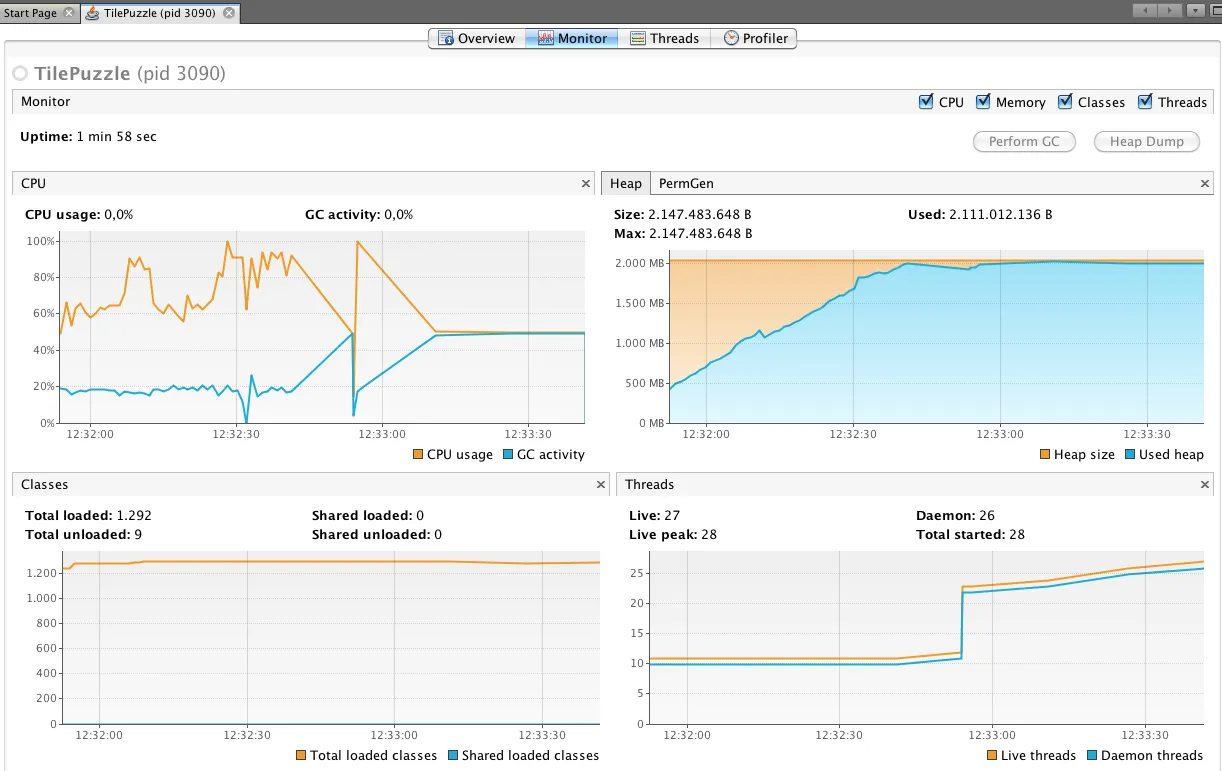
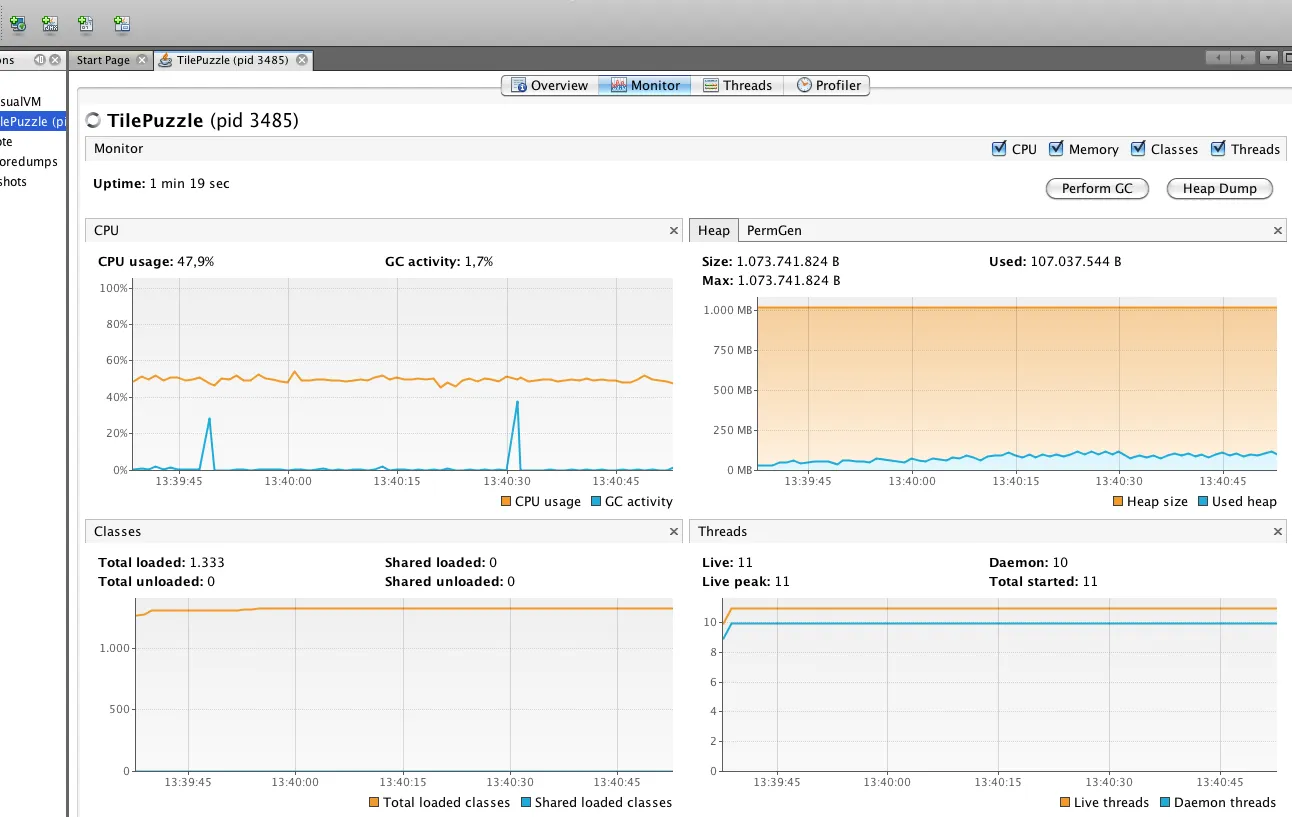
我正在使用Java进行开发。我的要求是必须比较两个数据库查询。为了实现这一点,我将结果集的每一行分配给一个HashTable,其中字段名作为“键”,字段中的数据作为“值”。然后,我将整个HashTable结果集分组到单个Vector中,仅作为容器。因此,为了比较两个查询,我实际上正在遍历两个HashTable向量。
我发现这种方法非常适合我,但需要大量内存。由于其他设计要求,我必须通过类似Vector-HashTable的结构进行比较,而不是通过数据库端的过程。
有人有优化建议吗?最佳解决方案应该与我现在正在做的相似,因为大部分代码已经围绕它设计。
谢谢
我发现这种方法非常适合我,但需要大量内存。由于其他设计要求,我必须通过类似Vector-HashTable的结构进行比较,而不是通过数据库端的过程。
有人有优化建议吗?最佳解决方案应该与我现在正在做的相似,因为大部分代码已经围绕它设计。
谢谢