我有一个字符串,由Jericho HTML解析器返回,并包含一些俄文文本。根据
如何将此字符串转换为可读的格式?
我尝试了这个:
变量
这不起作用 -
如何修复它,即确保正确解码Windows-1251字符串?
更新1(2015年7月30日12:45 MSK):当在
source.getEncoding()和相应HTML文件的头信息,编码是Windows-1251。如何将此字符串转换为可读的格式?
我尝试了这个:
import java.io.UnsupportedEncodingException;
public class Program {
public void run() throws UnsupportedEncodingException {
final String windows1251String = getWindows1251String();
System.out.println("String (Windows-1251): " + windows1251String);
final String readableString = convertString(windows1251String);
System.out.println("String (converted): " + readableString);
}
private String convertString(String windows1251String) throws UnsupportedEncodingException {
return new String(windows1251String.getBytes(), "UTF-8");
}
private String getWindows1251String() {
final byte[] bytes = new byte[] {32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, -17, -65, -67, -17, -65, -67, -17, -65, -67, -17, -65, -67, -17, -65, -67, -17, -65, -67, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32};
return new String(bytes);
}
public static void main(final String[] args) throws UnsupportedEncodingException {
final Program program = new Program();
program.run();
}
}
变量
bytes包含在我的调试器中显示的数据,它是net.htmlparser.jericho.Element.getContent().toString().getBytes()的结果。我只是将该数组复制并粘贴到这里。这不起作用 -
readableString包含垃圾数据。如何修复它,即确保正确解码Windows-1251字符串?
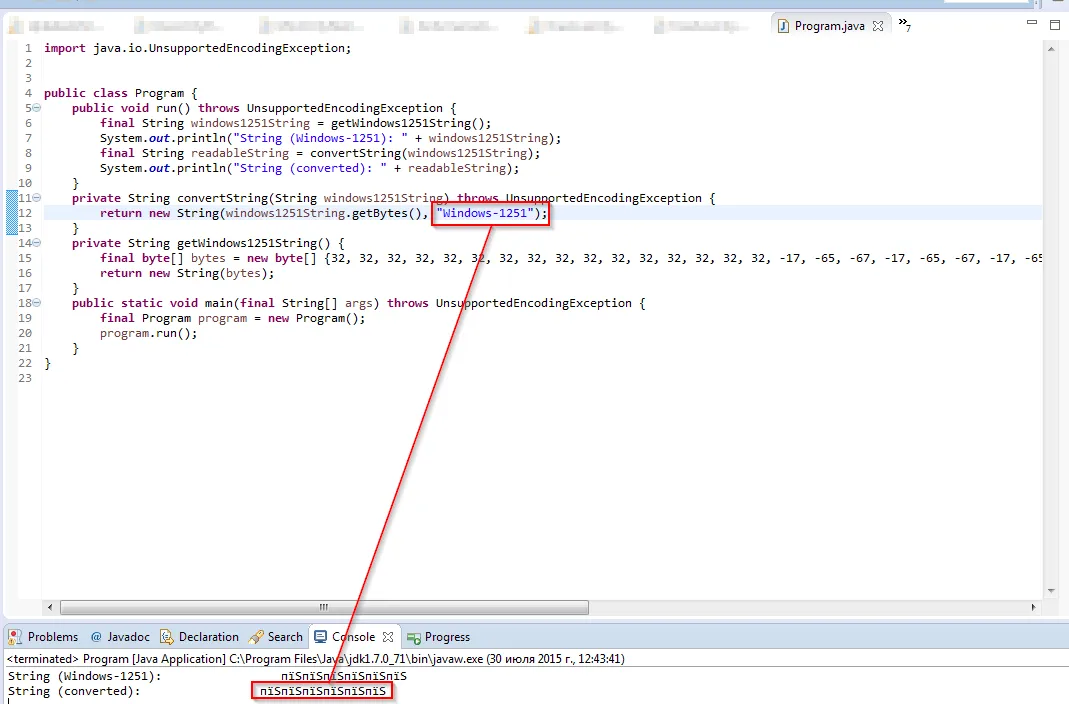
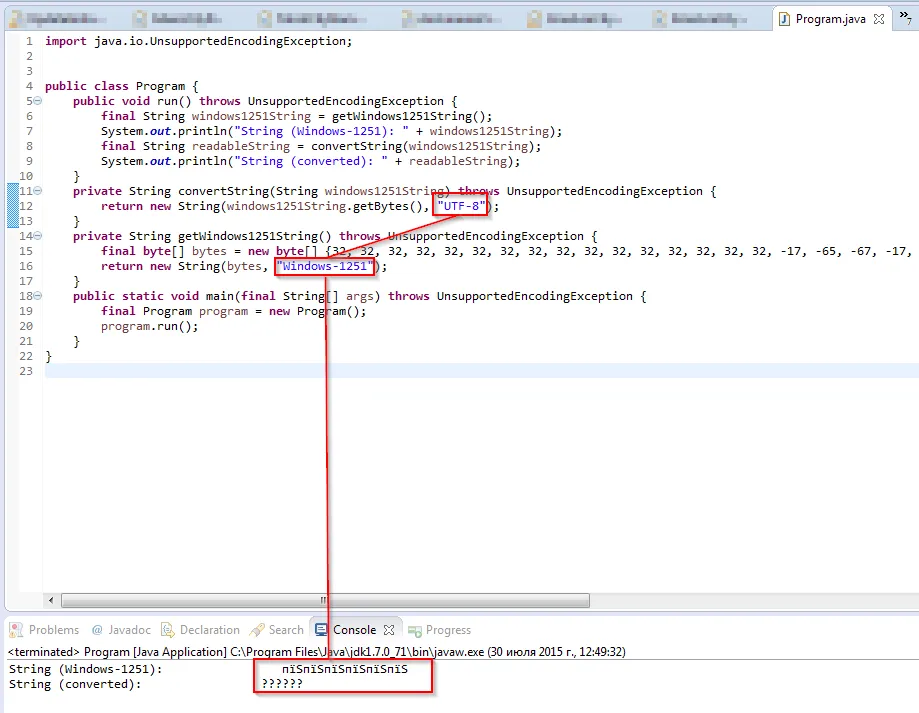
更新1(2015年7月30日12:45 MSK):当在
convertString的调用中更改编码为Windows-1251时,没有任何变化。请参见下面的屏幕截图。
public static String guessEncoding(byte[] bytes) {
String DEFAULT_ENCODING = "UTF-8";
org.mozilla.universalchardet.UniversalDetector detector =
new org.mozilla.universalchardet.UniversalDetector(null);
detector.handleData(bytes, 0, bytes.length);
detector.dataEnd();
String encoding = detector.getDetectedCharset();
System.out.println("Detected encoding: " + encoding);
detector.reset();
if (encoding == null) {
encoding = DEFAULT_ENCODING;
}
return encoding;
}
new String(bytes, "Windows-1251")吗? - undefinedgetWindows1251String函数中。new String()可能已经尝试在那里生成一个UTF-8字符串,请参考http://docs.oracle.com/javase/7/docs/api/java/lang/String.html#String%28byte[]%29。 - undefined