首先,让我们解决一些明显的问题 - foreground.isOpened() 即使在视频结束后也会返回 true,因此您的程序最终会崩溃。解决方案是双重的。首先,在创建所有 3 个 VideoCapture 实例后立即测试它们,使用类似以下内容的东西:
if not foreground.isOpened() or not background.isOpened() or not alpha.isOpened():
print "Unable to open input videos."
return
这将确保它们全部正确打开。接下来的部分是正确处理视频结束。这意味着要么检查read()的两个返回值中的第一个,它是表示成功的布尔标志,要么测试帧是否为None。
while True:
r_fg, fr_foreground = foreground.read()
r_bg, fr_background = background.read()
r_a, fr_alpha = alpha.read()
if not r_fg or not r_bg or not r_a:
break
此外,似乎您实际上没有调用
cv2.destroyAllWindows() -- 缺少
()。虽然这并不重要。
为了帮助调查和优化这个问题,我添加了一些详细的时间记录,使用了
timeit模块和一些方便的函数。
from timeit import default_timer as timer
def update_times(times, total_times):
for i in range(len(times) - 1):
total_times[i] += (times[i+1]-times[i]) * 1000
def print_times(total_times, n):
print "Iterations: %d" % n
for i in range(len(total_times)):
print "Step %d: %0.4f ms" % (i, total_times[i] / n)
print "Total: %0.4f ms" % (np.sum(total_times) / n)
我修改了
main()函数,以测量每个逻辑步骤所需的时间——读取、缩放、混合、显示、等待按键。为此,我将除法拆分为单独的语句。我还进行了轻微修改,使其在Python 2.x中也能正常工作(
/255被解释为整数除法并产生错误结果)。
times = [0.0] * 6
total_times = [0.0] * (len(times) - 1)
n = 0
while True:
times[0] = timer()
r_fg, fr_foreground = foreground.read()
r_bg, fr_background = background.read()
r_a, fr_alpha = alpha.read()
if not r_fg or not r_bg or not r_a:
break
times[1] = timer()
fr_foreground = fr_foreground / 255.0
fr_background = fr_background / 255.0
fr_alpha = fr_alpha / 255.0
times[2] = timer()
result = cmb(fr_foreground,fr_background,fr_alpha)
times[3] = timer()
cv2.imshow('My Image', result)
times[4] = timer()
if cv2.waitKey(1) == ord('q'): break
times[5] = timer()
update_times(times, total_times)
n += 1
print_times(total_times, n)
当我使用1280x800的mp4视频作为输入时,我发现它非常缓慢,并且在我的6核机器上仅使用15%的CPU。各部分的时间如下:
Iterations: 1190
Step 0: 11.4385 ms
Step 1: 37.1320 ms
Step 2: 39.4083 ms
Step 3: 2.5488 ms
Step 4: 10.7083 ms
Total: 101.2358 ms
这表明最大的瓶颈在于缩放步骤和混合步骤。低CPU使用率也不够理想,但让我们先专注于易于解决的问题。
让我们看一下我们使用的numpy数组的数据类型。read()给出的数组具有np.uint8的dtype - 8位无符号整数。然而,浮点除法(如所写)将产生一个具有np.float64的dtype的数组 - 64位浮点值。对于我们的算法,我们实际上不需要这种精度水平,因此最好只使用32位浮点数 - 这意味着如果任何操作是矢量化的,我们可以在相同的时间内潜在地进行两倍的计算。
这里有两个选项。我们可以简单地将除数强制转换为np.float32,这将导致numpy给出具有相同dtype的结果:
fr_foreground = fr_foreground / np.float32(255.0)
fr_background = fr_background / np.float32(255.0)
fr_alpha = fr_alpha / np.float32(255.0)
这给我们以下计时:
Iterations: 1786
Step 0: 9.2550 ms
Step 1: 19.0144 ms
Step 2: 21.2120 ms
Step 3: 1.4662 ms
Step 4: 10.8889 ms
Total: 61.8365 ms
或者我们可以先将数组转换为np.float32,然后在原地进行缩放。
fr_foreground = np.float32(fr_foreground)
fr_background = np.float32(fr_background)
fr_alpha = np.float32(fr_alpha)
fr_foreground /= 255.0
fr_background /= 255.0
fr_alpha /= 255.0
以下是时间(将步骤1分为转换(1)和缩放(2) - 其余移动1):
Iterations: 1786
Step 0: 9.0589 ms
Step 1: 13.9614 ms
Step 2: 4.5960 ms
Step 3: 20.9279 ms
Step 4: 1.4631 ms
Step 5: 10.4396 ms
Total: 60.4469 ms
两者大致相当,运行时间为原始时间的约60%。我会选择第二个选项,因为它在后续步骤中会变得有用。让我们看看还有什么可以改进。
从之前的时间测试中,我们可以看出缩放不再是瓶颈,但仍有一个想法浮现:除法通常比乘法慢,那么如果我们乘以倒数会怎样?
fr_foreground *= 1/255.0
fr_background *= 1/255.0
fr_alpha *= 1/255.0
实际上,这确实为我们节省了一毫秒时间——虽然没有什么惊人之处,但很容易实现,所以不妨采用它:
Iterations: 1786
Step 0: 9.1843 ms
Step 1: 14.2349 ms
Step 2: 3.5752 ms
Step 3: 21.0545 ms
Step 4: 1.4692 ms
Step 5: 10.6917 ms
Total: 60.2097 ms
现在混合函数是最大的瓶颈,其次是对所有3个数组的类型转换。如果我们看一下混合操作的作用:
foreground * alpha + background * (1.0 - alpha)
我们可以观察到,为了让数学运算起作用,唯一需要在范围(0.0,1.0)内的值是
alpha。
如果我们只缩放alpha图像呢?另外,由于浮点数乘法会提升为浮点数,如果我们也跳过类型转换会怎样?这意味着
cmb()将返回
np.uint8数组。
def cmb(fg,bg,a):
return np.uint8(fg * a + bg * (1-a))
我们会有
fr_alpha = np.float32(fr_alpha)
fr_alpha *= 1/255.0
这个的时间是
Step 0: 7.7023 ms
Step 1: 4.6758 ms
Step 2: 1.1061 ms
Step 3: 27.3188 ms
Step 4: 0.4783 ms
Step 5: 9.0027 ms
Total: 50.2840 ms
显然,步骤1和步骤2要快得多,因为我们只完成了1/3的工作。 imshow 也加速了,因为它不必从浮点数转换。出乎意料的是,读取速度也加快了(我猜我们避免了一些在幕后重新分配内存,因为 fr_foreground 和 fr_background 总是包含完好无损的帧)。我们在 cmb() 中付出了额外的转换代价,但总体而言这似乎是一种胜利——我们现在只需要原先时间的50%。
为了继续,让我们摆脱函数,将其功能移动到
main()并分割它以测量每个操作的成本。让我们也尝试重用
alpha.read()的结果(因为我们最近看到了
read()性能的提高):
times = [0.0] * 11
total_times = [0.0] * (len(times) - 1)
n = 0
while True:
times[0] = timer()
r_fg, fr_foreground = foreground.read()
r_bg, fr_background = background.read()
r_a, fr_alpha_raw = alpha.read()
if not r_fg or not r_bg or not r_a:
break
times[1] = timer()
fr_alpha = np.float32(fr_alpha_raw)
times[2] = timer()
fr_alpha *= 1/255.0
times[3] = timer()
fr_alpha_inv = 1.0 - fr_alpha
times[4] = timer()
fr_fg_weighed = fr_foreground * fr_alpha
times[5] = timer()
fr_bg_weighed = fr_background * fr_alpha_inv
times[6] = timer()
sum = fr_fg_weighed + fr_bg_weighed
times[7] = timer()
result = np.uint8(sum)
times[8] = timer()
cv2.imshow('My Image', result)
times[9] = timer()
if cv2.waitKey(1) == ord('q'): break
times[10] = timer()
update_times(times, total_times)
n += 1
新时间:
Iterations: 1786
Step 0: 6.8733 ms
Step 1: 5.2742 ms
Step 2: 1.1430 ms
Step 3: 4.5800 ms
Step 4: 7.0372 ms
Step 5: 7.0675 ms
Step 6: 5.3082 ms
Step 7: 2.6912 ms
Step 8: 0.4658 ms
Step 9: 9.6966 ms
Total: 50.1372 ms
我们没有真正获得任何东西,但读取速度明显加快了。
这引出了另一个想法——如果我们尝试最小化分配并在后续迭代中重复使用数组会怎样?
我们可以在第一次迭代中预先分配必要的数组(使用
numpy.zeros_like),在读取第一组帧后:
if n == 0:
fr_alpha = np.zeros_like(fr_alpha_raw, np.float32)
fr_alpha_inv = np.zeros_like(fr_alpha_raw, np.float32)
fr_fg_weighed = np.zeros_like(fr_alpha_raw, np.float32)
fr_bg_weighed = np.zeros_like(fr_alpha_raw, np.float32)
sum = np.zeros_like(fr_alpha_raw, np.float32)
result = np.zeros_like(fr_alpha_raw, np.uint8)
现在,我们可以使用以下函数:
我们还可以将步骤1和2合并为一个单一的
numpy.multiply。
times = [0.0] * 10
total_times = [0.0] * (len(times) - 1)
n = 0
while True:
times[0] = timer()
r_fg, fr_foreground = foreground.read()
r_bg, fr_background = background.read()
r_a, fr_alpha_raw = alpha.read()
if not r_fg or not r_bg or not r_a:
break
if n == 0:
fr_alpha = np.zeros_like(fr_alpha_raw, np.float32)
fr_alpha_inv = np.zeros_like(fr_alpha_raw, np.float32)
fr_fg_weighed = np.zeros_like(fr_alpha_raw, np.float32)
fr_bg_weighed = np.zeros_like(fr_alpha_raw, np.float32)
sum = np.zeros_like(fr_alpha_raw, np.float32)
result = np.zeros_like(fr_alpha_raw, np.uint8)
times[1] = timer()
np.multiply(fr_alpha_raw, np.float32(1/255.0), fr_alpha)
times[2] = timer()
np.subtract(1.0, fr_alpha, fr_alpha_inv)
times[3] = timer()
np.multiply(fr_foreground, fr_alpha, fr_fg_weighed)
times[4] = timer()
np.multiply(fr_background, fr_alpha_inv, fr_bg_weighed)
times[5] = timer()
np.add(fr_fg_weighed, fr_bg_weighed, sum)
times[6] = timer()
np.copyto(result, sum, 'unsafe')
times[7] = timer()
cv2.imshow('My Image', result)
times[8] = timer()
if cv2.waitKey(1) == ord('q'): break
times[9] = timer()
update_times(times, total_times)
n += 1
这给我们以下时间:
Iterations: 1786
Step 0: 7.0515 ms
Step 1: 3.8839 ms
Step 2: 1.9080 ms
Step 3: 4.5198 ms
Step 4: 4.3871 ms
Step 5: 2.7576 ms
Step 6: 1.9273 ms
Step 7: 0.4382 ms
Step 8: 7.2340 ms
Total: 34.1074 ms
我们在所有修改的步骤中都取得了显著的改进。现在,我们所需时间仅为原始实现所需时间的约35%。
小更新:
根据Silencer的回答,我也测量了cv2.convertScaleAbs。实际上它运行得更快:
Step 6: 1.2318 ms
这给了我另一个想法——我们可以利用cv2.add,它允许我们指定目标数据类型并进行饱和转换。这将使我们能够将步骤5和6合并在一起。
cv2.add(fr_fg_weighed, fr_bg_weighed, result, dtype=cv2.CV_8UC3)
这是输出结果
Step 5: 3.3621 ms
我们又获得了一点胜利(之前我们大约是3.9毫秒)。
接下来,cv2.subtract 和 cv2.multiply 是更进一步的候选项。我们需要使用一个四元组来定义标量(这是Python绑定的复杂性),并且我们需要明确定义乘法的输出数据类型。
cv2.subtract((1.0, 1.0, 1.0, 0.0), fr_alpha, fr_alpha_inv)
cv2.multiply(fr_foreground, fr_alpha, fr_fg_weighed, dtype=cv2.CV_32FC3)
cv2.multiply(fr_background, fr_alpha_inv, fr_bg_weighed, dtype=cv2.CV_32FC3)
时间:
Step 2: 2.1897 ms
Step 3: 2.8981 ms
Step 4: 2.9066 ms
这似乎是我们在没有一些并行化的情况下所能达到的最远程度。我们已经利用了OpenCV在个别操作方面提供的优势,因此我们应该专注于将我们的实现进行管道化。
为了帮助我确定如何在不同的管道阶段(线程)之间划分代码,我制作了一张图表,显示了所有操作、我们的最佳时间以及计算的相互依赖关系:
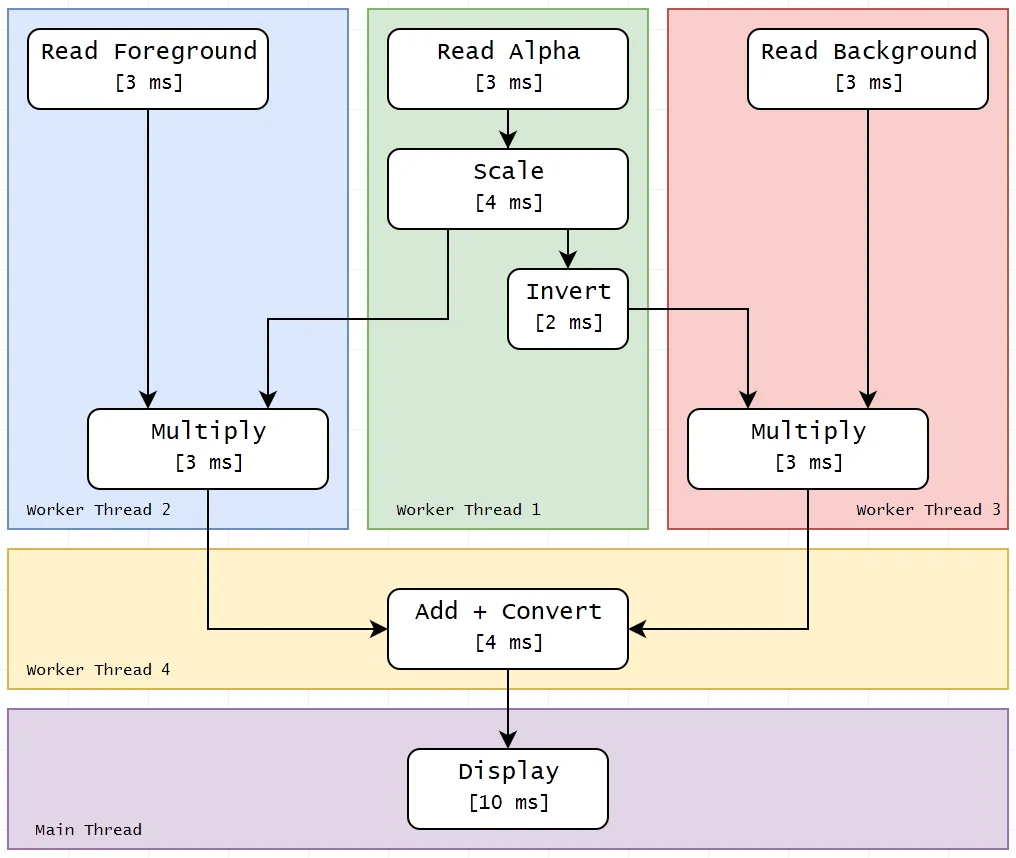
正在进行中,请查看注释获取更多信息,同时我会将其撰写出来。