好的,我现在明白你想做什么了...
也就是说,将标签和值标记为NA,而不删除底层导入的数据...
有关更详细的示例,请参见附录,其中使用公共数据文件展示了一个利用dplyr更新多个列、标签的示例...
建议的解决方案
df <- data_frame(s1 = c(1,2,2,2,5,6), s2 = c(1,2,2,2,5,6)) %>%
set_value_labels(s1 = c(agree=1, disagree=2, dk=5, refused=6),
s2 = c(agree=1, disagree=2, dk = tagged_na("5"), refused = tagged_na("6"))) %>%
set_na_values(s2 = c(5,6))
val_labels(df)
is.na(df$s1)
is.na(df$s2)
df
解决方案结果:
> library(haven)
> library(labelled)
> library(dplyr)
> df <- data_frame(s1 = c(1,2,2,2,5,6), s2 = c(1,2,2,2,5,6)) %>%
+ set_value_labels(s1 = c(agree=1, disagree=2, dk=5, refused=6),
+ s2 = c(agree=1, disagree=2, dk = tagged_na("5"), refused = tagged_na("6"))) %>%
+ set_na_values(s2 = c(5,6))
> val_labels(df)
$s1
agree disagree dk refused
1 2 5 6
$s2
agree disagree dk refused
1 2 NA NA
> is.na(df$s1)
[1] FALSE FALSE FALSE FALSE FALSE FALSE
> is.na(df$s2)
[1] FALSE FALSE FALSE FALSE TRUE TRUE
> df
s1 s2
<dbl+lbl> <dbl+lbl>
1 1 1
2 2 2
3 2 2
4 2 2
5 5 5
6 6 6
现在我们可以操作数据了
mean(df$s1, na.rm = TRUE)
mean(df$s2, na.rm = TRUE)
> mean(df$s1, na.rm = TRUE)
[1] 3
> mean(df$s2, na.rm = TRUE)
[1] 1.75
使用Labelled包去除标签并用R NA替换
如果您希望剥离标签并用R NA值替换,可以使用remove_labels(x, user_na_to_na = TRUE)
示例:
df <- remove_labels(df, user_na_to_na = TRUE)
df
结果:
> df <- remove_labels(df, user_na_to_na = TRUE)
> df
s1 s2
<dbl> <dbl>
1 1 1
2 2 2
3 2 2
4 2 2
5 5 NA
6 6 NA
SPSS格式的解释/概述:
IBM SPSS(应用程序)可以导入和导出许多格式和非矩形配置的数据;但是,数据集总是被转换为SPSS矩形数据文件,称为系统文件(使用扩展名*.sav)。元数据(关于数据的信息),如变量格式、缺失值和变量和值标签与数据集一起存储。
值标签
Base R 有一种数据类型,有效地维护整数和字符标签之间的映射:因子。然而,这不是因子的主要用途:它们设计用于自动生成线性模型的有用对比。因子在重要方面与其他工具提供的标记值不同:
SPSS 和 SAS 可以标记数字和字符值,而不仅仅是整数值。
缺失值
这三个工具(SPSS、SAS、Stata)都提供全局“系统缺失值”,显示为.。这大致相当于 R 的 NA,尽管 Stata 和 SAS 都不会在数字比较中传播缺失值:SAS 将缺失值视为最小可能的数字(即 -inf),而 Stata 将其视为最大可能的数字(即 inf)。
每个工具还提供了一种记录多种缺失类型的机制:
- Stata 有“扩展”缺失值,.A 到 .Z。
- SAS 有“特殊”缺失值,.A 到 .Z 加上 ._ 。
- SPSS 有每列的“用户”缺失值。每个列可以声明最多三个不同的值或一个值范围(加上一个不同的值),应将其视为缺失。
用户定义的缺失值
SPSS 的用户定义值与 SAS 和 Stata 不同。每一列可以有最多三个被视为缺失的不同值或一个范围。Haven 提供 labelled_spss() 作为 labelled() 的子类来模拟这些额外的用户定义缺失。
x1 <- labelled_spss(c(1:10, 99), c(Missing = 99), na_value = 99)
x2 <- labelled_spss(c(1:10, 99), c(Missing = 99), na_range = c(90, Inf))
x1
x2
标记缺失值
为了支持Stata的扩展和SAS的特殊缺失值,haven实现了一个标记NA。它利用浮点NA的内部结构来实现这一点。这使得这些值在常规R操作中的行为与NA相同,同时仍然保留标记的值。
创建带有标记的NA的R接口有点笨拙,因为通常它们将由haven为您创建。但是,您可以使用tagged_na()自己创建标记的NA:
重要提示:
请注意,这些标记的NA的行为与常规NA完全相同,即使在打印时也是如此。要查看它们的标记,请使用print_tagged_na():
因此:
library(haven)
library(labelled)
v1<-labelled(c(1,2,2,2,5,6), c(agree=1, disagree=2, dk=5, refused=6))
v2<-labelled(c(1,2,2,2,5,6), c(agree=1, disagree=2, dk=tagged_na("5"), refused= tagged_na("6")))
v3<-data.frame(v1 = v1, v2 = v2)
v3
lapply(v3, val_labels)
> v3
x x.1
1 1 1
2 2 2
3 2 2
4 2 2
5 5 5
6 6 6
> lapply(v3, val_labels)
$x
agree disagree dk refused
1 2 5 6
$x.1
agree disagree dk refused
1 2 NA NA
注意事项:
SPSS的自定义值与SAS和Stata不同。每个列可以有最多三个被视为缺失的不同值或一个范围。Haven提供了labelled_spss()作为labelled()的子类来模拟这些额外的用户定义的缺失。
希望以上内容对您有所帮助。
保重
T。
参考资料:
补充示例使用公共数据...
首先,让我们确保强调:
- 系统缺失值 - 是完全不存在于数据中的值
- 用户缺失值 - 是存在于数据中但必须从计算中排除的值。
SPSS数据查看...
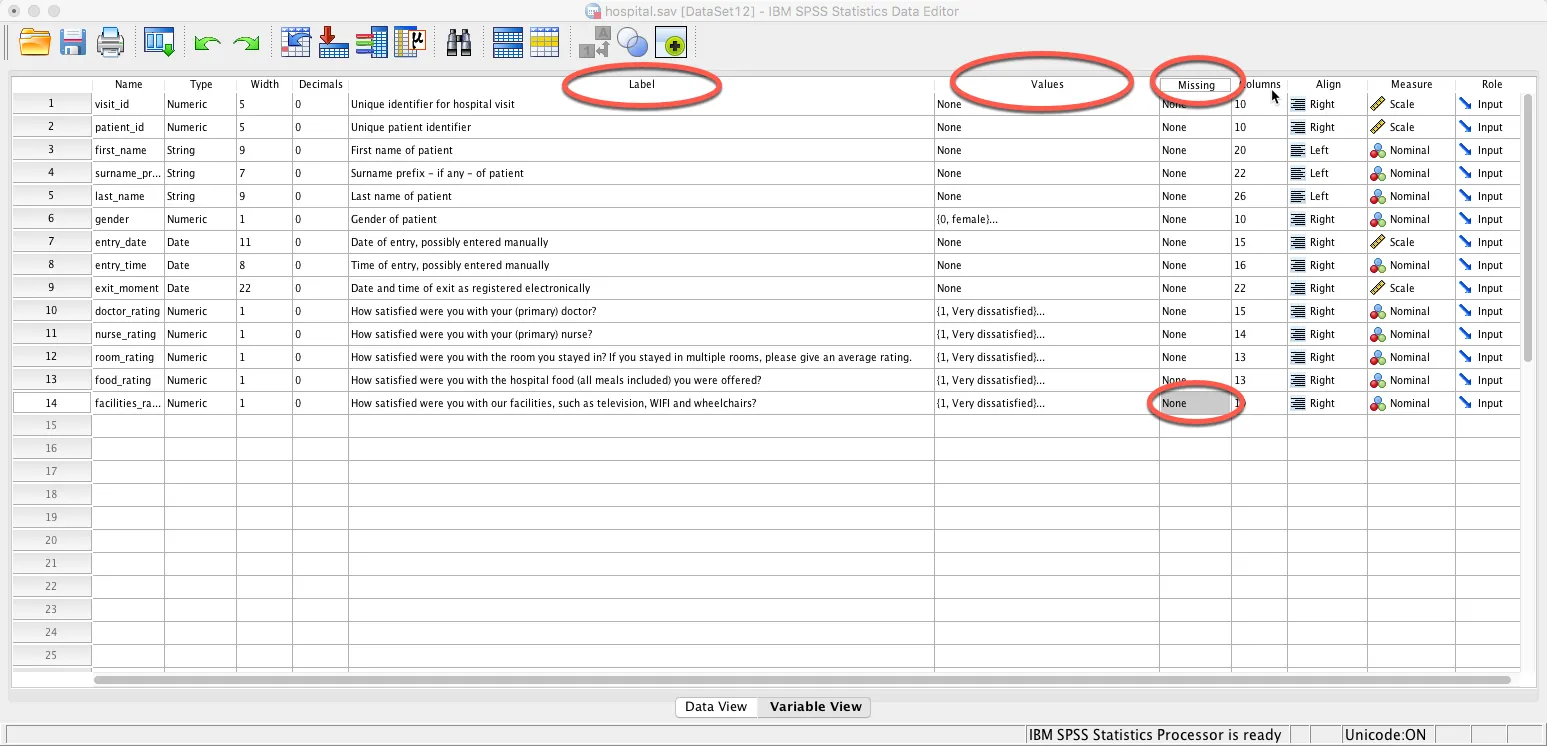
让我们查看图像和数据...在变量视图中显示的SPSS数据显示每行都有一个标签 [列5],我们注意到第10到14行有特定的值[1..6] [列6],这些值具有名称属性,并且没有指定任何值为缺失[列7]。
现在让我们看一下SPSS数据视图:
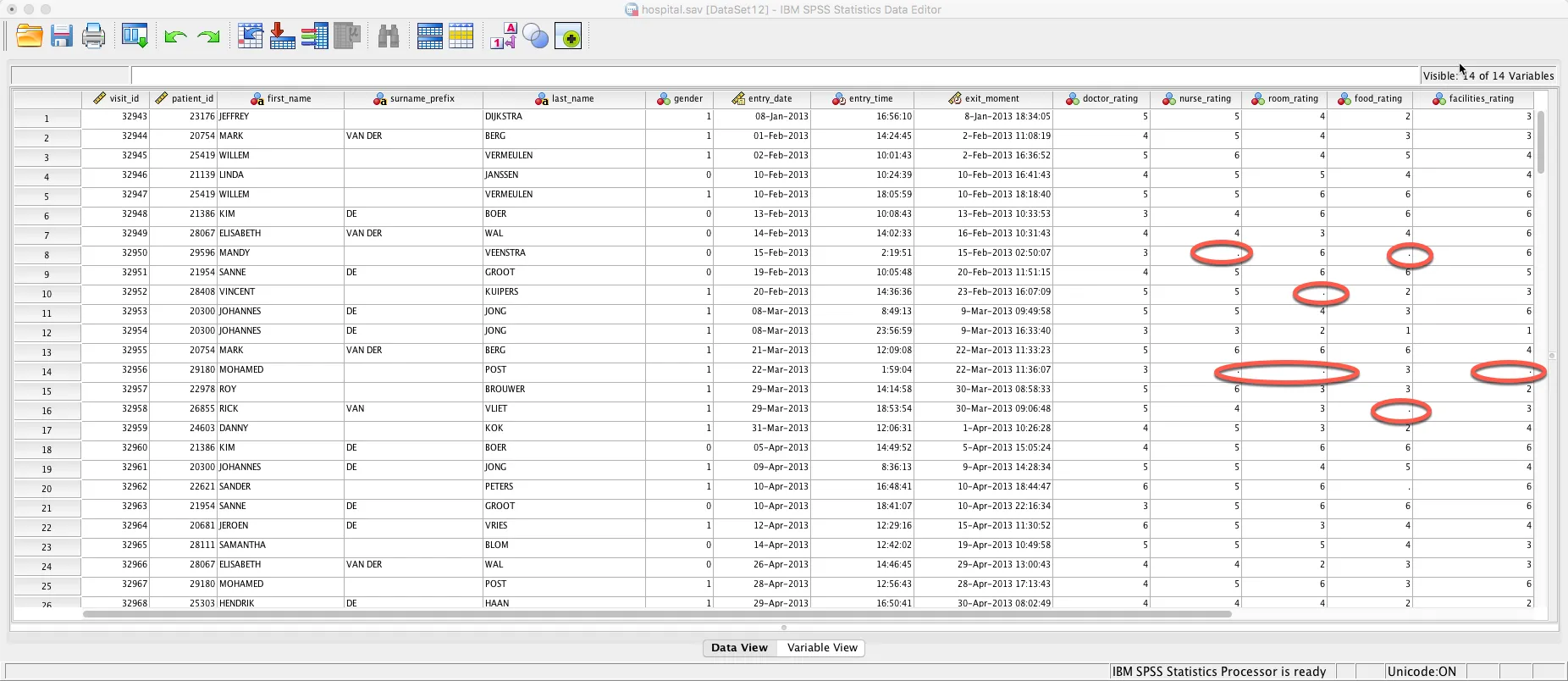
在这里,我们可以注意到有缺失数据...(请参见突出显示的“.”)。关键点是我们有缺失数据,但目前没有"缺失用户值"
现在让我们转向R,并将数据载入R
hospital_url <- "https://www.spss-tutorials.com/downloads/hospital.sav"
hospital <- read_sav(hospital_url,
user_na = FALSE)
head(hospital,5)
# We're interested in columns 10 through 14...
head(hospital[10:14],5)
结果
> hospital_url <- "https://www.spss-tutorials.com/downloads/hospital.sav"
> hospital <- read_sav(hospital_url,
+ user_na = FALSE)
> head(hospital,5)
visit_id patient_id first_name surname_prefix last_name gender entry_date entry_time
<dbl> <dbl> <chr> <chr> <chr> <dbl+lbl> <date> <time>
1 32943 23176 JEFFREY DIJKSTRA 1 2013-01-08 16:56:10
2 32944 20754 MARK VAN DER BERG 1 2013-02-01 14:24:45
3 32945 25419 WILLEM VERMEULEN 1 2013-02-02 10:01:43
4 32946 21139 LINDA JANSSEN 0 2013-02-10 10:24:39
5 32947 25419 WILLEM VERMEULEN 1 2013-02-10 18:05:59
第10到14列包含数值
1="Very Dissatisfied"
2="Dissatisfied"
3="Neutral"
4="Satisfied"
5="Very Satisfied"
6="Not applicable or don't want to answer"
因此:
> head(hospital[10:14],5)
# A tibble: 5 × 5
doctor_rating nurse_rating room_rating food_rating facilities_rating
<dbl+lbl> <dbl+lbl> <dbl+lbl> <dbl+lbl> <dbl+lbl>
1 5 5 4 2 3
2 4 5 4 3 3
3 5 6 4 5 4
4 4 5 5 4 4
5 5 5 6 6 6
SPSS取值标签
> lapply(hospital[10], val_labels)
$doctor_rating
Very dissatisfied Dissatisfied
1 2
Neutral Satisfied
3 4
Very satisfied Not applicable or don't want to answer
5 6
好的,请注意,以上我们可以确认已导入数值标签。
从调查数据中删除不适用的数据
我们的目标现在是将“不适用或不想回答”的数据条目设置为“用户NA值”,即SPSS缺失值,以便删除它们。
解决方案 - 第一步 - 单个列
我们希望在数据的多列上设置缺失值属性...让我们首先为一列执行此操作...
请注意,我们使用add_value_labels而不是set_value_labels,因为我们希望添加一个新标签,而不是完全覆盖现有标签...
d <- hospital
mean(d$doctor_rating, na.rm = TRUE)
d <- hospital %>%
add_value_labels( doctor_rating = c( "Not applicable or don't want to answer"
= tagged_na("6") )) %>%
set_na_values(doctor_rating = 5)
val_labels(d$doctor_rating)
mean(d$doctor_rating, na.rm = TRUE)
> d <- hospital
> mean(d$doctor_rating, na.rm = TRUE)
[1] 4.322368
> d <- hospital %>%
+ add_value_labels( doctor_rating = c( "Not applicable or don't want to answer"
+ = tagged_na("6") )) %>%
+ set_na_values(doctor_rating = 6)
> val_labels(d$doctor_rating)
Very dissatisfied Dissatisfied
1 2
Neutral Satisfied
3 4
Very satisfied Not applicable or don't want to answer
5 6
Not applicable or don't want to answer
NA
> mean(d$doctor_rating, na.rm = TRUE)
[1] 4.097015
解决方案 - 第二步 - 现在应用于多列...
mean(hospital$nurse_rating)
mean(hospital$nurse_rating, na.rm = TRUE)
d <- hospital %>%
add_value_labels( doctor_rating = c( "Not applicable or don't want to answer"
= tagged_na("6") )) %>%
set_na_values(doctor_rating = 6) %>%
add_value_labels( nurse_rating = c( "Not applicable or don't want to answer"
= tagged_na("6") )) %>%
set_na_values(nurse_rating = 6)
mean(d$nurse_rating, na.rm = TRUE)
结果
请注意,nurse_rating包含"NaN"值和NA标记的值。第一个mean()调用失败,第二个成功,但在过滤器之后包括"Not Applicable...",在移除"Not Applicable..."后...
> mean(hospital$nurse_rating)
[1] NaN
> mean(hospital$nurse_rating, na.rm = TRUE)
[1] 4.471429
> d <- hospital %>%
+ add_value_labels( doctor_rating = c( "Not applicable or don't want to answer"
+ = tagged_na("6") )) %>%
+ set_na_values(doctor_rating = 6) %>%
+ add_value_labels( nurse_rating = c( "Not applicable or don't want to answer"
+ = tagged_na("6") )) %>%
+ set_na_values(nurse_rating = 6)
> mean(d$nurse_rating, na.rm = TRUE)
[1] 4.341085
将标记的NA转换为R里的NA
在这里,我们将上述标记的NA转换为R中的NA值。
d <- d %>% remove_labels(user_na_to_na = TRUE)
dput(<structure>,"")提供一个示例,并将其添加到您的代码示例中。完整或子集都有帮助。注意:我更新了您发布的代码,“data_frame()”应更改为“data.frame()”。 - Technophobe01v3[] = lapply(v3, set_na_values, c(5, 6))不是你想要的吗? - Johan