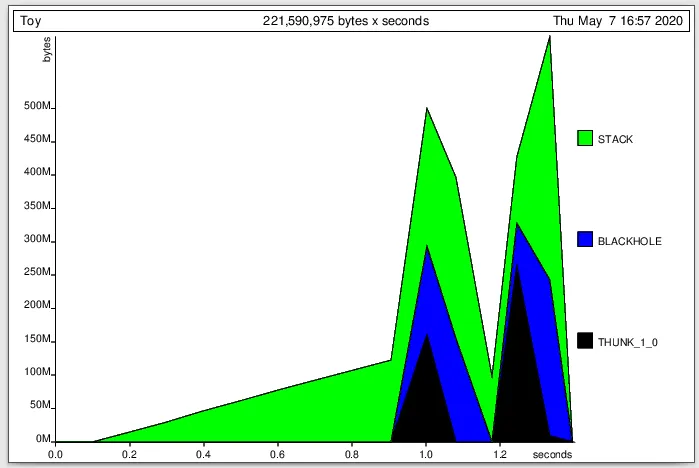
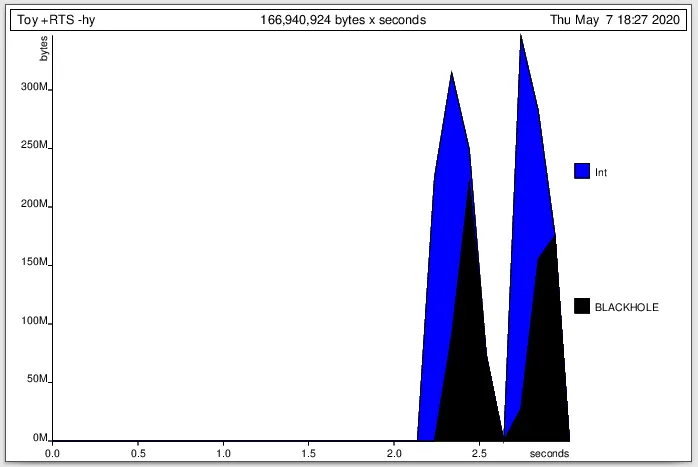
经过几个小时的调试,我意识到一个非常简单的玩具例子由于表达式
那么我的问题是:是否有一种自动检测这些“懒惰内存泄漏”的方法,这些泄漏没有真正原因而导致程序变慢?我还不太擅长优化Haskell代码,即使你很有经验,在忘记了
我知道:
-
例如,您能否向我解释一下如何在像这个例子这样的玩具程序中找到“懒惰泄漏”?
return $ 1 + x 中缺少一个 ! 是不高效的(感谢duplode!但是为什么ghc不优化它?)。我之所以意识到这一点,是因为我正在将其与一个更快的Python代码进行比较,但我不会总是编写Python代码来测试我的代码...那么我的问题是:是否有一种自动检测这些“懒惰内存泄漏”的方法,这些泄漏没有真正原因而导致程序变慢?我还不太擅长优化Haskell代码,即使你很有经验,在忘记了
! 的情况下,很可能出现这种情况。我知道:
-
+RTS -s 命令,但我不确定如何解释它:例如对于一个简单的程序,看到79MB的内存似乎对我来说太大了,但也许它正是我的当前程序所需要的。 对于更大的程序来说,只是通过这种方式检测“懒惰泄漏”是不可能的,因为我不知道程序应该占用多少内存。
- cabal v2-run --enable-profiling mysatsolvers -- +RTS -p 命令,但似乎启用分析器会破坏GHC做的一些优化,因此很难将这些值用于实际基准测试。而且,对我来说仍然不清楚如何从输出中找到泄漏。例如,您能否向我解释一下如何在像这个例子这样的玩具程序中找到“懒惰泄漏”?
{-# LANGUAGE DerivingVia, FlexibleInstances, ScopedTypeVariables #-}
module Main where
--- It depends on the transformers, containers, and base packages.
--- Optimisation seems to be important or the NoLog case will be way to long.
--- $ ghc -O Main.hs
import qualified Data.Map.Strict as MapStrict
import Data.Functor.Identity
import qualified Control.Monad as CM
import qualified Control.Monad.State.Strict as State
import qualified Data.Time as Time
-- Create a class that allows me to use the function "myTell"
-- that adds a number in the writer (either the LogEntry
-- or StupidLogEntry one)
class Monad m => LogFunctionCalls m where
myTell :: String -> Int -> m ()
---------- Logging disabled ----------
--- (No logging at all gives the same time so I don't put here)
newtype NoLog a = NoLog { unNoLog :: a }
deriving (Functor, Applicative, Monad) via Identity
instance LogFunctionCalls NoLog where
myTell _ _ = pure ()
---------- Logging with Map ----------
-- When logging, associate a number to each name.
newtype LogEntryMap = LogEntryMap (MapStrict.Map String Int)
deriving (Eq, Show)
instance LogFunctionCalls (State.State LogEntryMap) where
myTell namefunction n = State.modify' $
\(LogEntryMap m) ->
LogEntryMap $ MapStrict.insertWith (+) namefunction n m
---------- Logging with Int ----------
-- Don't use any Map to avoid inefficiency of Map
newtype LogEntryInt = LogEntryInt Int
deriving (Eq, Show)
instance LogFunctionCalls (State.State LogEntryInt) where
myTell namefunction n = State.modify' $
\(LogEntryInt m) -> LogEntryInt $! m + n
---------- Function to compute ----------
countNumberCalls :: (LogFunctionCalls m) => Int -> m Int
countNumberCalls 0 = return 0
countNumberCalls n = do
myTell "countNumberCalls" 1
x <- countNumberCalls $! n - 1
return $ 1 + x
main :: IO ()
main = do
let www = 15000000
putStrLn $ "Let's start!"
--- Logging disabled
t0 <- Time.getCurrentTime
let n = unNoLog $ countNumberCalls www
putStrLn $ "Logging disabled: " ++ (show n)
t1 <- Time.getCurrentTime
print (Time.diffUTCTime t1 t0)
-- Logging with Map
let (n, LogEntryMap log) = State.runState (countNumberCalls www) (LogEntryMap MapStrict.empty)
putStrLn $ "Logging with Map: " ++ (show n)
putStrLn $ (show $ log)
t2 <- Time.getCurrentTime
print (Time.diffUTCTime t2 t1)
-- Logging with Int
let (n, LogEntryInt log) = State.runState (countNumberCalls www) (LogEntryInt 0)
putStrLn $ "Logging with Int: " ++ (show n)
putStrLn $ (show $ log)
t3 <- Time.getCurrentTime
print (Time.diffUTCTime t3 t2)