我觉得我不理解多输出网络。
虽然我了解其实现方式,并且成功地训练了一个这样的模型,但我不理解多输出深度学习网络是如何训练的。我的意思是,在训练期间,网络内部会发生什么?
以keras functional api guide中的这个网络为例:
我的直觉是模型会进行两次反向传播,一次针对每个输出。然后,每个反向传播都会更新前面层的权重。 但事实并非如此:从here(SO)得到的信息表明,尽管有多个输出,但只有一个反向传播;使用的损失根据输出进行加权。
但仍然不清楚网络及其辅助分支如何训练;辅助分支的权重是如何更新的,因为它没有直接连接到主输出?在辅助分支的根部和主输出之间的网络部分是否受到损失加权的影响?还是加权只影响与辅助输出相连的网络部分?
虽然我了解其实现方式,并且成功地训练了一个这样的模型,但我不理解多输出深度学习网络是如何训练的。我的意思是,在训练期间,网络内部会发生什么?
以keras functional api guide中的这个网络为例:
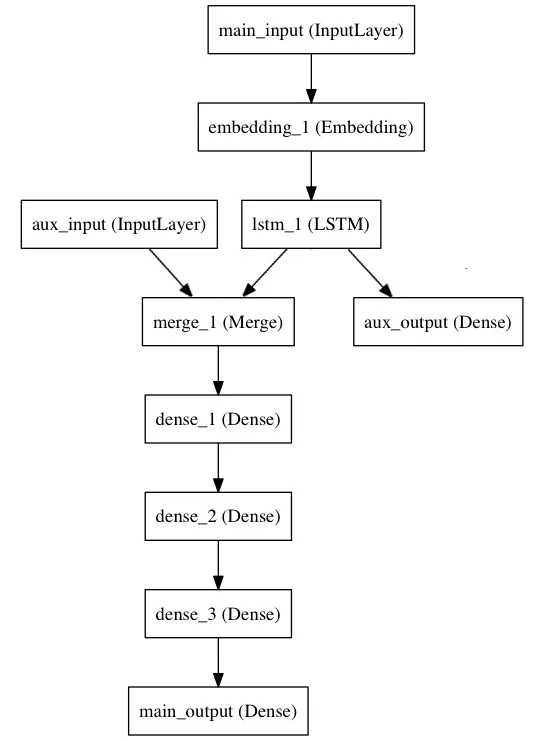
我的直觉是模型会进行两次反向传播,一次针对每个输出。然后,每个反向传播都会更新前面层的权重。 但事实并非如此:从here(SO)得到的信息表明,尽管有多个输出,但只有一个反向传播;使用的损失根据输出进行加权。
但仍然不清楚网络及其辅助分支如何训练;辅助分支的权重是如何更新的,因为它没有直接连接到主输出?在辅助分支的根部和主输出之间的网络部分是否受到损失加权的影响?还是加权只影响与辅助输出相连的网络部分?
另外,我正在寻找有关此主题的好文章。我已经阅读了有关GoogLeNet / Inception的文章(v1, v2-v3),因为这个网络使用辅助分支。