http://geeksforgeeks.org/?p=6358
有人可以解释一下为什么莫里斯遍历的时间复杂度是o(n)吗?在这种遍历中,每当节点有一个左子节点时,它的前驱节点会被复制到其右子节点中。所以最坏情况是需要为每个节点找到前驱节点。
while(pre->right != NULL && pre->right != current)
pre = pre->right;
哪个会增加时间复杂度? 我是否有遗漏什么?
http://geeksforgeeks.org/?p=6358
有人可以解释一下为什么莫里斯遍历的时间复杂度是o(n)吗?在这种遍历中,每当节点有一个左子节点时,它的前驱节点会被复制到其右子节点中。所以最坏情况是需要为每个节点找到前驱节点。
while(pre->right != NULL && pre->right != current)
pre = pre->right;
哪个会增加时间复杂度? 我是否有遗漏什么?
原始的 Morris 遍历论文为Traversing binary trees simply and cheaply。在介绍部分它声称时间复杂度为 O(n):
它也很高效,花费的时间与树中节点的数量成比例,并且不需要运行时堆栈或节点中的'标志'位。
完整的论文应该对时间复杂度进行分析。但是完整论文无法免费访问。
Morris Traversal方法遍历二叉树(非递归,不用栈,O(1)空间)进行了一些分析。我已经翻译了一些相关部分并根据我的理解做出了一些更正。以下是我的理解:
一棵具有n个节点的二叉树有n-1条边。在Morris遍历中,一条边最多被访问3次。第一次访问是为了找到一个节点,第二次访问是为了查找某个节点的前驱节点,而第三次/最后一次是为了将前驱节点的右孩子恢复为null。在下面的二叉树中,红色虚线用于定位一个节点(第一次访问)。黑色虚线用于查找前驱节点(两次遍历:第二次访问和第三次访问)。当查找节点H的前驱节点时,节点F也会被访问。最后,当将节点G(H的前驱)的右孩子恢复为null时,节点F也会被访问。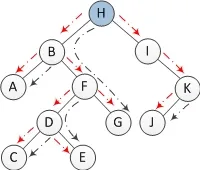
这不会增加复杂度,因为该算法仅在一个方向上重建树(重建仅需O(n),之后再打印需要O(n)...但他们将两个功能合并到同一个函数中,并为算法赋予了特殊名称,就这样。
[1, 2, 3, 4, 5, ..., 43] 中,节点 5 将被访问4次。 - qqqqqqq当前节点被访问。
如果一个节点有左子节点,则 current 会访问两次,否则访问一次。
建立循环并销毁循环。
如果一个节点在循环中,则被访问两次,否则为零。
A + B 表示访问次数,其中 A 是 current,B 是循环。
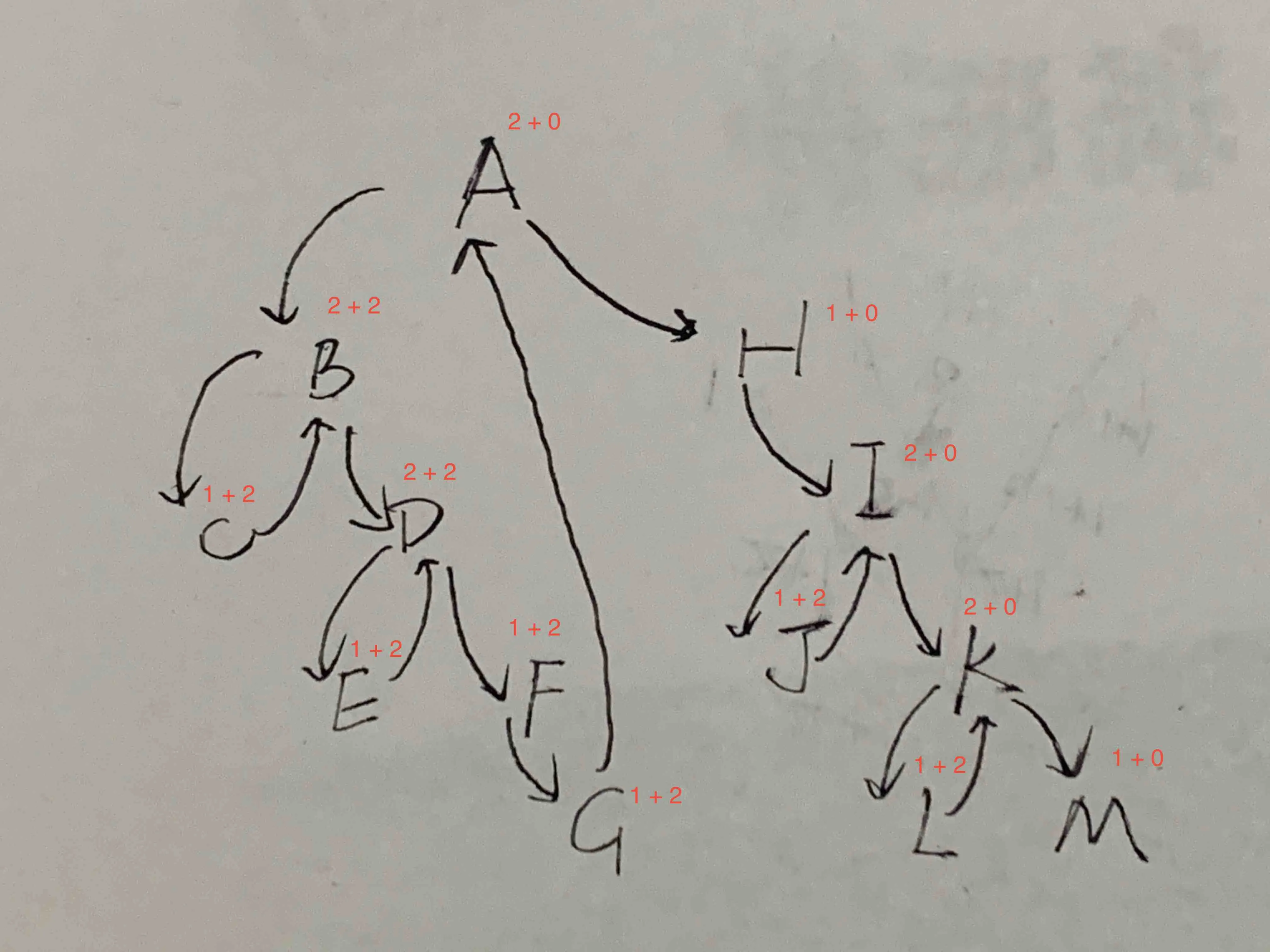
对于节点D,current从B移动到D,并且从E移动到D。节点D也在循环A B D F G中,当current从A移动到B(建立循环)以及从A移动到H(破坏循环)时,访问了节点D。因此,节点D被访问了2 + 2 = 4次。
首先,我需要更正一下您所说的内容:
在遍历过程中,每当节点拥有左子节点时,会将其复制到其前任的右子节点上
不是将当前节点复制到其前任的右子节点上 - 当前节点的前任的右子节点指向当前节点 - 指针并不会创建任何副本;相反,它只是指向已经存在的当前节点。
现在回答您有关代码片段的问题:
while(pre->right != NULL && pre->right != current)
pre = pre->right;
现在,即使在上面我似乎在暗示整个算法的运行时间为2n,实际上并不是这样——它实际上是3n。
顺便说一下,我认为从完整算法中移除旧的“线程”引用的这行代码并不是严格必要的(尽管它没有影响,可以考虑做一些整理):
pre->right = NULL;
pre->right = NULL;- cellepo