我需要检查200个HTTP URL的状态并找出其中哪些是坏链接。这些链接存在一个简单的文本文件中(比如在我的~文件夹中的URL.txt)。我正在使用Ubuntu 14.04,并且我是一个Linux新手。但我知道Bash shell非常强大,可以帮助我实现我的目标。
我的确切要求是读取包含URL列表的文本文件,自动检查链接是否有效,并将响应写入一个新文件,该文件包含URL及其对应的状态(工作/坏)。
我需要检查200个HTTP URL的状态并找出其中哪些是坏链接。这些链接存在一个简单的文本文件中(比如在我的~文件夹中的URL.txt)。我正在使用Ubuntu 14.04,并且我是一个Linux新手。但我知道Bash shell非常强大,可以帮助我实现我的目标。
我的确切要求是读取包含URL列表的文本文件,自动检查链接是否有效,并将响应写入一个新文件,该文件包含URL及其对应的状态(工作/坏)。
我创建了一个名为“checkurls.sh”的文件,并将其放置在我的主目录中,与urls.txt文件位于同一目录下。我使用以下命令给该文件赋予执行权限:
$chmod +x checkurls.sh
checkurls.sh的内容如下:
#!/bin/bash
while read url
do
urlstatus=$(curl -o /dev/null --silent --head --write-out '%{http_code}' "$url" )
echo "$url $urlstatus" >> urlstatus.txt
done < $1
最终,我通过以下命令行执行它-
$./checkurls.sh urls.txt
哇!它可以工作。
curl -H'Cache-Control:no-cache'-o /dev/null --silent --head --write-out'%{http_code} %{redirect_url}'来解决大多数301问题。 - Alex Bauer#!/bin/bash
while read -ru 4 LINE; do
read -r REP < <(exec curl -IsS "$LINE" 2>&1)
echo "$LINE: $REP"
done 4< "$1"
使用方法:
bash script.sh urls-list.txt
示例:
http://not-exist.com/abc.html
https://kernel.org/nothing.html
http://kernel.org/index.html
https://kernel.org/index.html
输出:
http://not-exist.com/abc.html: curl: (6) Couldn't resolve host 'not-exist.com'
https://kernel.org/nothing.html: HTTP/1.1 404 Not Found
http://kernel.org/index.html: HTTP/1.1 301 Moved Permanently
https://kernel.org/index.html: HTTP/1.1 200 OK
对于所有的内容,请阅读Bash手册。此外,还需查看man curl、help和man bash。
如果给这个已被接受的解决方案增加一些并行性会怎么样呢?让我们修改脚本chkurl.sh,使其更易于阅读,并一次处理一个请求:
#!/bin/bash
URL=${1?Pass URL as parameter!}
curl -o /dev/null --silent --head --write-out "$URL %{http_code} %{redirect_url}\n" "$URL"
现在,您可以使用以下方法检查您的列表:
cat URL.txt | xargs -P 4 -L1 ./chkurl.sh
这是完整的脚本,它会检查作为参数传递的文件中列出的URL,例如“checkurls.sh listofurls.txt”。
它的功能包括:
代码:
#!/bin/sh
EMAIL=" your@email.com"
DATENOW=`date +%Y%m%d-%H%M%S`
LOG_FILE="checkurls.log"
c=0
while read url
do
((c++))
LOCK_FILE="checkurls$c.lock"
urlstatus=$(/usr/bin/curl -H 'Cache-Control: no-cache' -o /dev/null --silent --head --write-out '%{http_code}' "$url" )
if [ "$urlstatus" = "200" ]
then
#echo "$DATENOW OK $urlstatus connection->$url" >> $LOG_FILE
[ -e $LOCK_FILE ] && /bin/rm -f -- $LOCK_FILE > /dev/null && /bin/mail -s "NOTIFICATION URL OK: $url" $EMAIL <<< 'The URL is back online'
else
echo "$DATENOW FAIL $urlstatus connection->$url" >> $LOG_FILE
if [ -e $LOCK_FILE ]
then
#no action - awaiting URL to be fixed
:
else
/bin/mail -s "NOTIFICATION URL DOWN: $url" $EMAIL <<< 'Failed to reach or URL problem'
/bin/touch $LOCK_FILE
fi
fi
done < $1
# REMOVE LOG FILE IF LARGER THAN 100MB
# alow up to 2000 lines average
maxsize=120000
size=$(/usr/bin/du -k "$LOG_FILE" | /bin/cut -f 1)
if [ $size -ge $maxsize ]; then
/bin/rm -f -- $LOG_FILE > /dev/null
echo "$DATENOW LOG file [$LOG_FILE] has been recreated" > $LOG_FILE
else
#do nothing
:
fi
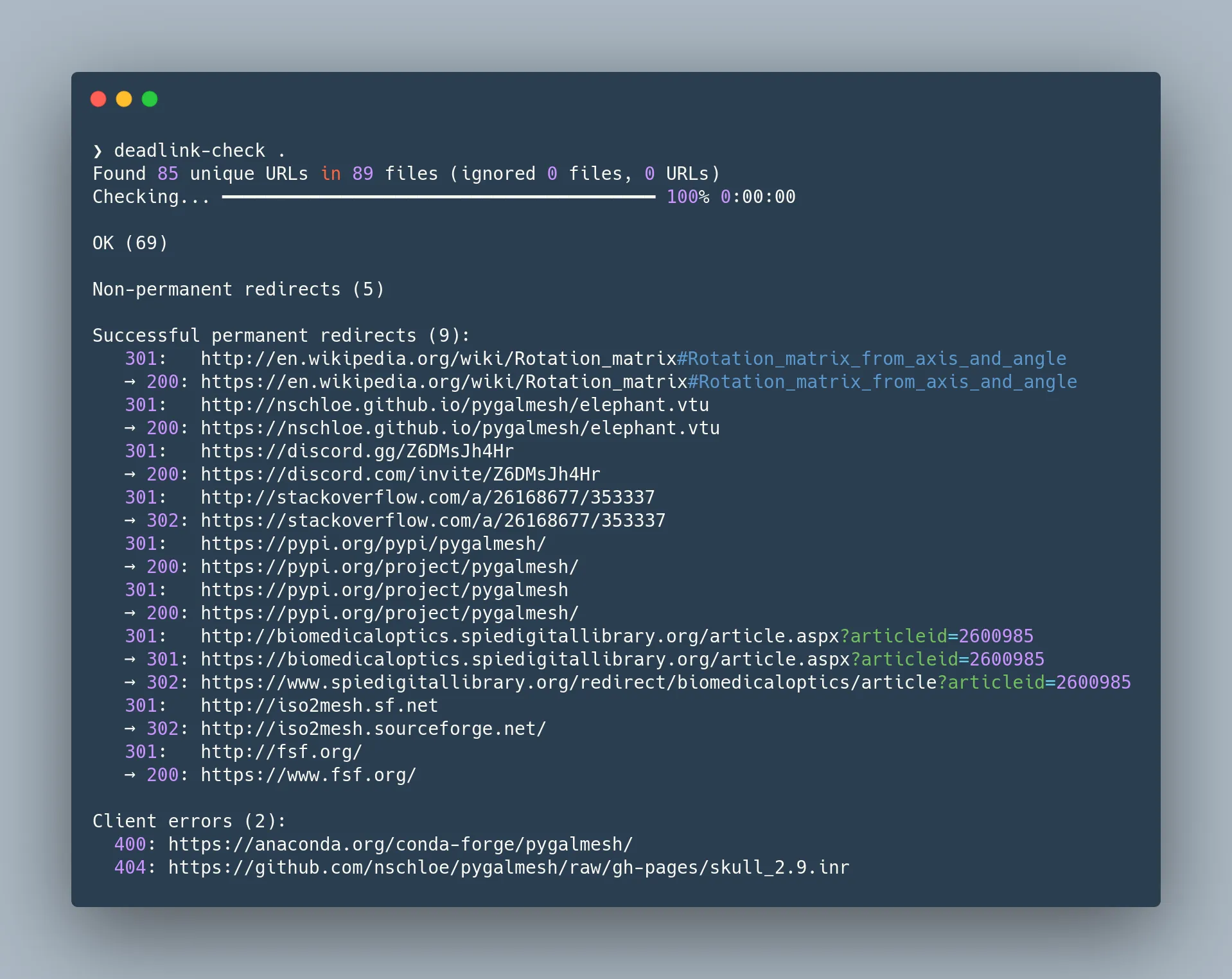
我最近发布了 deadlink,这是一个用于在文件中查找损坏链接的命令行工具。安装方法如下:
pip install deadlink
并使用作为
deadlink check /path/to/file/or/directory
或者
deadlink replace-redirects /path/to/file/or/directory
curl -s -I --http2 http://$1 >> fullscan_curl.txt | cut -d: -f1 fullscan_curl.txt | cat fullscan_curl.txt | grep HTTP >> fullscan_httpstatus.txt
它对我有用
#!/bin/bash
INPUT="Urls.txt"
OUTPUT="result.txt"
while read line ;
do
if ping -c 1 $line &> /dev/null
then
echo "$line valid" >> $OUTPUT
else
echo "$line not valid " >> $OUTPUT
fi
done < $INPUT
exit
ping 选项:
-c count
Stop after sending count ECHO_REQUEST packets. With deadline option, ping waits for count ECHO_REPLY packets, until the timeout expires.
你也可以使用这个选项来限制等待时间
-W timeout
Time to wait for a response, in seconds. The option affects only timeout in absense
of any responses, otherwise ping waits for two RTTs.