这些技术的核心架构差异是什么?
另外,每种技术通常适用于哪些使用案例?
这些技术的核心架构差异是什么?
另外,每种技术通常适用于哪些使用案例?
现在问题范围已经得到纠正,我可能也会在这方面加些内容:
有很多关于Apache Solr和ElasticSearch的比较可供参考,因此我将引用我自己发现最有用的资料,即涵盖最重要方面的资料:
Bob Yoplait已经链接了kimchy的回答ElasticSearch,Sphinx,Lucene,Solr,Xapian。哪一个适合哪种用途?,他总结了他为什么要创建ElasticSearch的原因,他认为与Solr相比,ElasticSearch提供了更优秀的分布式模型和易用性。
Ryan Sonnek的Realtime Search:Solr vs Elasticsearch提供了深入的分析/比较,并解释了为什么他从Solr转到ElasticSeach,尽管他已经是一个快乐的Solr用户 - 他总结如下:
Solr可能是构建标准搜索应用程序的选择武器,但Elasticsearch通过为创建现代实时搜索应用程序提供架构将其提升到了一个新的水平。 Percolation是一个令人兴奋和创新的功能,它单独地让Solr无法匹敌。 Elasticsearch可扩展,速度快,易于集成。再见,Solr,我很高兴认识你。[强调我]
维基百科上关于ElasticSearch的文章引用了一篇comparison来自德国著名的iX杂志,列出了优缺点,这几乎概括了上面已经说过的:
优点:
- ElasticSearch是分布式的。不需要单独的项目。副本也是近实时的,称为“Push复制”。
- Elasticsearch完全支持Apache Lucene的近实时搜索。
- 处理多租户不是特殊配置,在Solr中需要更高级的设置。
- ElasticSearch引入了网关的概念,使完全备份更容易。
缺点:
只有一个主要开发人员[根据当前elasticsearch GitHub organization,除了一开始就有相当活跃的提交者基础外,不再适用]没有自动预热功能[根据新的Index Warmup API不再适用]
它们是完全不同的技术,解决完全不同的用例,因此无法以任何有意义的方式进行比较:
Apache Solr - Apache Solr在易于使用、快速的搜索服务器中提供了Lucene的功能,并具有分面、可扩展性等其他功能。
Amazon ElastiCache - Amazon ElastiCache是一个Web服务,可轻松部署、操作和扩展云中的内存缓存。
[重点标记为我的]
也许这与以下两个相关技术之一有所混淆:
ElasticSearch - 它是一个基于Apache Lucene构建的开源(Apache 2),分布式,RESTful搜索引擎。
Amazon CloudSearch - Amazon CloudSearch是云中的全托管搜索服务,允许客户轻松地将快速且高度可伸缩的搜索功能集成到其应用程序中。
Solr和ElasticSearch在第一眼看起来非常相似,并且两者都使用相同的后端搜索引擎,即Apache Lucene。
虽然Solr更加老练、多才多艺和成熟,因此被广泛使用,但ElasticSearch是专门为解决现代云环境中的可扩展性要求而开发的,这些要求很难通过Solr来解决。
因此,将 ElasticSearch 与最近推出的 Amazon CloudSearch 进行比较可能是最有用的(请参阅介绍性文章 在一个小时内以每月不到100美元的价格开始搜索),因为两者原则上都声称涵盖相同的用例。
我注意到以上一些答案现在有点过时了。从我的角度来看,我每天都与Solr(云和非云)和ElasticSearch一起工作,以下是一些有趣的区别:
要了解更全面的Solr vs. ElasticSearch主题,请查看https://sematext.com/blog/solr-vs-elasticsearch-part-1-overview/。这是来自Sematext的系列文章中的第一篇,直接、中立地对Solr和ElasticSearch进行比较。声明:我在Sematext工作。
Apache Solr具有悠久的历史,我认为其一个优势就在于其生态系统。有许多Solr插件可用于不同类型和目的的数据。

搜索平台从底部到顶部分为以下层次:
参考文章:企业搜索
我已经创建了一个表格,列出了elasticsearch、Solr和splunk之间的主要差异,你可以将其用作2016年的更新: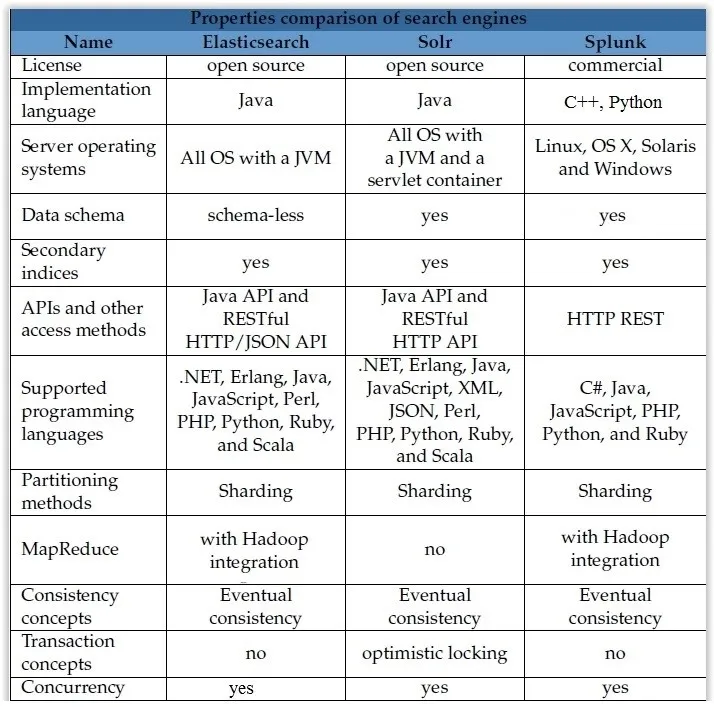
我一直在为.Net应用程序工作的Solr和Elasticsearch中进行研究。我发现最大的区别是:
Elasticsearch:
Solr:
想象一下这种使用场景:
在这种情况下,每个索引拥有独立的ES实例是一个巨大的开销。
根据我的经验,这种用例对于Elasticsearch来说非常难以支持。
为什么?
首先。
主要问题是基本的后向兼容性忽略。
破坏性变更非常酷! (注:想象一下SQL服务器,在升级时需要对所有SQL语句进行小的更改...无法想象。但对于ES来说,这是正常的)
下一个主要版本中将删除的弃用内容非常性感! (注:你知道,Java中包含一些弃用内容,20多年了,但仍然在实际Java版本中使用...)
有时你甚至会遇到一些没有文档的东西(个人只遇到过一次,但是...)
所以。如果您想升级ES(因为您需要一些应用程序的新功能或想要获得错误修复),那么您就陷入了困境。特别是如果涉及主要版本升级。
客户端API将不再向后兼容。索引设置也不再向后兼容。 同时升级所有应用程序/服务与ES升级不现实。
但是你必须做到时时刻刻。没有其他方法。
现有索引会自动升级吗?-是的。但当您需要更改某些旧索引设置时,它不会为您提供帮助。
要生存下来,您需要不断地投入大量力量来...使您的应用程序/服务与ES未来版本保持前向兼容性。 或者您需要构建(并且无论如何都需要不断支持)某种中间件来提供向后兼容的客户端API。 (而且,您不能使用Transport Client(因为每次ES的次要版本升级都需要jar升级),这个事实并没有让您的生活变得更简单)
它看起来简单且便宜吗?不,不是。远非如此。 基于ES的复杂基础设施的持续维护在所有可能的方面都太昂贵了。
其次。
简单API?嗯...不是真的。 当您实际使用复杂的条件和聚合时...带有5个嵌套级别的JSON请求无论如何都不简单。
很遗憾,我没有SOLR的经验,不能对其进行评价。
但是,在这种情况下,Sphinxsearch要好得多,因为它具有完全向后兼容的SphinxQL。
注意: Sphinxsearch/Manticore确实很有趣。它不基于Lucene,因此与其非常不同。它内置了一些ES没有的独特功能,并且在小/中型索引下非常快。我使用Elasticsearch已经有三年了,而Solr只用了一个月。我觉得相比于Solr的安装,Elasticsearch集群的安装要容易得多。Elasticsearch有一大批帮助文档,并且这些文档都解释得非常好。在某个使用案例中,我遇到了直方图聚合(Histogram Aggregation)这个问题,在Elasticsearch中可以找到对应的功能,但是在Solr中并没有。