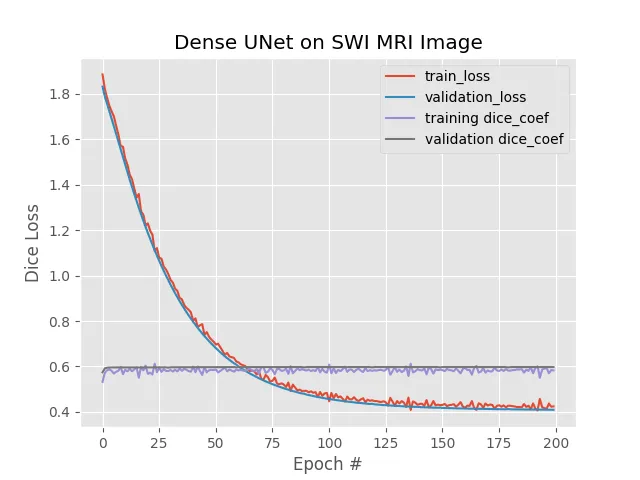
我正在从事医学图像分割工作。 我有两个类别。 类别0表示背景,类别1表示病变。 由于数据集高度不平衡,所以我使用的损失函数是(1-加权Dice系数),度量函数是Dice系数。 我已将数据集从0-255标准化为0-1。 我正在使用带tensorflow后端的Keras来训练模型。 在训练UNet ++模型时,我的损失函数随每个epoch递减,但是指标保持不变。 我无法理解为什么指标未随着预期降低而保持不变? 另外,我无法理解为什么损失大于1,因为Dice系数返回介于0和1之间的值?
这是我的损失函数:
def dice_loss(y_true, y_pred):
smooth = 1.
w1 = 0.3
w2 = 0.7
y_true_f = K.flatten(y_true[...,0])
y_pred_f = K.flatten(y_pred[...,0])
intersect = K.abs(K.sum(y_true_f * y_pred_f, axis = -1))
denom = K.abs(K.sum(y_true_f, axis = -1)) + K.abs(K.sum(y_pred_f, axis = -1))
coef1 = (2 * intersect + smooth) / (denom + smooth)
y_true_f1 = K.flatten(y_true[...,1])
y_pred_f1 = K.flatten(y_pred[...,1])
intersect1 = K.abs(K.sum(y_true_f1 * y_pred_f1, axis = -1))
denom1 = K.abs(K.sum(y_true_f1, axis = -1)) + K.abs(K.sum(y_pred_f1, axis = -1))
coef2 = (2 * intersect1 + smooth) / (denom1 + smooth)
weighted_dice_coef = w1 * coef1 + w2 * coef2
return (1 - weighted_dice_coef)
同时,这是衡量函数:
def dsc(y_true, y_pred):
"""
DSC = (|X and Y|)/ (|X| + |Y|)
"""
smooth = 1.
y_true_f = K.flatten(y_true[...,1])
y_pred_f = K.flatten(y_pred[...,1])
intersect = K.abs(K.sum(y_true_f * y_pred_f, axis = -1))
denom = K.abs(K.sum(y_true_f, axis = -1)) + K.abs(K.sum(y_pred_f, axis = -1))
coef = (2 * intersect + smooth) / (denom + smooth)
return coef
训练损失与迭代次数的关系:
这是示例代码:
def standard_unit(input_tensor, stage, nb_filter, kernel_size = 3):
x = Conv2D(nb_filter, kernel_size, padding = 'same', activation = act, kernel_initializer = 'he_normal', kernel_regularizer=l2(1e-4), name = 'conv' + stage + '_1')(input_tensor)
x = Dropout(dropout_rate, name = 'dp' + stage + '_1')(x)
x = Conv2D(nb_filter, kernel_size, padding = 'same', activation = act, kernel_initializer = 'he_normal', kernel_regularizer=l2(1e-4), name = 'conv' + stage + '_2')(x)
x = Dropout(dropout_rate, name = 'dp' + stage + '_2')(x)
return x
dropout_rate = 0.5
act = "relu"
def Nest_UNet(input_size = (None, None, 1), num_class = 2, deep_supervision = False):
#class 0: Background
#class 1: Lesions
nb_filter = [32,64,128,256,512]
#Handle Dimension Ordering for different backends
global bn_axis
if K.image_dim_ordering() == 'tf':
bn_axis = 3
else:
bn_axis = 1
img_input = Input(input_size, name = 'main_input')
conv1_1 = standard_unit(img_input, stage = '11', nb_filter = nb_filter[0])
pool1 = MaxPooling2D(2, strides=2, name='pool1')(conv1_1)
#pool1 = dilatedConv(conv1_1, stage = '11', nb_filter = nb_filter[0])
conv2_1 = standard_unit(pool1, stage='21', nb_filter=nb_filter[1])
pool2 = MaxPooling2D(2, strides=2, name='pool2')(conv2_1)
#pool2 = dilatedConv(conv2_1, stage = '21', nb_filter = nb_filter[1])
up1_2 = Conv2DTranspose(nb_filter[0], 2, strides=2, padding='same', activation = act, kernel_initializer = 'he_normal', kernel_regularizer=l2(1e-4), name='up12')(conv2_1)
conv1_2 = concatenate([up1_2, conv1_1], name='merge12', axis=bn_axis)
conv1_2 = standard_unit(conv1_2, stage='12', nb_filter=nb_filter[0])
conv3_1 = standard_unit(pool2, stage='31', nb_filter=nb_filter[2])
pool3 = MaxPooling2D(2, strides=2, name='pool3')(conv3_1)
#pool3 = dilatedConv(conv3_1, stage = '31', nb_filter = nb_filter[2])
up2_2 = Conv2DTranspose(nb_filter[1], 2, strides=2, padding='same', activation = act, kernel_initializer = 'he_normal', kernel_regularizer=l2(1e-4), name='up22')(conv3_1)
conv2_2 = concatenate([up2_2, conv2_1], name='merge22', axis=bn_axis)
conv2_2 = standard_unit(conv2_2, stage='22', nb_filter=nb_filter[1])
up1_3 = Conv2DTranspose(nb_filter[0], 2, strides=2, padding='same', activation = act, kernel_initializer = 'he_normal', kernel_regularizer=l2(1e-4), name='up13')(conv2_2)
conv1_3 = concatenate([up1_3, conv1_1, conv1_2], name='merge13', axis=bn_axis)
conv1_3 = standard_unit(conv1_3, stage='13', nb_filter=nb_filter[0])
conv4_1 = standard_unit(pool3, stage='41', nb_filter=nb_filter[3])
pool4 = MaxPooling2D(2, strides=2, name='pool4')(conv4_1)
#pool4 = dilatedConv(conv4_1, stage = '41', nb_filter = nb_filter[3])
up3_2 = Conv2DTranspose(nb_filter[2], 2, strides=2, padding='same', activation = act, kernel_initializer = 'he_normal', kernel_regularizer=l2(1e-4), name='up32')(conv4_1)
conv3_2 = concatenate([up3_2, conv3_1], name='merge32', axis=bn_axis)
conv3_2 = standard_unit(conv3_2, stage='32', nb_filter=nb_filter[2])
up2_3 = Conv2DTranspose(nb_filter[1], 2, strides=2, padding='same', activation = act, kernel_initializer = 'he_normal', kernel_regularizer=l2(1e-4), name='up23')(conv3_2)
conv2_3 = concatenate([up2_3, conv2_1, conv2_2], name='merge23', axis=bn_axis)
conv2_3 = standard_unit(conv2_3, stage='23', nb_filter=nb_filter[1])
up1_4 = Conv2DTranspose(nb_filter[0], 2, strides=2, padding='same', activation = act, kernel_initializer = 'he_normal', kernel_regularizer=l2(1e-4), name='up14')(conv2_3)
conv1_4 = concatenate([up1_4, conv1_1, conv1_2, conv1_3], name='merge14', axis=bn_axis)
conv1_4 = standard_unit(conv1_4, stage='14', nb_filter=nb_filter[0])
conv5_1 = standard_unit(pool4, stage='51', nb_filter=nb_filter[4])
up4_2 = Conv2DTranspose(nb_filter[3], 2, strides=2, padding='same', activation = act, kernel_initializer = 'he_normal', kernel_regularizer=l2(1e-4), name='up42')(conv5_1)
conv4_2 = concatenate([up4_2, conv4_1], name='merge42', axis=bn_axis)
conv4_2 = standard_unit(conv4_2, stage='42', nb_filter=nb_filter[3])
up3_3 = Conv2DTranspose(nb_filter[2], 2, strides=2, padding='same', activation = act, kernel_initializer = 'he_normal', kernel_regularizer=l2(1e-4), name='up33')(conv4_2)
conv3_3 = concatenate([up3_3, conv3_1, conv3_2], name='merge33', axis=bn_axis)
conv3_3 = standard_unit(conv3_3, stage='33', nb_filter=nb_filter[2])
up2_4 = Conv2DTranspose(nb_filter[1], 2, strides=2, padding='same', activation = act, kernel_initializer = 'he_normal', kernel_regularizer=l2(1e-4), name='up24')(conv3_3)
conv2_4 = concatenate([up2_4, conv2_1, conv2_2, conv2_3], name='merge24', axis=bn_axis)
conv2_4 = standard_unit(conv2_4, stage='24', nb_filter=nb_filter[1])
up1_5 = Conv2DTranspose(nb_filter[0], 2, strides=2, padding='same', activation = act, kernel_initializer = 'he_normal', kernel_regularizer=l2(1e-4), name='up15')(conv2_4)
conv1_5 = concatenate([up1_5, conv1_1, conv1_2, conv1_3, conv1_4], name='merge15', axis=bn_axis)
conv1_5 = standard_unit(conv1_5, stage='15', nb_filter=nb_filter[0])
nestnet_output_1 = Conv2D(num_class, 1, activation='softmax', name='output_1', kernel_initializer = 'he_normal', padding='same', kernel_regularizer=l2(1e-4))(conv1_2)
nestnet_output_2 = Conv2D(num_class, 1, activation='softmax', name='output_2', kernel_initializer = 'he_normal', padding='same', kernel_regularizer=l2(1e-4))(conv1_3)
nestnet_output_3 = Conv2D(num_class, 1, activation='softmax', name='output_3', kernel_initializer = 'he_normal', padding='same', kernel_regularizer=l2(1e-4))(conv1_4)
nestnet_output_4 = Conv2D(num_class, 1, activation='softmax', name='output_4', kernel_initializer = 'he_normal', padding='same', kernel_regularizer=l2(1e-4))(conv1_5)
nestnet_output_5 = concatenate([nestnet_output_4, nestnet_output_3, nestnet_output_2, nestnet_output_1], name = "mergeAll", axis = bn_axis)
nestnet_output_5 = Conv2D(num_class, 1, activation='softmax', name='output_5', kernel_initializer = 'he_normal', padding='same', kernel_regularizer=l2(1e-4))(nestnet_output_5)
if deep_supervision:
model = Model(input=img_input, output = nestnet_output_5)
else:
model = Model(input=img_input, output = nestnet_output_4)
return model
with tf.device("/cpu:0"):
#initialize the model
model = Nest_UNet(deep_supervision = False)
#make the model parallel
model = multi_gpu_model(model, gpus = Gpu)
#initialize the optimizer and model
optimizer = Adam(lr = init_lr, beta_1 = beta1, beta_2 = beta2)
model.compile(loss = dice_loss, optimizer = optimizer, metrics = [dsc])
callbacks = [LearningRateScheduler(poly_decay)]
#train the network
aug = ImageDataGenerator(rotation_range = 10, width_shift_range = 0.1, height_shift_range = 0.1, horizontal_flip = True, fill_mode = "nearest")
aug.fit(trainX)
train = model.fit_generator(aug.flow(x = trainX, y = trainY, batch_size = batch_size * Gpu), steps_per_epoch = len(trainX) // (batch_size * Gpu),
epochs = n_epoch, verbose = 2, callbacks = callbacks, validation_data = (validX, validY), shuffle = True)
intersect和denom吗?顺便说一下,你可以在dice_loss()中使用dsc()函数代替coef2,这将减少可能出现错误的地方。 - winddice_loss()中我使用了dsc()函数,但是没有任何变化。 - Md Sharique