我正在学习用于大学考试的ID3算法,但是我对如何选择最佳属性以创建具有较少属性的新子树(直到创建叶子)仍有些困惑。
因此,我将介绍一些我在老师讲课笔记中发现的实际例子,并希望有人能够给我提供一些实际帮助来解决我的疑问。
这是我想要构建的最终决策树:
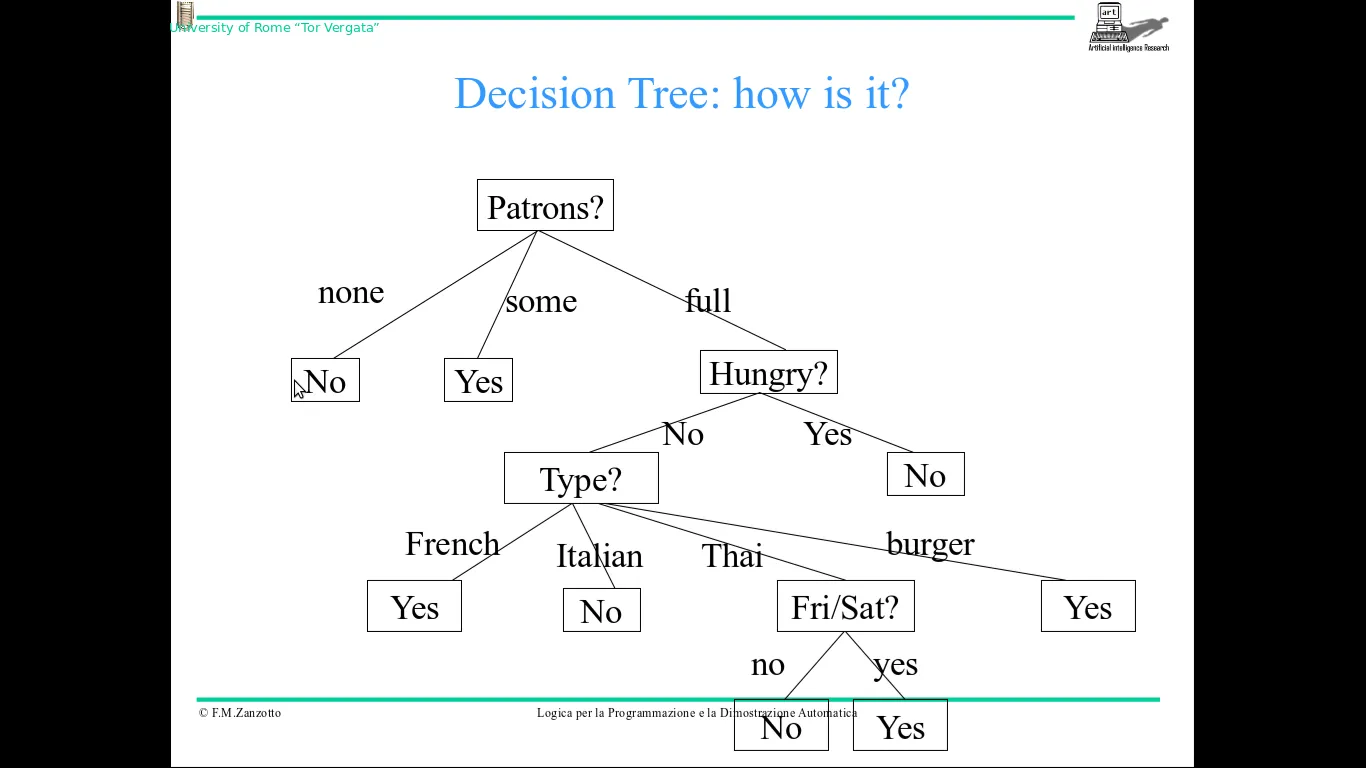
这个决策树简单地说明当我在餐厅时是否需要等待。
例如:如果有许多顾客(顾客属性=many),他们饥饿(饥饿属性=yes)并且所选烹饪类型为法国菜(类型属性=French),则意味着我需要等待。而如果没有顾客(顾客属性=no),则可以立即得出结论,我不必等待。
好的,因此使用决策树非常简单。
这是表示前面决策树示例的域的表格(还有一些其他属性,但我认为这不是很重要):
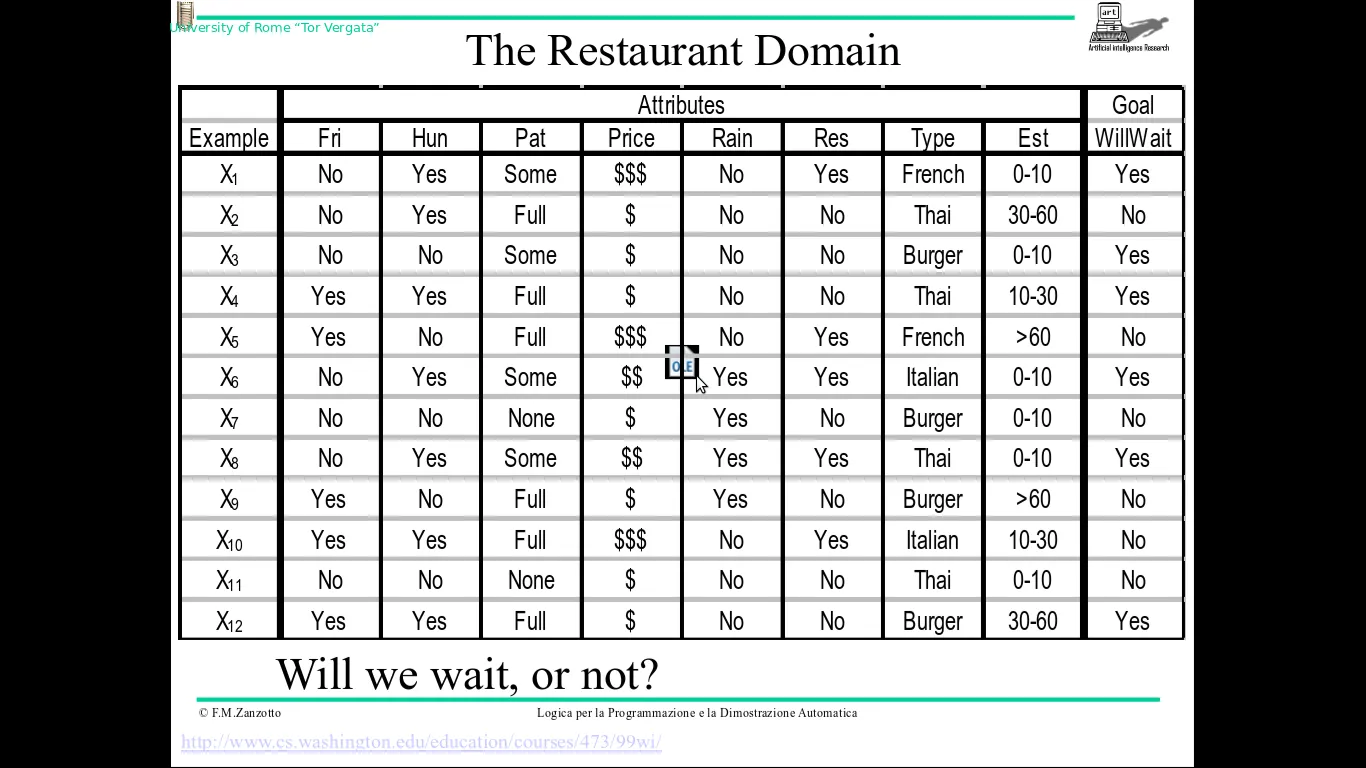
因此,如果我说错了,请纠正我,这个表提供给我12个例子,显示常见情况,并将由ID3算法用于构建我的决策树。
以下是ID3算法的伪代码:
ID3 (Examples, Target_Attribute, Attributes)
Create a root node for the tree
If all examples are positive, Return the single-node tree Root, with label = +.
If all examples are negative, Return the single-node tree Root, with label = -.
If number of predicting attributes is empty, then Return the single node tree Root,
with label = most common value of the target attribute in the examples.
Otherwise Begin
A ← The Attribute that best classifies examples.
Decision Tree attribute for Root = A.
For each possible value, v_i, of A,
Add a new tree branch below Root, corresponding to the test A = v_i.
Let Examples(v_i) be the subset of examples that have the value v_i for A
If Examples(v_i) is empty
Then below this new branch add a leaf node with label = most common target value in the examples
Else below this new branch add the subtree ID3 (Examples(v_i), Target_Attribute, Attributes – {A})
End
Return Root
所以,这个算法从创建一个根节点开始,在这个节点中,我将根据我将事件分类的类别,放置由前面表格提供的所有示例。
在这种情况下,我仅将前面的12个示例分成了2个类,相应地对应于:积极的实例(与情况相关:我会在餐厅等待)和消极的实例(与情况相关: 我不会在餐厅等待)
因此,查看前面的表,我的决策树根节点的情况如下: +:X1,X3,X4,X6,X8,X12 (积极的示例) -:X2,X5,X7,X9,10,X11 (消极的实例)
这些示例相关的属性是前面表中存在的属性:Fri,Hun,Pat,Price,Rain,Res,Type,Est 我认为这些属性并没有全部用于我的决策树,因为我可以不使用所有属性来达到目标(结论)。
现在,我已将示例分为正案例和负案例,并且我必须选择最佳的第一个属性(即先前属性中最相关的属性)。
实际上,我必须执行以下第一步:
他选择了patrons属性作为此第一个分支步骤的最佳属性。
此属性可以具有以下值:None (餐厅没有顾客),Some (有少数顾客),Full (餐厅客满),因此我必须在3个子树中进行分支(并将相关的情况放入这些树的相关根节点标签中)。
我的问题是: 如何选择最佳节点? 我知道我必须使用熵值:
用于计算所有属性的信息增益:
并在对所有属性执行此操作后,我必须选择 信息增益 最高的那个属性作为 最佳属性。但是,我在将这些公式应用于我将首先选择Patrons属性的最佳属性的具体案例时遇到一些问题。请问有人能向我展示如何在具体案例中应用这些公式吗?
非常感谢。
安德里亚。