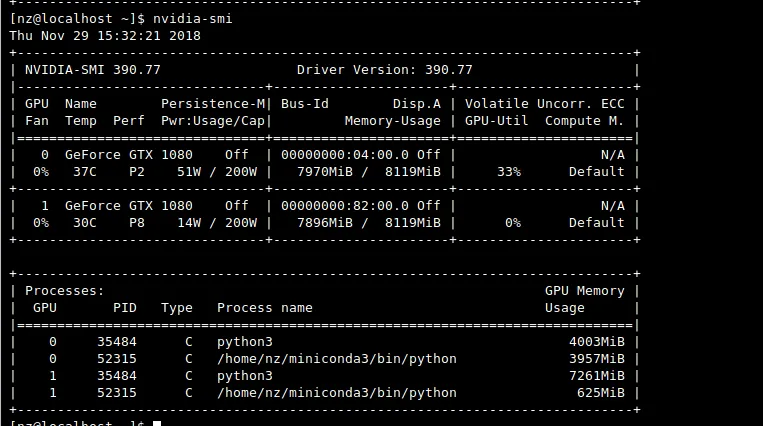
在我的机构中有一个共享服务器,其中有2个GPU。假设有两个团队成员同时想要训练模型,那么他们如何让Keras在特定的GPU上训练他们的模型以避免资源冲突?
理想情况下,Keras应该能够确定哪个GPU正在繁忙地训练模型,然后使用另一个GPU来训练其他模型。然而,事实并非如此。似乎默认情况下Keras只使用第一个GPU(因为第二个GPU的
理想情况下,Keras应该能够确定哪个GPU正在繁忙地训练模型,然后使用另一个GPU来训练其他模型。然而,事实并非如此。似乎默认情况下Keras只使用第一个GPU(因为第二个GPU的
Volatile GPU-Util始终为0%)。