在我的GCE Kubernetes集群上,我无法再创建Pod。
Warning FailedScheduling pod (www.caveconditions.com-f1be467e31c7b00bc983fbe5efdbb8eb-438ef) failed to fit in any node
fit failure on node (gke-prod-cluster-default-pool-b39c7f0c-c0ug): Insufficient CPU
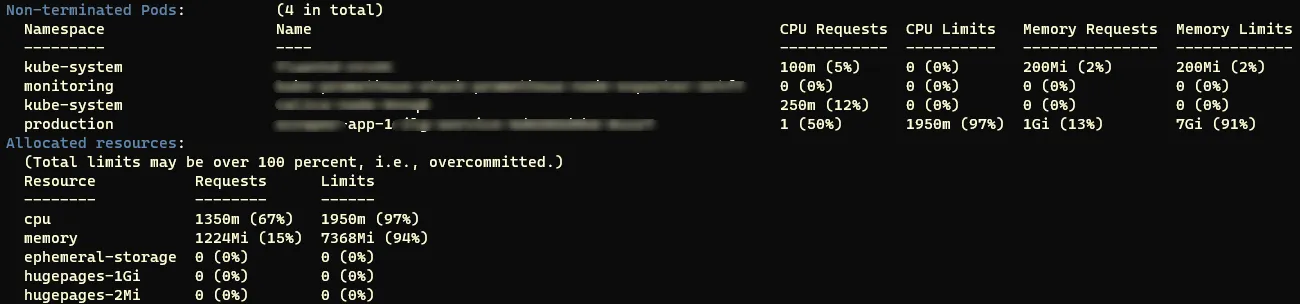
查看该节点的分配统计信息
Non-terminated Pods: (8 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
default dev.caveconditions.com-n80z8 100m (10%) 0 (0%) 0 (0%) 0 (0%)
default lamp-cnmrc 100m (10%) 0 (0%) 0 (0%) 0 (0%)
default mongo-2-h59ly 200m (20%) 0 (0%) 0 (0%) 0 (0%)
default www.caveconditions.com-tl7pa 100m (10%) 0 (0%) 0 (0%) 0 (0%)
kube-system fluentd-cloud-logging-gke-prod-cluster-default-pool-b39c7f0c-c0ug 100m (10%) 0 (0%) 200Mi (5%) 200Mi (5%)
kube-system kube-dns-v17-qp5la 110m (11%) 110m (11%) 120Mi (3%) 220Mi (5%)
kube-system kube-proxy-gke-prod-cluster-default-pool-b39c7f0c-c0ug 100m (10%) 0 (0%) 0 (0%) 0 (0%)
kube-system kubernetes-dashboard-v1.1.0-orphh 100m (10%) 100m (10%) 50Mi (1%) 50Mi (1%)
Allocated resources:
(Total limits may be over 100%, i.e., overcommitted. More info: http://releases.k8s.io/HEAD/docs/user-guide/compute-resources.md)
CPU Requests CPU Limits Memory Requests Memory Limits
------------ ---------- --------------- -------------
910m (91%) 210m (21%) 370Mi (9%) 470Mi (12%)
我已经分配了91%的资源,无法再增加10%。但是难道不能超额使用资源吗?
服务器的使用率平均约为10%的CPU。
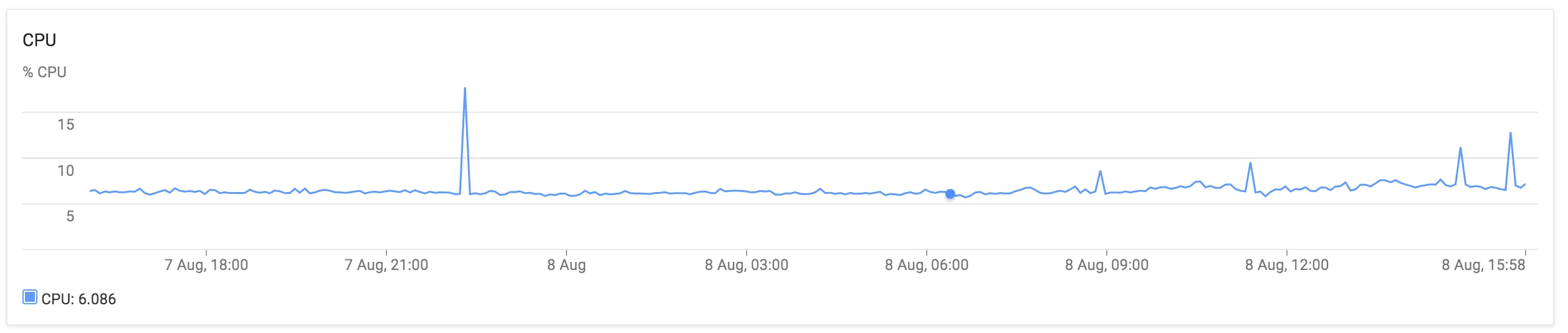
我需要做哪些更改,使得我的 Kubernetes 集群能够创建更多的 Pod?