如何高效地复制一个向量?
我目前的印象是,repmat比其他任何方法都要优秀。或者我的想法完全错误吗?
使用不同的技术是否可能产生与repmat完全相同的结果?也许是普通矩阵乘法?
我要表达最大的感激之情,感谢你们的关注和支持性的回答!
AER
如何高效地复制一个向量?
我目前的印象是,repmat比其他任何方法都要优秀。或者我的想法完全错误吗?
使用不同的技术是否可能产生与repmat完全相同的结果?也许是普通矩阵乘法?
我要表达最大的感激之情,感谢你们的关注和支持性的回答!
AER
简而言之,bsxfun 在起始向量较长或重复次数足够大时比你所要求的两种方法更快(见下文),否则矩阵乘法更有效率。在你提出的这两种方法中,矩阵乘法+reshape 的效率比 repmat 高约 3 倍。我使用 timeit 的方式是,我创建了一个包含 1e5 个元素的随机向量,并检查创建其 100 个重复需要多长时间:
v=rand(1e5,1);
f1=@()repmat(v,[100,1])
f2=@() reshape(v*ones(1,100),[],1);
timeit(f1)
ans =
0.1675
timeit(f2)
ans =
0.0516
然而,bsxfun 更快:
f3=@() reshape(bsxfun(@times,v,ones(1,100)),[],1)
timeit(f3)
ans =
0.0374
以下是对这一观察的更加仔细的研究:
给定一个长度为1000的向量,将其重复10到1e5次,得到以下性能时间:
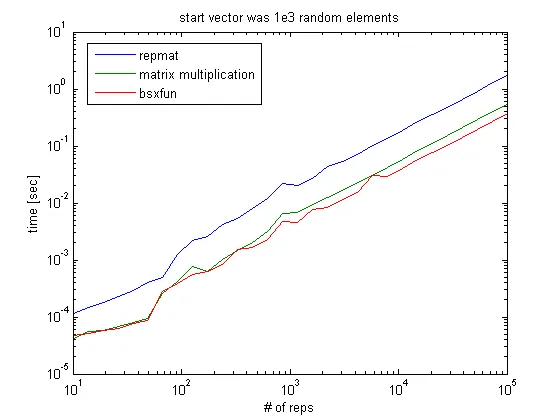
bsxfun和矩阵乘法之间几乎没有区别,但当重复次数超过约1e3时,bsxfun明显更快。bsxfun才开始变得更好,但即使在这种情况下,速度也只快了约5%(未显示):
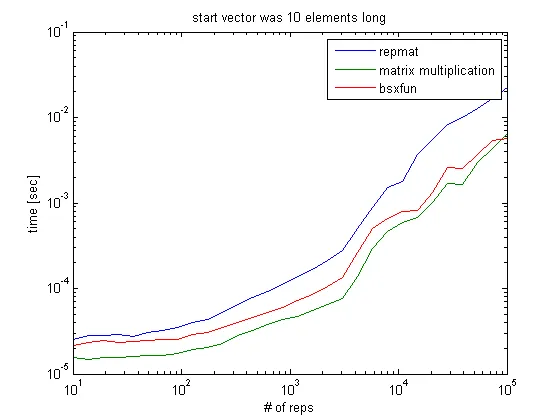
所以这取决于你想要什么。更多讨论可以在MATLAB博客上的Loren on the Art of MATLAB中找到。
目前来看,repmat函数大多数情况下比普通索引慢,普通索引的工作原理如下:
经典的repmat函数:
a = [ 1 2 3 ];
repmat(a,4,1)
>>
[1 2 3;
1 2 3;
1 2 3;
1 2 3];
这个的索引版本:
a(ones(4,1),:);
这将会得到完全相同的结果。
这取决于您想要什么类型的向量。例如,如果您想要一个特殊的向量,比如一行全是1的向量,那么
tic
repmat([1],3,5)
toc
tic
ones(3,5)
toc
会告诉你使用"ones"大约快3倍(至少在我的机器上是这样)。你可以随时使用tic和toc来测量哪种方法更快。 我们再试一个...
tic
repmat([1,2,3],1,2)
toc
tic
cat(2,[1,2,3],[1,2,3])
toc
现在的cat又快了3倍,但它有明显的局限性。希望这可以帮到你。