我一直在尝试使用Perl程序计算优秀数字。虽然我的解决方案运行时间可以接受,但我认为另一种语言,特别是为数值计算设计的语言,可能会更快。一个朋友建议使用Julia,但我看到的性能很差,肯定是我做错了什么。我已经查看了性能提示,但没有看到应该改进的地方:
digits = int( ARGS[1] )
const k = div( digits, 2 )
for a = ( 10 ^ (k - 1) ) : ( 10 ^ (k) - 1 )
front = a * (10 ^ k + a)
root = floor( front ^ 0.5 )
for b = ( root - 1 ): ( root + 1 )
back = b * (b - 1);
if back > front
break
end
if log(10,b) > k
continue
end
if front == back
@printf "%d%d\n" a b
end
end
end
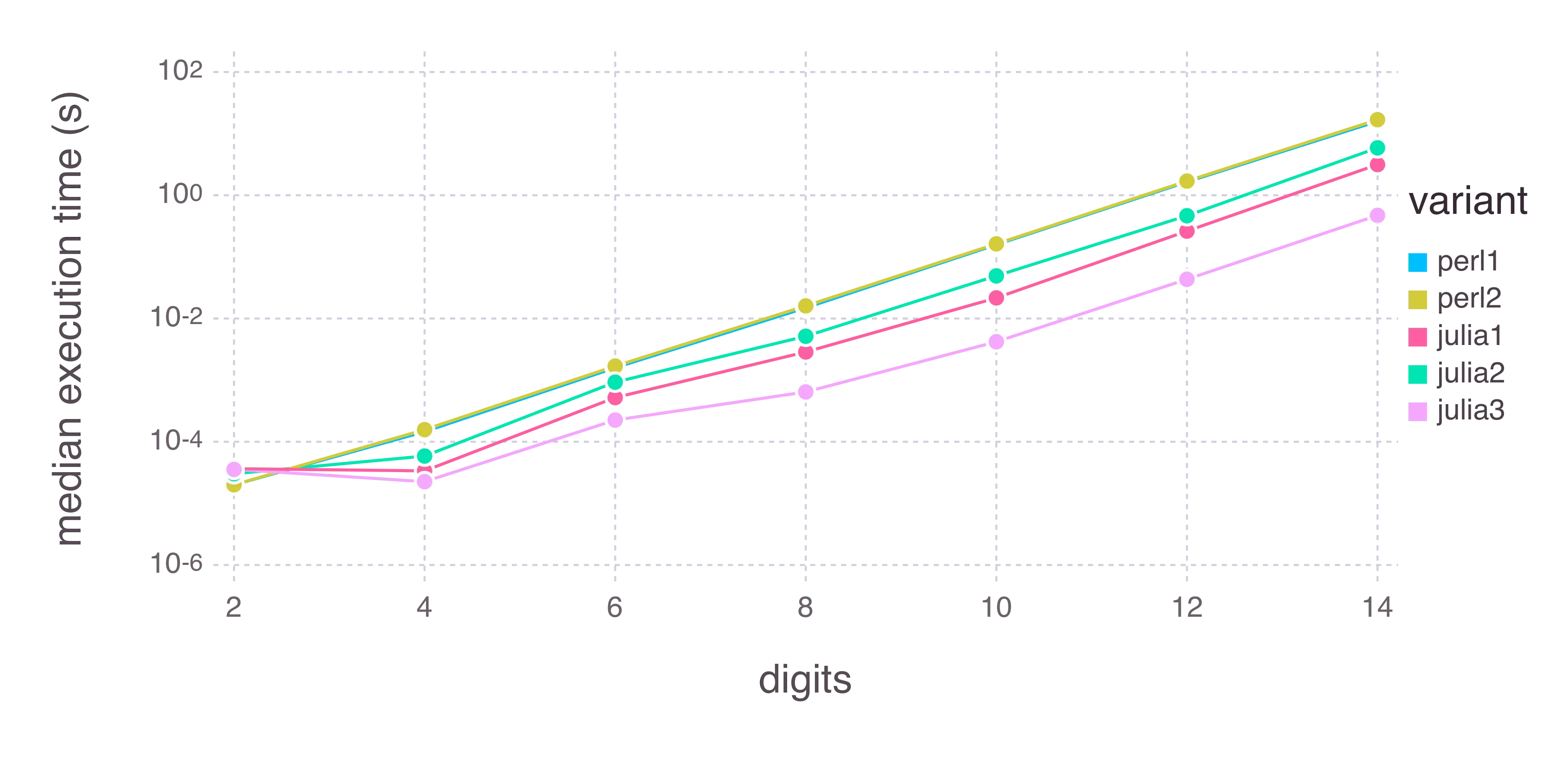
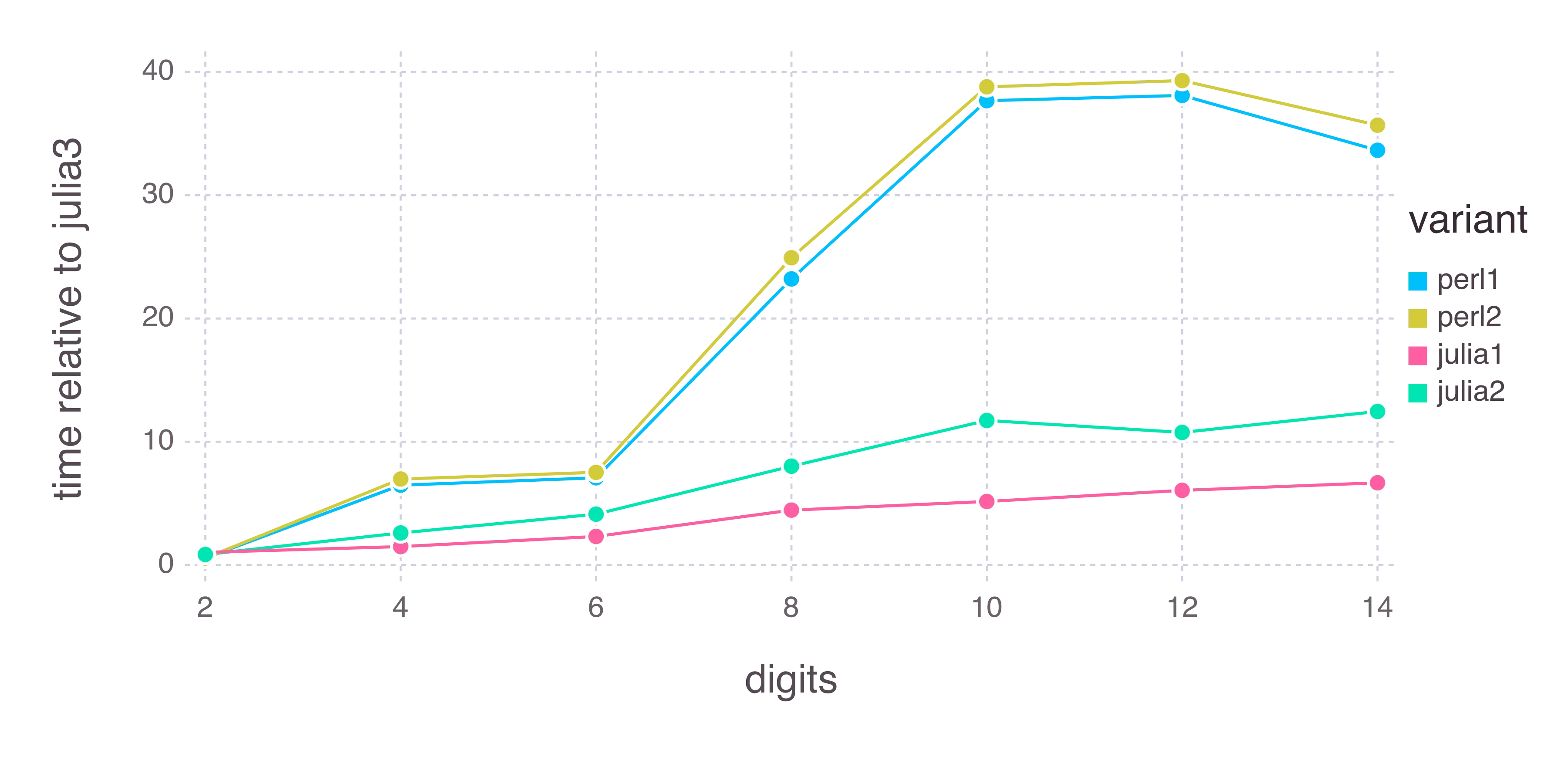
我有一个等效的 C 程序,比 Julia page 上提到的因子 2 快一个数量级(尽管关于 Julia 速度的大多数 Stackoverflow 问题似乎都指出该页面上的基准测试存在缺陷):
而我编写的未经优化的纯 Perl 只需要一半的时间:
use v5.20;
my $digits = $ARGV[0] // 2;
die "Number of digits must be even and non-zero! You said [$digits]\n"
unless( $digits > 0 and $digits % 2 == 0 and int($digits) eq $digits );
my $k = ( $digits / 2 );
foreach my $n ( 10**($k-1) .. 10**($k) - 1 ) {
my $front = $n*(10**$k + $n);
my $root = int( sqrt( $front ) );
foreach my $try ( $root - 2 .. $root + 2 ) {
my $back = $try * ($try - 1);
last if length($try) > $k;
last if $back > $front;
# say "\tn: $n back: $back try: $try front: $front";
if( $back == $front ) {
say "$n$try";
last;
}
}
}
我正在使用预编译的Julia,因为我无法编译源代码(但我没有尝试过第一次失败后再试)。我想这是其中的一部分。
此外,我发现任何Julia程序的启动时间约为0.7秒(请参见Slow Julia Startup Time),这意味着等价的编译C程序可以在Julia完成一次运行前运行约200次。随着运行时间的增加(
digits值较大),启动时间变得越来越少,我的Julia程序仍然非常慢。我还没有涉及到非常大的数字部分(20+位优秀数字),我没有意识到Julia在处理这些数字方面并不比大多数其他语言更好。
这是我的C代码,与我开始时有些不同。我的生疏、不优雅的C技能与我的Perl基本相同。
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
int main( int argc, char *argv[] ) {
long
k, digits,
start, end,
a, b,
front, back,
root
;
digits = atoi( argv[1] );
k = digits / 2;
start = (long) pow(10, k - 1);
end = (long) pow(10, k);
for( a = start; a < end; a++ ) {
front = (long) a * ( pow(10,k) + a );
root = (long) floor( sqrt( front ) );
for( b = root - 1; b <= root + 1; b++ ) {
back = (long) b * ( b - 1 );
if( back > front ) { break; }
if( log10(b) > k ) { continue; }
if( front == back ) {
printf( "%ld%ld\n", a, b );
}
}
}
return 0;
}
log(10,b)上。如果b始终为正数,则可能有一个宏可用于跳过log函数中的域检查,尽管我认为这不会带来太大的差异。这不是一个答案,但这可能会指引您朝着进一步减少运行时间的正确方向前进。 - Colin T Bowers