我知道CQRS可以使用或不使用事件溯源来实现,但反过来行不行?没有CQRS的事件溯源是否有意义?如果有的话,应该如何实现?
无 CQRS 的事件溯源
14
- k13i
5个回答
14
没错,确实如此。
基本上,事件溯源的整个思想就是存储导致当前状态的更改,而不是存储当前状态。这样,使用事件溯源,您自动拥有历史记录,并且可以在数据上运行时间序列分析,并尝试从过去中学习。
是否使用CQRS是完全不同的故事:CQRS是关于将应用程序的写入与读取分离。
就像您可以在没有事件溯源的情况下使用CQRS一样,您也可以在没有CQRS的情况下使用事件溯源。两者互相独立,只是偶然很适合彼此。
- Golo Roden
1
2如果提供一个没有CQRS的事件溯源示例,这个答案将会得到很大的改善。正如@coderbyheart在他的回答中所说,如果你没有保留一个单独的读取端,那么你就必须直接从事件存储中读取,而这很快就变得不切实际了。因此,实际上,事件溯源似乎确实需要CQRS。 - TheRubberDuck
8
CQRS 是指将读操作和写操作分离。写操作需要使用锁定、保证顺序和始终保持最新状态等特性。在传统系统(如关系型数据库)中,您也会将这些保证应用于读操作,这会对性能产生巨大影响,并在可扩展性方面存在很大问题。因此,在 CQRS 中,您为读操作提供了一个数据的单独副本,该副本针对快速读取进行了优化,例如将其非规范化并放入更有效、更快的系统中(例如内存缓存),我称之为“系统数据的读视图”。
CQRS 可以不用事件溯源(ES)实现,因为可以从传统的数据存储(如关系型数据库)中创建优化的读取视图。
ES 也可以不用 CQRS 实现,但前提是事件数量相对较少。因为您将系统的所有更改都存储在数据库中,每次读取都必须使用同一数据库并迭代需要满足查询的所有事件。最终,需要读取的事件过多,以至于回答所需的时间变得太长。
CQRS 可以不用事件溯源(ES)实现,因为可以从传统的数据存储(如关系型数据库)中创建优化的读取视图。
ES 也可以不用 CQRS 实现,但前提是事件数量相对较少。因为您将系统的所有更改都存储在数据库中,每次读取都必须使用同一数据库并迭代需要满足查询的所有事件。最终,需要读取的事件过多,以至于回答所需的时间变得太长。
- coderbyheart
2
我还没有见过使用ES而不使用CQRS的情况,因为这只有在您不需要跨多个实体进行任何查询/分析能力时才会发生。99%的情况下,这是一个要求;)
如果您想要跨多个实体进行查询,则一定需要类似于CQRS的东西,因为您将应用一种不同的查询数据方式,而不是使用事件源。 (除非您每次查询都想重新播放所有事件..)如何实现CQRS部分并不是固定不变的。它只是描述了读取和写入是以不同方式处理的两个独立问题。
因此,总体而言:不,这没有任何意义。
- Vincent Hendriks
2
没有使用CQRS的事件溯源有意义吗?
是的,从某种意义上说,CQRS和事件溯源是正交的问题。
就像罐子上写的那样-你有一个模型来管理历史记录,既可以响应命令对历史记录进行更新,也可以根据历史记录构建查询的响应。
class BankAccount {
final History<Transactions> transactions;
void deposit(Money money) {...}
Money computeInterestAccruedSince(Date lastReview) { ... }
}
- VoiceOfUnreason
0
是的,事件溯源可以在不使用CQRS的情况下使用(正如现有的答案已经指出的那样),但当达到一定的复杂程度时,实现写操作(事件、日志等)与读操作(投影、视图等)的分离似乎是自然而然的需求。
偶然间看到了这篇文章The Log: What every software engineer should know about real-time data's unifying abstraction,虽然它是关于事件驱动的分布式系统,但人们很容易找到其中描述的概念与CQRS + 事件溯源之间的相似之处。这是一篇长而深入的文章,但值得一读。
引用来自“日志在系统架构中的位置”部分最相关的内容:
这是如何工作的。系统分为两个逻辑部分:日志和服务层。日志按顺序记录状态变化。服务节点存储用于查询的索引(例如,键值存储可能有类似B树或SSTable的结构,搜索系统可能有倒排索引)。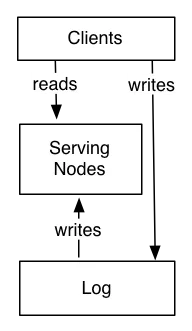
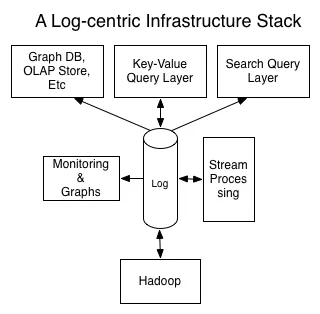
只是与主题有些关联,但在阅读了《The Log》一文后,我立即开始研究如何将其描述的概念与CQRS和事件溯源联系起来,以及为什么(几乎)没有人推荐Kafka作为事件存储。在我看来,这个答案是最好的,其中引入的术语感觉被低估了(例如,“下游事件处理”和“应用程序控制的真相来源”)。
- toraritte
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接