我会在这种任务中使用生成器,因为它避免了逐步构建结果列表,并且如果需要,可以懒惰地使用它:
def gen(iterable):
iterable = iter(iterable)
try:
last_seen = next(iterable)
except StopIteration:
return
count = 1
for item in iterable:
if item == last_seen:
count += 1
else:
yield from range(count, 0, -1)
count = 1
last_seen = item
yield from range(count, 0, -1)
这也适用于无法
反转输入的情况(某些生成器/迭代器无法反转):
>>> x_list = (i for i in range(10)) # it's a generator despite the variable name :-)
>>> ... arans solution ...
TypeError: 'generator' object is not reversible
>>> list(gen((i for i in range(10))))
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
它适用于你的输入:
>>> x_list = [1, 1, 2, 3, 3, 3]
>>> list(gen(x_list))
[2, 1, 1, 3, 2, 1]
使用itertools.groupby可以更简单地实现:
import itertools
def gen(iterable):
for _, group in itertools.groupby(iterable):
length = sum(1 for _ in group)
yield from range(length, 0, -1)
>>> x_list = [1, 1, 2, 3, 3, 3]
>>> list(gen(x_list))
[2, 1, 1, 3, 2, 1]
我还进行了一些基准测试,根据这些测试,Aran-Feys的解决方案是最快的,除了长列表,piRSquared的解决方案获胜:
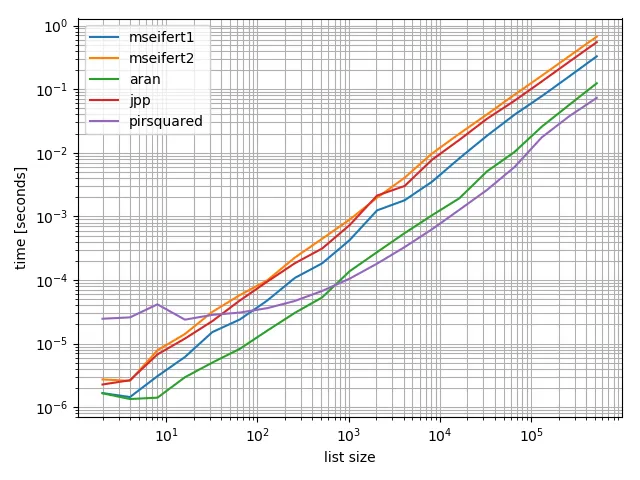
如果您想确认结果,这是我的基准测试设置:
from itertools import groupby, chain
import numpy as np
def gen1(iterable):
iterable = iter(iterable)
try:
last_seen = next(iterable)
except StopIteration:
return
count = 1
for item in iterable:
if item == last_seen:
count += 1
else:
yield from range(count, 0, -1)
count = 1
last_seen = item
yield from range(count, 0, -1)
def gen2(iterable):
for _, group in groupby(iterable):
length = sum(1 for _ in group)
yield from range(length, 0, -1)
def mseifert1(iterable):
return list(gen1(iterable))
def mseifert2(iterable):
return list(gen2(iterable))
def aran(x_list):
last_num = None
result = []
for num in reversed(x_list):
if num != last_num:
counter = 1
last_num = num
else:
counter += 1
result.append(counter)
return list(reversed(result))
def jpp(x_list):
gen = (range(len(list(j)), 0, -1) for _, j in groupby(x_list))
res = list(chain.from_iterable(gen))
return res
def cumcount(a):
a = np.asarray(a)
b = np.append(False, a[:-1] != a[1:])
c = b.cumsum()
r = np.arange(len(a))
return r - np.append(0, np.flatnonzero(b))[c] + 1
def pirsquared(x_list):
a = np.array(x_list)
return cumcount(a[::-1])[::-1]
from simple_benchmark import benchmark
import random
funcs = [mseifert1, mseifert2, aran, jpp, pirsquared]
args = {2**i: [random.randint(0, 5) for _ in range(2**i)] for i in range(1, 20)}
bench = benchmark(funcs, args, "list size")
%matplotlib notebook
bench.plot()
Python 3.6.5, NumPy 1.14
x_list。您注意到任何明显的模式了吗? :) 建议翻译:“提示:尝试反向遍历x_list。您是否注意到任何清晰的模式? :)” - k_ssb