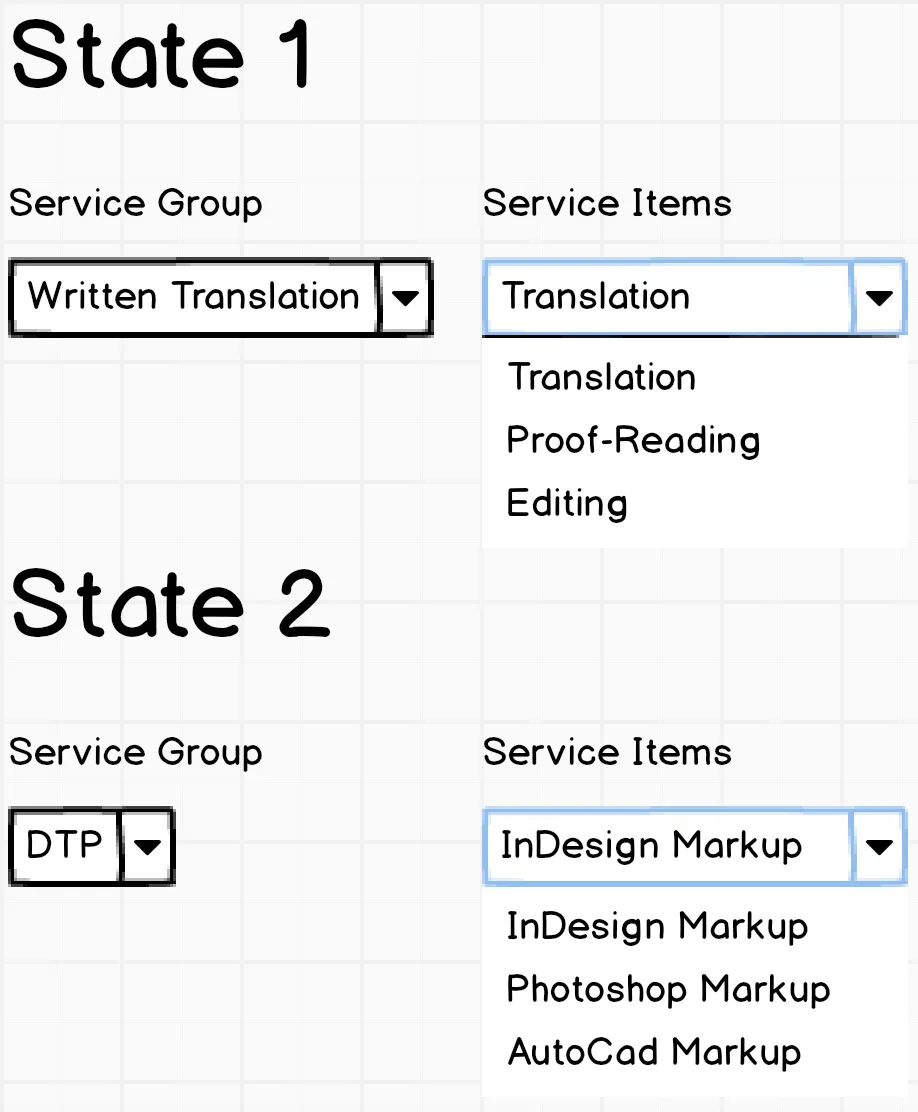
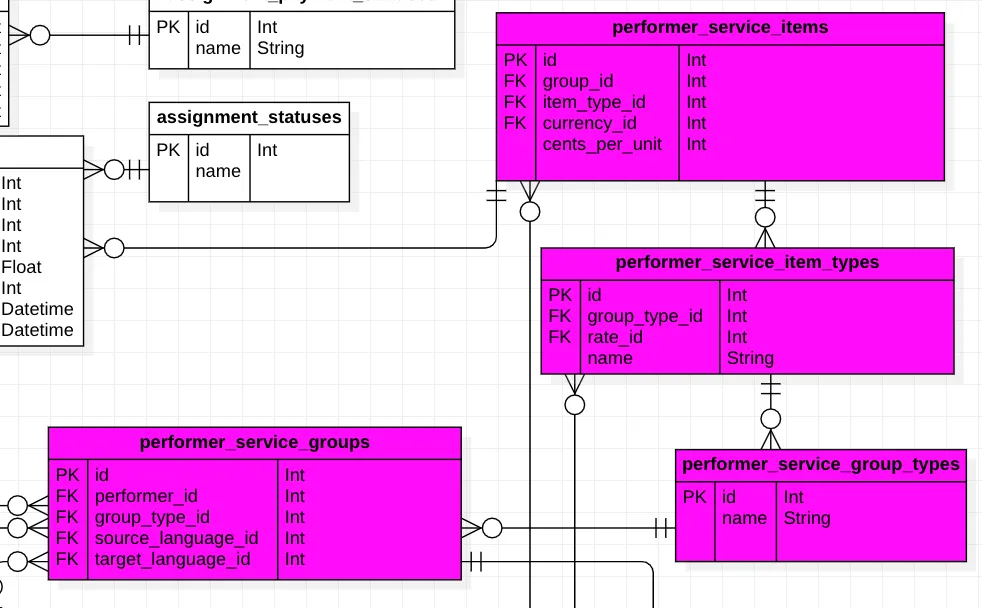
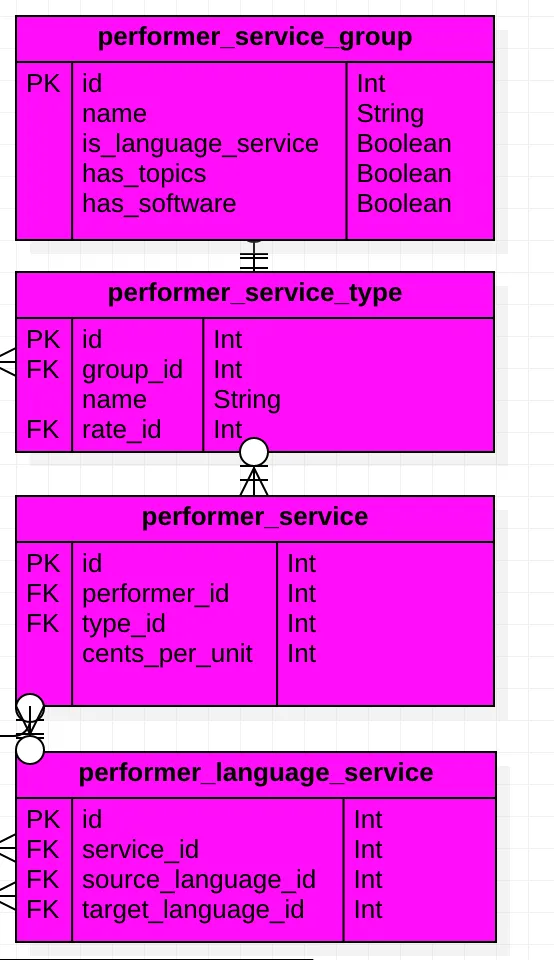
这里的问题是,这似乎只是一个更大项目的一部分,措辞 相当混乱。我已经试图解开这个谜团,但我有更多的问题而不是答案。然而,您的主要关注点似乎是 约束,因此这个例子应该有所帮助。主要问题是依赖单列键 -- 这本身并不一定是坏事,但很难正确设置约束。
请记住,这是一个 逻辑设计,它不会直接解决您所述的问题,但如果你“转换”成PostgreSQL,它将会起作用。这样你就可以尝试约束并调整你的项目。
Note:
All attributes (columns) NOT NULL
PK = Primary Key
AK = Alternate Key (Unique)
SK = Proper Superkey (Unique)
FK = Foreign Key
服务类型自定义类型 ID(鉴别器);对于每个SVC_TYP_ID列使用此类型。
TYPE svc_typ ENUM (T, D)
定义基础概念:服务、服务类型、语言、人员。
service_typ {SVC_TYP_ID::svc_typ, SVC_TYP_NAME}
PK {SVC_TYP_ID}
AK {SVC_TYP_ID}
(T, translation)
(D, dtp)
service_ {SVC_ID, SVC_TYP_ID, SVC_NAME}
PK {SVC_ID}
AK {SVC_NAME}
SK {SVC_ID, SVC_TYP_ID}
FK {SVC_TYP_ID} REFERENCES service_typ
(WTR, T, written translation)
(EDT, T, editing)
(PRF, T, proof reading)
(IND, D, in-design markup)
(PHT, D, photoshop markup)
(ACD, D, autocad markup)
lang {LANG_ID, LANG_NAME}
PK {LANG_ID}
AK {LANG_NAME}
(EN, English)
(FR, French)
(RU, Russian)
perfomer {PERF_ID, FNAME, LNAME}
PK {PERF_ID}
(1, Lev, Tolstoy)
(2, Jim, Blah)
(3, Joe, Doe)
(4, Jane, Doe)
人们提供服务,每个人可能提供多种服务类型。在这个例子中,提供服务的人的通用术语是“执行者”。翻译和DTP专业人员是执行者超类型的子类型,鉴别器是服务类型。同一执行者可以提供多种服务类型。
-- Perfomer PERF_ID registered for service type SVC_TYP_ID.
--
perf_svc_typ
PK
FK1 REFERENCES perfomer
FK2 REFERENCES service_typ
(1, T, ... )
(2, T, ... )
(3, D, ... )
(4, T, ... )
(4, D, ... ) -- PERF_ID = 4 does translations and dtp
-- Performer PERF_ID is registered as a translator.
--
-- note: (SVC_TYP_ID = T)
--
translator
PK
CHECK (SVC_TYP_ID = T::svc_typ)
FK REFERENCES perf_svc_typ
(1, T, ...)
(2, T, ...)
(4, T, ...)
-- Performer PERF_ID is registered as a DTP professional.
--
-- note: (SVC_TYP_ID = D)
--
dtp_prof
PK
CHECK (SVC_TYP_ID = D::svc_typ)
FK REFERENCES
perf_svc_typ
(3, D, ...)
(4, D, ...)
翻译人员可能能够提供多种语言的服务。
perf_lang {PERF_ID, LANG_ID}
PK {PERF_ID, LANG_ID}
FK1 {PERF_ID} REFERENCES translator
FK2 {LANG_ID} REFERENCES lang
(1, EN)
(1, FR)
(1, RU)
(2, EN)
(2, FR)
(4, FR)
(4, RU)
每个人(执行者)可以提供多组服务。每个服务组中的服务必须是相同的服务类型。执行者必须注册为此服务类型的提供者。
svc_group {PERF_ID, PERF_GROUP_NO, SVC_TYP_ID}
PK {PERF_ID, PERF_GROUP_NO}
SK {PERF_ID, PERF_GROUP_NO, SVC_TYP_ID}
FK {PERF_ID, SVC_TYP_ID} REFERENCES perf_svc_typ
(1, 1, T)
(1, 2, T)
(2, 1, T)
(3, 1, D)
(4, 1, T)
(4, 2, D)
每个表演者的服务组列出了该组表演者提供的服务类型的服务。
trans_svc {
PERF_ID
, PERF_GROUP_NO
, SVC_ID
, SVC_TYP_ID
, FROM_LANG
, TO_LANG
}
PK {PERF_ID, PERF_GROUP_NO, SVC_ID, FROM_LANG, TO_LANG}
CHECK (SVC_TYP_ID = T::svc_typ)
FK1 {PERF_ID, PERF_GROUP_NO, SVC_TYP_ID} REFERENCES svc_group
FK2 {SVC_ID, SVC_TYP_ID} REFERENCES service_
FK3 {PERF_ID} REFERENCES translator
FK4 {PERF_ID, FROM_LANG} REFERENCES
perf_lang {PERF_ID, LANG_ID}
FK5 {PERF_ID, TO_LANG} REFERENCES
perf_lang {PERF_ID, LANG_ID}
(1, 1, WTR, T, EN, RU)
(1, 1, WTR, T, FR, RU)
(1, 2, PRF, T, RU, RU)
(1, 2, EDT, T, RU, RU)
(1, 2, PRF, T, EN, EN)
(2, 1, WTR, T, EN, FR)
(2, 1, WTR, T, FR, EN)
(2, 1, EDT, T, EN, EN)
(2, 1, PRF, T, EN, EN)
(2, 1, PRF, T, FR, FR)
(4, 1, WTR, T, FR, RU)
(4, 1, PRF, T, FR, FR)
dtp_svc {PERF_ID, PERF_GROUP_NO, SVC_ID, SVC_TYP_ID}
PK {PERF_ID, PERF_GROUP_NO, SVC_ID}
CHECK (SVC_TYP_ID = D::svc_typ)
FK1 {PERF_ID, PERF_GROUP_NO, SVC_TYP_ID} REFERENCES svc_group
FK2 {SVC_ID, SVC_TYP_ID} REFERENCES service_
FK3 {PERF_ID} REFERENCES dtp_prof
(3, 1, PHT, D)
(3, 1, ACD, D)
(4, 2, IND, D)
(4, 2, ACD, D)