在C语言中,将一串十六进制数字转换为二进制的最有效的方法是什么?可以得到一个unsigned int或者unsigned long类型的值。
例如,如果有一个字符串0xFFFFFFFE,希望得到一个int类型的值4294967294。
在C语言中,将一串十六进制数字转换为二进制的最有效的方法是什么?可以得到一个unsigned int或者unsigned long类型的值。
例如,如果有一个字符串0xFFFFFFFE,希望得到一个int类型的值4294967294。
编辑:现在与MSVC、C++和非GNU编译器兼容(请参见结尾)。
问题是"最有效的方法"。OP没有指定平台,他可以为一个具有256字节闪存的基于RISC的ATMEL芯片进行编译。
为了记录,并且对于那些像我一样欣赏“最简单的方法”和“最有效的方法”之间差异的人,以及那些喜欢学习的人...
static const long hextable[] = {
[0 ... 255] = -1, // bit aligned access into this table is considerably
['0'] = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, // faster for most modern processors,
['A'] = 10, 11, 12, 13, 14, 15, // for the space conscious, reduce to
['a'] = 10, 11, 12, 13, 14, 15 // signed char.
};
/**
* @brief convert a hexidecimal string to a signed long
* will not produce or process negative numbers except
* to signal error.
*
* @param hex without decoration, case insensitive.
*
* @return -1 on error, or result (max (sizeof(long)*8)-1 bits)
*/
long hexdec(unsigned const char *hex) {
long ret = 0;
while (*hex && ret >= 0) {
ret = (ret << 4) | hextable[*hex++];
}
return ret;
}
它不需要外部库,速度非常快。它可以处理大写、小写、无效字符、奇数长度的十六进制输入(例如:0xfff),并且最大尺寸仅受编译器限制。
对于不支持GCC或C++编译器或无法接受fancy hextable声明的编译器。
请将第一条语句替换为以下较长但更符合规范的版本:
static const long hextable[] = {
-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,
-1,-1, 0,1,2,3,4,5,6,7,8,9,-1,-1,-1,-1,-1,-1,-1,10,11,12,13,14,15,-1,
-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,10,11,12,13,14,15,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,
-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1
};
试试这个:
#include <stdio.h>
int main()
{
char s[] = "fffffffe";
int x;
sscanf(s, "%x", &x);
printf("%u\n", x);
}
对于AVR微控制器,我编写了以下函数,包括相关注释以使其易于理解:
/**
* hex2int
* take a hex string and convert it to a 32bit number (max 8 hex digits)
*/
uint32_t hex2int(char *hex) {
uint32_t val = 0;
while (*hex) {
// get current character then increment
char byte = *hex++;
// transform hex character to the 4bit equivalent number, using the ascii table indexes
if (byte >= '0' && byte <= '9') byte = byte - '0';
else if (byte >= 'a' && byte <='f') byte = byte - 'a' + 10;
else if (byte >= 'A' && byte <='F') byte = byte - 'A' + 10;
// shift 4 to make space for new digit, and add the 4 bits of the new digit
val = (val << 4) | (byte & 0xF);
}
return val;
}
例子:
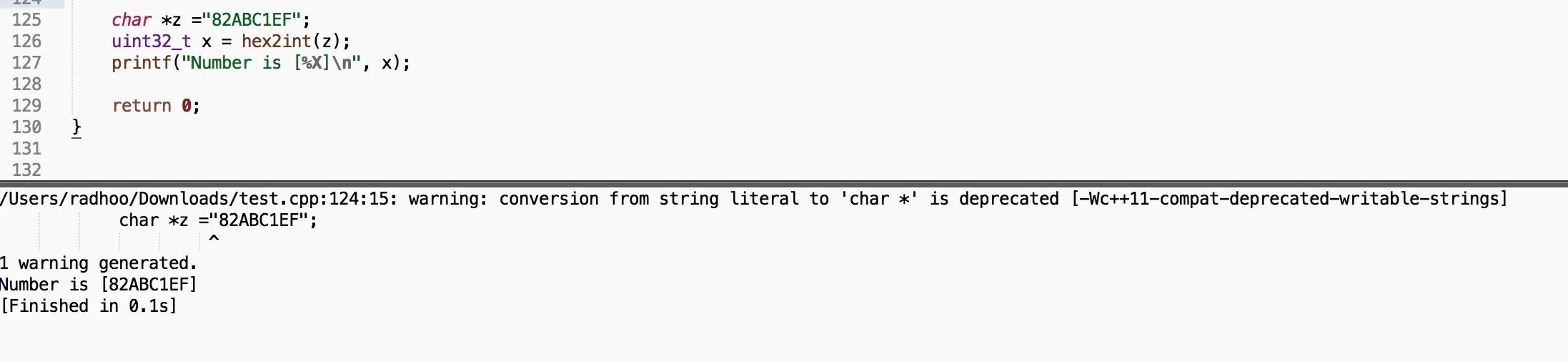
char *z ="82ABC1EF";
uint32_t x = hex2int(z);
printf("Number is [%X]\n", x);
unsigned long hex2int(char *a, unsigned int len)
{
int i;
unsigned long val = 0;
for(i=0;i<len;i++)
if(a[i] <= 57)
val += (a[i]-48)*(1<<(4*(len-1-i)));
else
val += (a[i]-55)*(1<<(4*(len-1-i)));
return val;
}
注意:此代码假定使用大写字母A-F。如果len超过您的最长整数32或64位,则无法正常工作,并且没有对非法十六进制字符进行错误捕获。
a[i]-'0' 和 a[i]-'A'+10 在罕见情况下,如果您的系统使用 EBCDIC(它们仍然存在),也可以使用。 - Patrick Schlüter'0'和'A'也可以使你的代码自我记录,方便那些不熟悉ASCII表的人。 - Peter Cordesuint64_t的数字)。然而,使用带进位加法处理一串十进制数字非常麻烦,所以可能行不通。 - Peter Cordes如前所述,效率基本上取决于优化的目标。
当优化代码行数或者在缺乏完整标准库的环境中工作时,有一种快捷而粗略的选择:
// makes a number from two ascii hexa characters
int ahex2int(char a, char b){
a = (a <= '9') ? a - '0' : (a & 0x7) + 9;
b = (b <= '9') ? b - '0' : (b & 0x7) + 9;
return (a << 4) + b;
}
更多类似的线程可以在这里找到:https://dev59.com/Hmkw5IYBdhLWcg3wE2dA#58253380
十六进制转十进制。不要在在线编译器上运行它,因为它不会起作用。
#include<stdio.h>
void main()
{
unsigned int i;
scanf("%x",&i);
printf("%d",i);
}
@Eric
我本来希望看到一个C语言巨匠发布一些非常酷的东西,有点像我做的但不那么冗长,同时仍然“手动”完成。
嗯,我不是C语言大师,但这是我想出来的:
unsigned int parseHex(const char * str)
{
unsigned int val = 0;
char c;
while(c = *str++)
{
val <<= 4;
if (c >= '0' && c <= '9')
{
val += c & 0x0F;
continue;
}
c &= 0xDF;
if (c >= 'A' && c <= 'F')
{
val += (c & 0x07) + 9;
continue;
}
errno = EINVAL;
return 0;
}
return val;
}
我最初使用了更多的位掩码操作而非比较,但我严重怀疑在现代硬件上位掩码操作是否比比较更快。
'A' + 1 == 'B' 或者 ('a' & 0xDF) == ('A' & 0xDF)。 - Roland Illig