我要翻译的正则表达式有以下限制:
- 以"//"开头
- 随后是"["一个非数字序列(称为分隔符)和"]"
- 下一行是"\n"
- "[" 0个或多个由先前找到的分隔符分隔的数字。
例如,以下文本与正则表达式匹配:
//[*#*]
[1*#*34*#*64]
以下文本与正则表达式不匹配:
//[*#*]
[1#34#64]
因为分隔符与第一行不匹配,所以出现了这个问题。
我目前创建的正则表达式是:
^//\[(\D)+\]\n\[[(\d)+(\D)+]*(\d)+\]$|^//\[(\D)+\]\n\[\]$|^//\[(\D)+\]\n\[(\d)+\]$
但是很明显,这个正则表达式与前面的两个示例都匹配。
是否有一种方法可以在正则表达式本身中“召回”已匹配的字符序列?
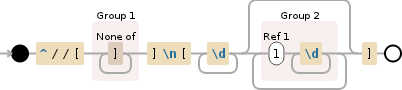
\(.*\)\1匹配任何形式为<s><s>的字符串。这意味着一个由将一个字符串连接到自身而成的字符串。 - Guido