如果可能的话,我想知道用位移和整数除法替换单个乘法是否更快。假设我有一个 int k,并且我想将其乘以 2.25。
哪种方法更快?
int k = 5;
k *= 2.25;
std::cout << k << std::endl;
或者
int k = 5;
k = (k<<1) + (k/4);
std::cout << k << std::endl;
输出
11
11
两者都会得到相同的结果,您可以查看这个完整的例子。
如果可能的话,我想知道用位移和整数除法替换单个乘法是否更快。假设我有一个 int k,并且我想将其乘以 2.25。
哪种方法更快?
int k = 5;
k *= 2.25;
std::cout << k << std::endl;
或者
int k = 5;
k = (k<<1) + (k/4);
std::cout << k << std::endl;
输出
11
11
两者都会得到相同的结果,您可以查看这个完整的例子。
我定义了以下函数regularmultiply()和bitwisemultiply():
int regularmultiply(int j)
{
return j * 2.25;
}
int bitwisemultiply(int k)
{
return (k << 1) + (k >> 2);
}
在XCode上的Instruments中进行分析(在2009年的Macbook OS X 10.9.2上),似乎 bitwisemultiply 的执行速度比 regularmultiply 快了约两倍。
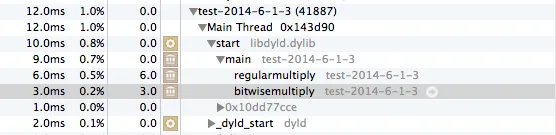
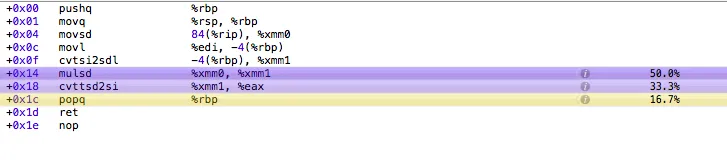
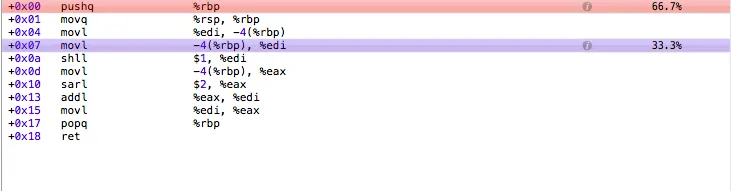
汇编代码输出似乎证实了这一点,bitwisemultiply 大部分时间用于寄存器重排和函数返回,而 regularmultiply 则大部分时间用于乘法运算。
regularmultiply:
bitwisemultiply:
但我的测试时间太短了。
接下来,我尝试使用1000万个乘法来执行两个函数,并将循环放入函数中,以便所有的函数进出都不会影响数字。这次,结果是每个方法需要大约52毫秒的时间。因此,对于相对较大但不是巨大的计算数量,这两个函数需要的时间大致相同。这让我感到惊讶,所以我决定进行更长时间和更大数量的计算。
这次,我只通过2.25将100万到5亿之间的数字相乘,但 bitwisemultiply 的速度比 regularmultiply 稍微慢了一点。
最后,我交换了两个函数的顺序,只是为了看看Instruments中不断增长的CPU图表是否会拖慢第二个函数的速度。但仍然,regularmultiply 的表现略优:

这是最终程序的样子:
#include <stdio.h>
int main(void)
{
void regularmultiplyloop(int j);
void bitwisemultiplyloop(int k);
int i, j, k;
j = k = 4;
bitwisemultiplyloop(k);
regularmultiplyloop(j);
return 0;
}
void regularmultiplyloop(int j)
{
for(int m = 0; m < 10; m++)
{
for(int i = 100000000; i < 500000000; i++)
{
j = i;
j *= 2.25;
}
printf("j: %d\n", j);
}
}
void bitwisemultiplyloop(int k)
{
for(int m = 0; m < 10; m++)
{
for(int i = 100000000; i < 500000000; i++)
{
k = i;
k = (k << 1) + (k >> 2);
}
printf("k: %d\n", k);
}
}
那么我们能从中得到什么结论呢?有一件事情是可以确定的,那就是优化编译器比大多数人都要好。而且,这些优化在有大量计算时表现得更加突出,但这也是你真正想要进行优化的唯一时机。因此,除非你使用汇编语言编写你的优化代码,否则将乘法改成位移操作可能帮助不大。
在应用程序中考虑效率总是有益的,但微小的效率提升通常不足以证明让你的代码难以阅读。
-O0进行编译。因此,位运算乘法会进行更多的堆栈访问,因为它操作更多的中间值。这使得它变慢,即使这些堆栈访问是完全不必要的。如果您使用-O2或-Os进行编译,情况应该会发生巨大变化。 - cmaster - reinstate monica实际上,这取决于各种因素。所以我只是通过运行和测量时间来检查它。我们感兴趣的字符串只需要几个CPU指令,非常快,所以我将其包装在循环中 - 将一个代码的执行时间乘以一个大数,然后得到k *= 2.25;比k = (k<<1) + (k/4);慢了约1.5倍。
以下是我的两个比较代码:
prog1:
#include <iostream>
using namespace std;
int main() {
int k = 5;
for (unsigned long i = 0; i <= 0x2fffffff;i++)
k = (k<<1) + (k/4);
cout << k << endl;
return 0;
}
程序2:
#include <iostream>
using namespace std;
int main() {
int k = 5;
for (unsigned long i = 0; i <= 0x2fffffff;i++)
k *= 2.25;
cout << k << endl;
return 0;
}
Prog1 需要 8 秒,而 Prog2 需要 14 秒。因此,通过在您的架构和编译器上运行此测试,您可以获得符合您特定环境的正确结果。
这取决于CPU架构:在许多CPU上,包括乘法在内的浮点运算已经变得非常便宜。但是必要的浮点数转换可能会让你感到棘手:例如,在POWER-CPU上,由于从浮点单元移动值到整数单元时生成的流水线刷新,常规乘法将会变慢。
在某些CPU上(包括我的AMD CPU),这个版本实际上是最快的:
k *= 9;
k >>= 2;
这高度取决于您使用的硬件。在现代硬件上,浮点数乘法可能比整数乘法运行得更快,因此您可能希望更改整个算法并开始使用双精度浮点数而不是整数。如果您正在为现代硬件编写代码,并且有许多操作(例如乘以2.25),我建议您使用double而不是整数,除非有其他原因阻止您这样做。
并且要数据驱动 - 测量性能,因为它受编译器、硬件和实现算法的方式影响。
k是整数还是浮点数? - user149341k = (k<<1) + (k>>2);? - AntonH