假设我有两个非常相似的字符串。 我想找到另一个字符串,它在Levenshtein距离上接近s1和s2。
我需要这些变量:
import Levenshtein
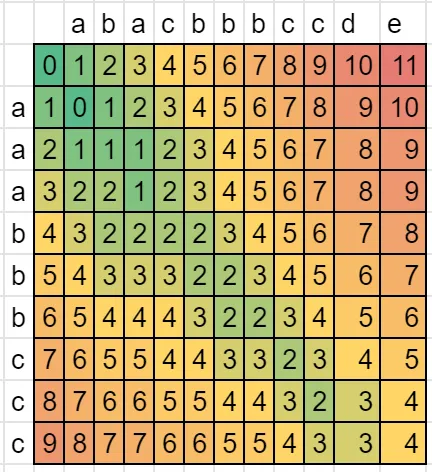
s1 = 'aaabbbccc'
s2 = 'abacbbbccde'
dist = Levenshtein.distance(s1, s2)
print(dist)
mid_str = get_avg_string(s1, s2)
如何有效实现函数:
def get_avg_string(s1, s2):
return ''
我需要这些变量:
sum_lev = Levenshtein.distance(s1, mid_str) + Levenshtein.distance(s2, mid_str)
diff_lev = abs(Levenshtein.distance(s1, mid_str) - Levenshtein.distance(s2, mid_str)
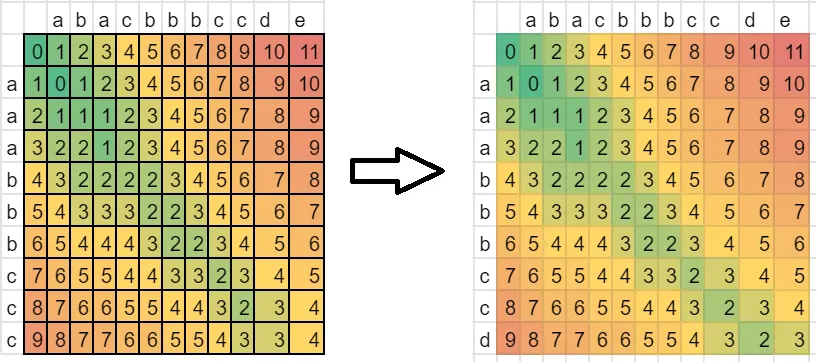
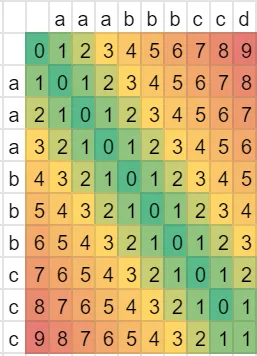
我认为应该保持简洁 (sum_lev 等于 dist,而且 diff_lev <= 1).
s1[:len(s1) // 2] + s2[len(s2) // 2:]是否能够近似满足该属性,还是您需要一个可证明的最小值? - Joe