我已经测试了提出的两个解决方案和其他两个。我无法测试onemasse的建议,因为保存到s[]的结果不正确。我也无法修复它。我不得不对moonshadow的代码进行一些更改。测量单位是时钟周期,所以数值越低越好。
原始代码:
#define MAX 100
void inline STACKO ( struct timespec *ts, struct timespec *te ){
int i, *s, *a, *b;
for (i = 0; i < MAX; ++i){
s = (int *) malloc (sizeof (int)); ++s;
a = (int *) malloc (sizeof (int)); ++a;
b = (int *) malloc (sizeof (int)); ++b;
}
srand ( 1024 );
for (i = 0; i < MAX; ++i){
a[i] = ( rand() % 2 );
b[i] = ( rand() % 2 );
}
rdtscb_getticks ( ts );
for (i = 0; i < MAX; i++)
s[i] = a[i] ^ b[i];
rdtscb_getticks ( te );
}
新提案1:注册int
来自:
int i, *s, *a, *b;
至:
register int i, *s, *a, *b;
新提案2:不使用数组表示法。
s_end = &s[MAX];
for (s_ptr = &s[0], a_ptr = &a[0], b_ptr = &b[0]; \
s_ptr < s_end; \
++s_ptr, ++a_ptr, ++b_ptr){
*s_ptr = *a_ptr ^ *b_ptr;
}
月影提出的优化建议:
s_ptr = &s[0];
a_ptr = &a[0];
b_ptr = &b[0];
for (i = 0; i < (MAX/4); i++){
s_ptr[0] = a_ptr[0] ^ b_ptr[0];
s_ptr[1] = a_ptr[1] ^ b_ptr[1];
s_ptr[2] = a_ptr[2] ^ b_ptr[2];
s_ptr[3] = a_ptr[3] ^ b_ptr[3];
s_ptr+=4; a_ptr+=4; b_ptr+=4;
}
月影提出优化+寄存器int:
来自:
int i, *s, ...
至:
register int i, *s, ...
Christoffer提出了优化方案:
#pragma omp for
for (i = 0; i < MAX; i++)
{
s[i] = a[i] ^ b[i];
}
结果:
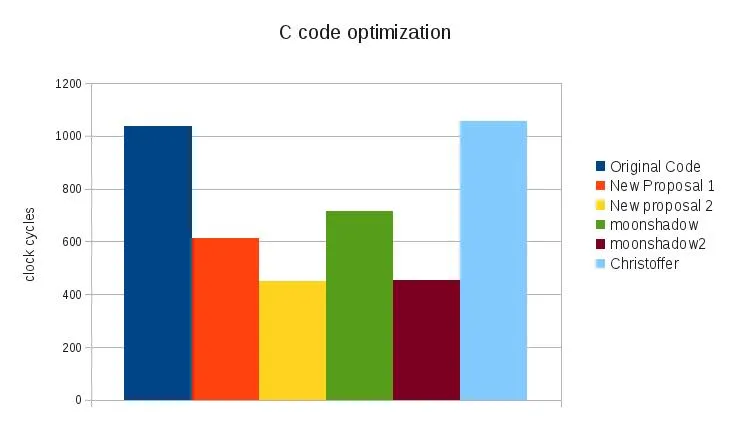
Original Code 1036.727264
New Proposal 1 611.147928
New proposal 2 450.788845
moonshadow 713.3845
moonshadow2 452.481192
Christoffer 1054.321943
另外一种优化生成的二进制文件的简单方法是向 gcc 传递 -O2。这会告诉 gcc 你想要进行优化。如果想要了解 -O2 的具体作用,请参考 gcc 的 man 手册。
启用 -O2 后,如下图所示性能会得到提升:
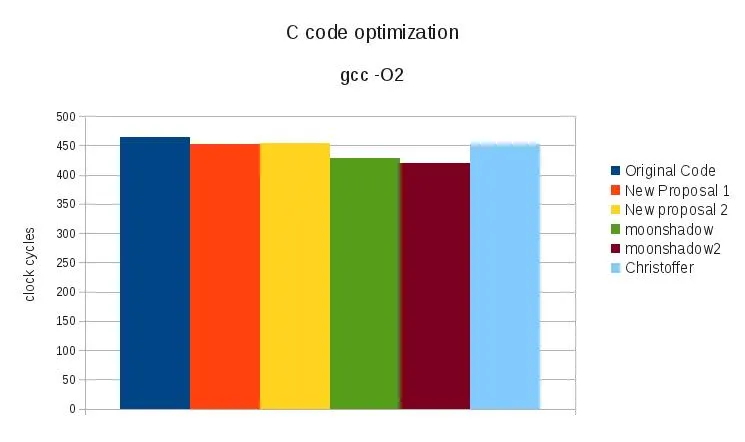
Original Code 464.233031
New Proposal 1 452.620255
New proposal 2 454.519383
moonshadow 428.651083
moonshadow2 419.317444
Christoffer 452.079057
源代码可在以下网址获取:
http://goo.gl/ud52m。
s是什么?为什么它是局部的?如果函数只是填充一个局部数组,那么它实际上并不会做任何事情,因此最好的优化方式就是完全删除它。如果函数没有返回任何东西,为什么你的函数要是int类型的?你用这个函数做什么?你需要给我们更多的信息。 - IVlads,但立即将其丢弃并泄漏了分配的内存。因此,最好的优化可能是int func(int *a, int *b) { (void)a; (void)b; }。 - lijie